
Data Structure : (1) Analysis
Data Structure: Analysis
Data Structure : 알고리즘의 성능 분석

사진출처:AIHR
과학과 기술은 시간이 갈수록 기하급수적으로 방대해지고, 발전에 발전을 거듭하게 된다.
이는 어떠한 기술이 생겨나고, upgrade 될수록 그것을 바탕으로 또 다른 길이 열릴 수 있기 때문이다.
이와 마찬가지로 컴퓨터 공학도 시간이 흐를수록 큰 변화가 생겨 이전 단계와는 이질적으로 Upgrade 되는 것을 우리는 실생활에서 느낄 수 있다.
엄청난 계산 속도와 메모리를 가진 요즘의 컴퓨터들은 ChatGPT와 같은 AI기술과 함께 인류에게 새로운 길을 열어 주었다.
이와 같이 급격한 시대의 흐름 속에서 우리는가장 이상적인 알고리즘을 설계하는 것에
대부분의 시간을 사용하며 개발해왔다.이유는 Limited Resources (한정된 컴퓨터 자원). 컴퓨터의 자원(CPU, Memory...etc)이 한정되어 있기 때문이다.
- 그렇다면, 풍부한 Resources 를 손에 넣은 우리는,
더 이상 알고리즘과 프로그램의 효율성 등은 신경쓰지 않아도 되는가?
나는 "NO" 라고 생각한다. (정답은 아무도 모른다.)
"이유는?"
급격한 과학기술의 발전 속에서 그것에 순전히 의지만 하는 행위는 "안주" 라고 생각한다.
그릇이 커진다면 그 안에 담을 수 있는 물도 더 많아진다는 것.
Resources가 풍부해질수록,우리는 분명히 더 좋은 프로그램을 설계 할 수 있기 때문.개발자들의 결과물은 결국 소비자들에게 priority 가 주어지기 때문이다.
아무리 미세한 데이터 처리 속도의 차이더라도 소비자들에게는 선택권이 많다.
자신이 설계한 프로그램의 선호도를 높이기 위해서, 개발자는 끊임없는 고심을 통해 더 좋고, 더 나은 개발을 할 수 있어야 하기 때문이다.
미래의 우리 소비자들에게 남들과는 다른,
Carefree 한 서비스를 제공하기 위해 Data Structure 을 학습한다.
프로그램의 효율성 측정: Execution time
프로그램의 효율성 측정 방법: Execution time
- Execution time을 측정하는 데에는 두 가지 방법이 있다.
Dynamic Analysis ?
1. Dynamic analysis : 가장 원시적이지만 가장 직관적인 방법이다.
바로 해당 알고리즘을 프로그래밍 언어로 작성하여Prototype을 개발 후 execute 해보는 것이다.
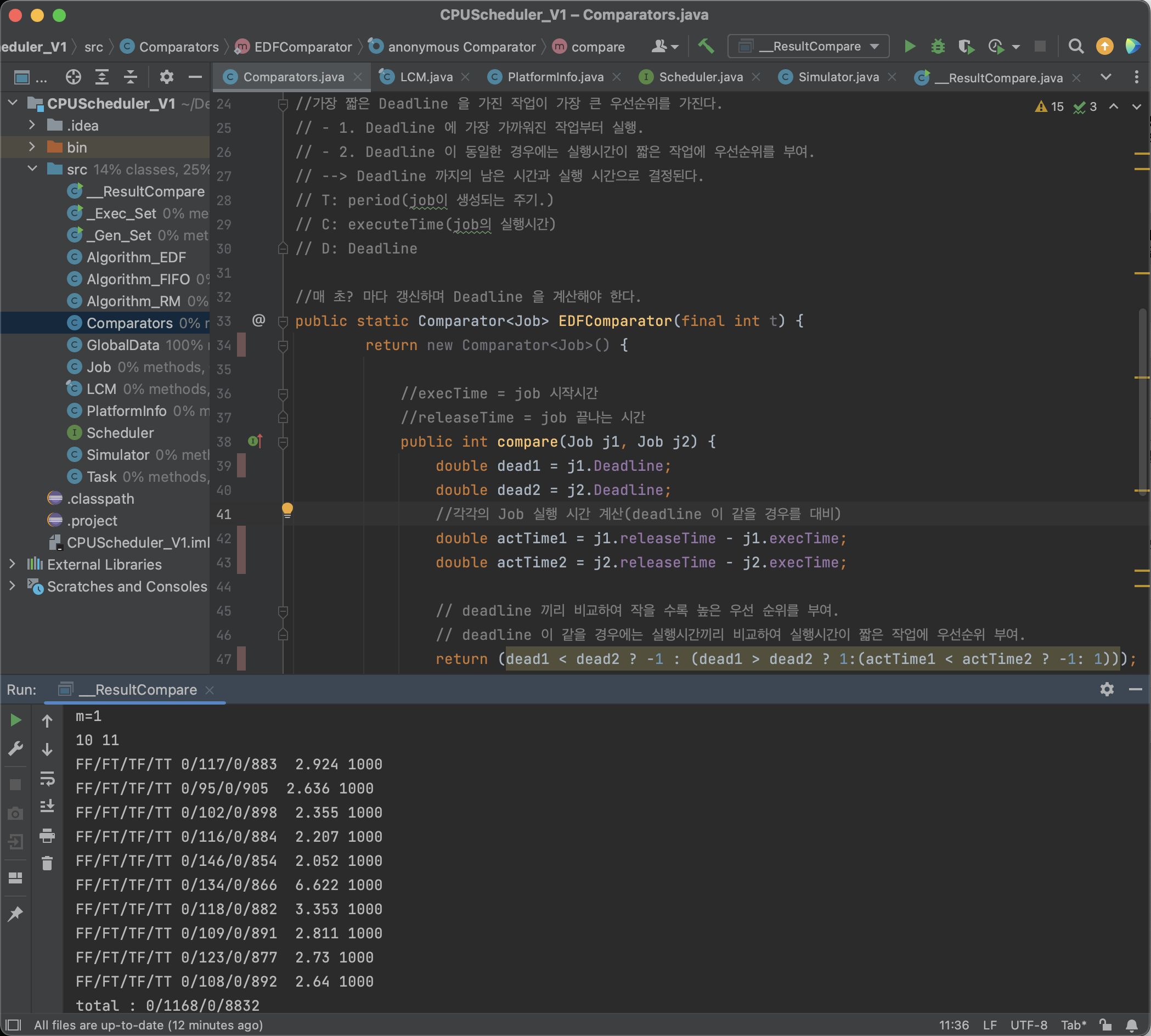
위 사진은 운영체제 수업 실습 과정에서 RM algorithm 과 EDF algorithm을 직접 분석해 본 것인데, 동일한 Simulation Environment 에서 동일한 Task를 처리하는 것 임에도
어떠한 방식의 algorithm을 적용하는지에 따라 수행 능력이 달라지는 것을 볼 수 있다.
- 아쉽게도 Dynamic analysis는 단점이 존재한다.
당연히, Prototype 을 구현하고 테스트 해야 한다는 것 자체가 단점이다.- 또한 본문의 Simulation 처럼, 같은 Environment에서 Prototype을 구현하고 테스트 해봐야 한다는 것이다.
- 더 뛰어난 Environment에서는 알고리즘의 Execution time이 줄어들 수 있기 때문이다.
- 이와 같은 문제점 덕분에
Static analysis, 알고리즘의 복잡도 분석방법이 개발되었다.Static Analysis?
2. Static analysis : Complexity analysis (알고리즘의 복잡도 분석)- 알고리즘의 분석은 두가지 관점에서 수행할 수 있다.
- 시간복잡도 (time complexity)
- 공간 복잡도 (space complexity)
1. 알고리즘의 수행시간 분석 : 시간 복잡도(time complexity)
사진출처:adrianmejia
- 시간 복잡도는 알고리즘의 절대적인 수행시간을 분석하는 것이 아닌,
“해당 알고리즘을 이루고 있는 연산들이 몇 번 수행되는지를 숫자로 표시한다.”- 여기서 연산이란?
기본적인 산술 연산 뿐만 아니라 대입연산, 비교연산 (<,>,= 등) 및 이동연산등
대부분의 연산을 포함한다.- 시간복잡도는 위 연산들의 수행 횟수를 계산하여 여러 알고리즘 사이에서 비교 분석을 가능하게 해준다.
사진출처:sporbiz- 동일한 환경에서 동일한 일을 수행하고 동일한 결과를 출력한다는 가정하에
수행과정이 복잡하지 않고 덜 피곤하게 수행해내 빠르게 결과를 출력할 수 있는 사람을
우리는 통칭 “에이스” 라고 한다..- 동일한 매커니즘으로 우리는 여러 알고리즘 중 연산의 횟수가 더 적은 알고리즘을
“에이스 알고리즘”이라 생각하고 선택하여 적용할 것이다.
이것이"시간복잡도"의 기본 개념이다.
- 시간 복잡도 함수- 연산은 프로그램에 주어지는 입력의 개수 n에 따라 변하기 때문에
연산의 수를 입력의 개수(n)의 함수로 나타낸 것 = 시간복잡도 함수 T(n) 으로 표기- for, while 등의 loop제어 연산은 제외한다.
-> 연산의 정확한 횟수보다는 “증가 추세” 가 중요하기 때문.
ArrayMax(A,n){ tmp ← A[0]; //1번의 대입 연산 for i←1 to n-1 do { //루프 제어 연산은 제외 if tmp < A[i] then //n-1번의 비교 연산 tmp ← A[i]; //n-1번의 대입 연산(최대) } return tmp; //1번의 반환 연산 //총 연산수= 2n(최대) }

.png)
시간복잡도 함수 T(n) 예제(클릭)
.png)
빅오 표기법 - O(n)
빅오 표기법(점근 표기법):
연산의 횟수를 대략적(점근적)으로 표기한 것. 함수의 상한을 표시한다.
- data의 개수가 많은 경우에는
차수가 가장 큰 항이 가장 큰 영향을 미치고,
이외의 항들은 상대적으로 무시가 가능하다.
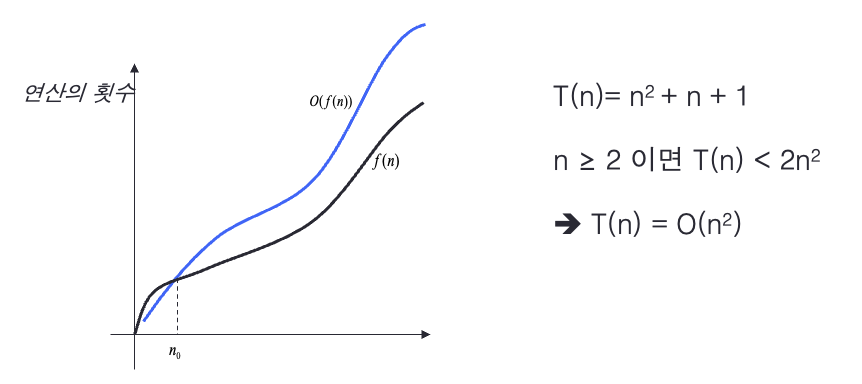
- 예를 들어, T(n)= n2(제곱) + n + 1 과 같은 시간복잡도 함수에서, 입력이 1000개 들어왔을때, T(n)은 1,001,001 이다.
- 첫번째 항인 n2 의 값이 전체의 약 99%인 1,000,000 을 차지한다.
- 따라서 시간복잡도 함수를 구할 때엔 가장 크게 영향을 미치는 항만을 고려해도 충분하다.
두 개의 함수 f(n)과 g(n)이 주어졌을 때, 모든 n ≥ n0에 대하여 f(n) ≤ c g(n) 을 만족하는 2개의 상수 c와 n0가 존재하면 f(n) = O(g(n)) 이다.
.png)
- 위와 같이 불필요한 정보를 제거하여 알고리즘 분석을 쉽게 할 목적으로
시간복잡도 T(n)을 표시하는 방법이 바로 O(n)빅오표기법이다.
빅오 표기법 O(n) 예제(클릭)

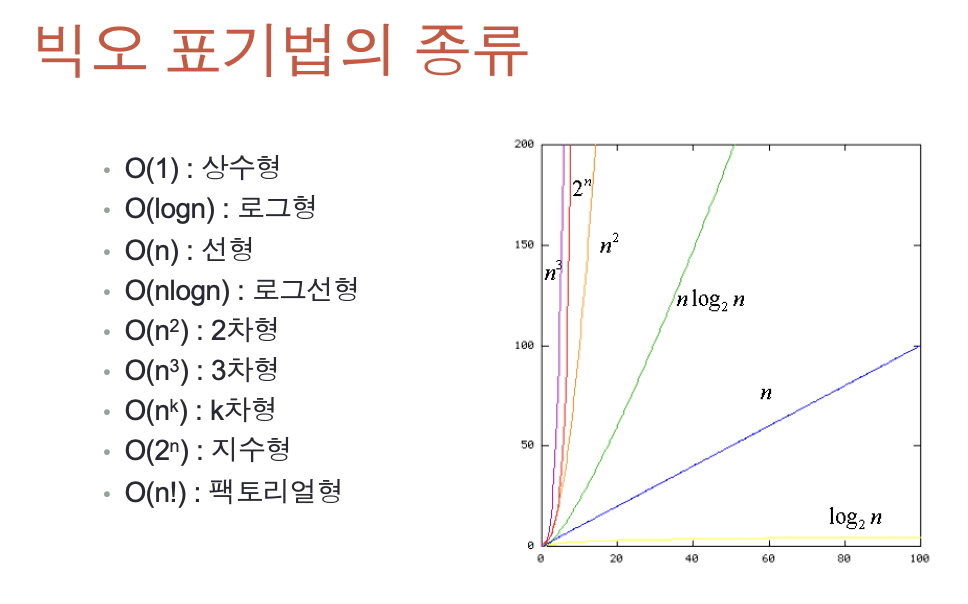
빅오 표기법의 종류
빅오 표기법의 종류
- 빅오표기법은 위와 같은 순서를 가지고 있다.
- 빅오표기법은 입력의 개수에 따른 연산 수행 횟수를 대략적으로 나타낸 것이기 때문에 알고리즘의 대략적인 수행시간을 알 수 있다.
- 알고리즘의 수행시간은 빠른 순서대로
O(1) < O(log n) < O(n) < O(n log n) < O(n2제곱) < O(n3제곱) < O(2n제곱) < O(n!)순으로 나타낼 수 있다.
빅오 표기법 이외의 표기법
빅오표기법 이외의 표기법
1. 빅오메가 표기법:
모든 n ≥ n0에 대하여 |f(n)| ≥ c|g(n)|을 만족하는 2개의 상수 c와 n0가 존재하면
f(n) = Ω(g(n))이다.
빅오메가는 함수의 하한을 표시한다.(최선의 경우)
- (예) n ≥ 0 이면 2n+1 ≥ 1n 이므로 2n+1 = Ω(n)
2. 빅세타 표기법:
모든 n ≥ n0에 대하여 c1|g(n)| ≤ |f(n)| ≤ c2|g(n)|을 만족하는 3개의 상수 c1, c2와 n0가 존재하면f(n) = θ(g(n))이다.
빅세타는 함수의 상한과 하한을 동시에 표시한다.(이론상 가장 이상적인 경우 - 평균)- f(n)=O(g(n))이면서 f(n)= Ω(g(n))이면 f(n)= θ(n)이다.
- (예) n ≥ 1이면 n ≤ 2n+1 ≤ 3n이므로 2n+1 = θ(n)
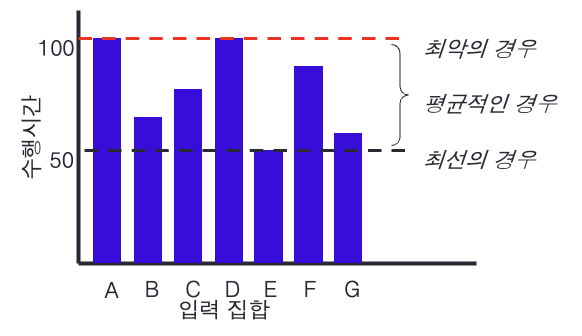
최선, 평균, 최악의 경우?
최선, 평균, 최악의 경우
- 알고리즘의 수행시간은 입력 자료 집합(n)에 따라 다를 수 있다.
- ex. 정렬 알고리즘에 거의 정렬이 되어 있는 자료 집합을 주면?
–> 다른 자료 집합보다 더 빨리 수행될 수 있다.
“정렬 알고리즘의 수행 시간은 입력 집합에 따라 다를 수 있다.”
- 최선의 경우(best case): 수행 시간이 가장 빠른 경우.
- 평균의 경우(average case): 수행시간이 평균적인 경우.
- 최악의 경우(worst case): 수행 시간이 가장 늦은 경우.
(예정)2. 알고리즘이 사용하는 기억공간(자원)의 분석 : 공간 복잡도(space complexity)
참고: C언어로 쉽게 풀어쓴 자료구조 <개정 3판> 천인국, 공용해, 하상국 지음
Task Lists
- Data Structure : 알고리즘의 성능 분석
- 프로그램의 효율성 측정 방법 1. Execution time
- Dynamic analysis
- Static analysis : Complexity analysis (알고리즘의 복잡도 분석)
- 빅오 표기법 - O(n)Permalink
- 빅오 표기법의 종류
- 빅오표기법 이외의 표기법
- 최선, 평균, 최악의 경우



Comments