
Data Structure : (7-2) 연결 리스트 (Linked-List)
연결리스트 (Linked List)
연결리스트(Linked List)?
Linked-List의 모습사진출처:isaaccomputerscience
- 추상적 자료형인
리스트를 구현한 자료구조.- Linked List라는 말 그대로 어떤 데이터 구조체(= 노드 Node)를 저장할 때
다음 순서의 자료가 있는 위치를 데이터에 포함시키는 방식으로 자료를 저장한다.
예를 들어 한 반에 있는 학생들의 자료를 저장한다면, 학생 하나하나의 신상명세 자료를 노드로 만들고, 1번 학생의 신상명세 자료에 2번 학생 신상명세가 어디있는지 표시를 해 놓는 방식이다. 쉽게 생각하면 자료를 비엔나 소시지마냥 줄줄이 엮어놓은 것이다.
연결된 표현 - Linked Representation
- 리스트의 항목들을 노드(node)라고 하는 곳에 분산하여 저장한다.
- 분산된 노드들을 포인터로 연결하여 하나로 묶는 방법이 바로 연결리스트(Linked List)이다.
- 노드(node)는 데이터 필드와 링크 필드로 구성된다.
- 데이터 필드 : 리스트의 원소(데이터) 값을 저장하는 곳.
- 링크 필드 : 다른 노드의 주소값을 저장하는 장소. (포인터로 구현)
Linked Representation - 연결된 표현연결 리스트의 삽입 및 삭제 연산
- 연결리스트에서는 이전에 알아본 배열리스트와 다르게 리스트 곳곳에서의 데이터 저장 및 삭제가 용이하다.
- 연결리스트의 중간에 데이터를 삽입시 주변 데이터의 위치를 이동할 필요 없이 포인터로 연결된 노드 사이의 ‘줄(링크)’만 바꾸어 주면 된다.
- 데이터(노드) 삭제 시에도 마찬가지로 삭제할 노드에 연결되어 있는(줄 - 링크)만 수정해주면 된다.
- 여러 개의 연결리스트를 구분하려면 첫번째 데이터(노드)만 알 수 있으면 된다.
첫번째 데이터를 따라 연결된 모든 데이터를 찾을 수 있기 때문이다.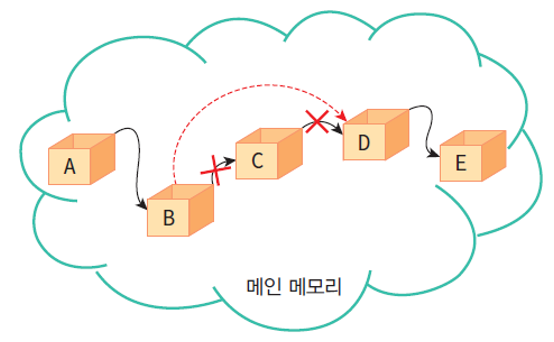
연결리스트의 삽입 및 삭제 연산의 모습
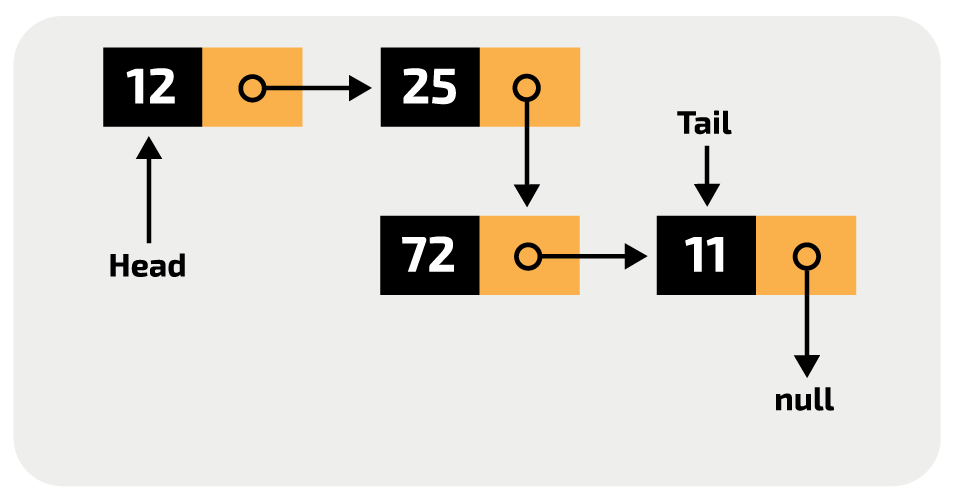
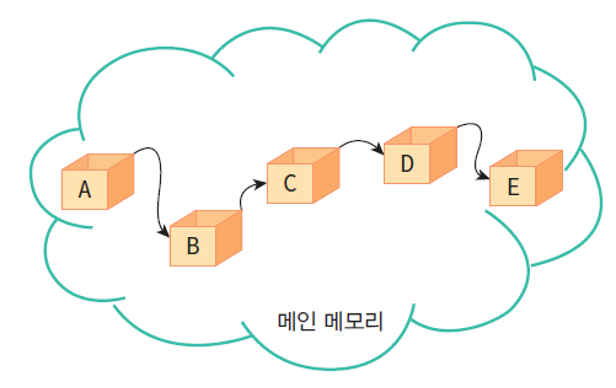
연결 리스트의 구조
노드(node)?
- 노드는 연결리스트를 구성하는 원소이고, 연결리스트는 노드들의 집합이다.
- 노드는 메모리의 어느 위치에서든 존재할 수 있고, 같은 연결리스트 내에서 연결되어 있는 다른 노드로 가기 위해서는 현재 노드가 가지고 있는 링크 필드(link)에 저장되어 있는 다음 노드의 주소를 사용해 이동할 수 있다.
- 노드의 데이터 필드에는 다양한 종류(int, struct…etc)의 데이터가 저장될 수 있다.
- 노드의 링크 필드에는 다음 노드를 가리키는 포인터가 저장되어 있다.
- 현재 노드는 이 포인터를 사용하여 다음 노드로 이동할 수 있다.
- 마지막 노드의 link필드는 NULL로 설정. (다음 노드가 없기 때문에)
- 연결리스트의 노드들은 필요할 때마다 malloc()을 이용하여 동적으로 생성된다. 헤드 포인터?
- 연결리스트에서는 첫번째 노드를 알아야 만이 전체 노드를 찾아갈 수 있다.
- 따라서 연결리스트 마다 첫번째 노드를 가리키고 있는 헤드 포인터 변수가 존재한다.
연결리스트 노드의 구조

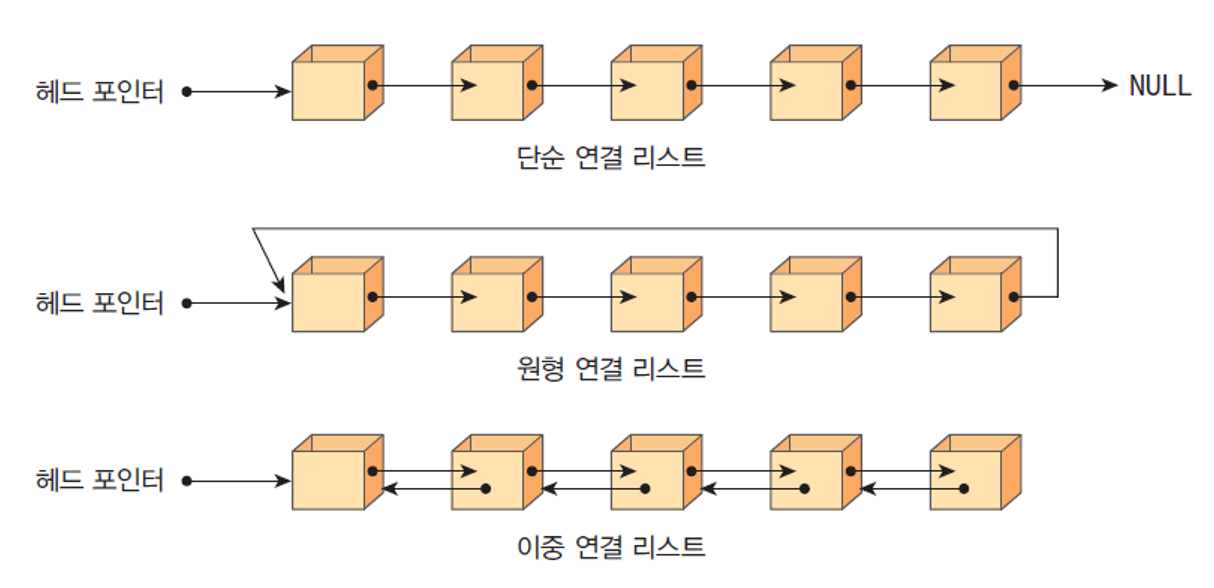
연결 리스트의 종류
연결리스트의 종류
- 단순 연결 리스트(Singly Linked List) : 한 방향으로만 연결되어 있는 리스트이다.
- 마지막 노드의 link는 NULL을 가리킨다.
- 체인(chain)이라고도 한다.
- 원형 연결 리스트(Circular Linked List) : 단순 연결 리스트와 같지만 마지막 노드의 link가 첫번째 노드를 가리킨다.
- 처음과 끝노드의 접근성이 용이해져 데이터 간의 연산 속도가 빠르다.
- 이중 연결 리스트(Doubly Linked List) : 각 노드마다 link 필드가 두 개씩 존재한다.
- llink는 노드 기준 좌측 노드의 주소를 가진다.
- rlink는 노드 기준 우측 노드의 주소를 가진다.
단순 연결리스트
- 단순 연결 리스트에서는 노드들이 하나의 링크 필드를 가진다.
- 모든 노드들은 각 노드의 link 필드를 통해 연결되어 있다.
- 가장 마지막 노드는 다음 노드가 없기 때문에 link필드 값이 NULL이다.
단순 연결 리스트의 모습

단순 연결 리스트 구현 - C
- 노드를 어떻게 정의할 것인가? - 자기 참조 구조체를 사용한다.
- 노드는 어떻게 생성할 것인가? - malloc을 활용하여 필요 시 동적으로 생성한다.
- 노드는 어떻게 삭제할 것인가? - free()를 사용하여 노드에 할당된 메모리를 반환한다.
노드의 정의
노드는 자기참조 구조체를 이용하여 정의한다.
자기 참조 구조체란, 자기 자신을 참조하는 포인터를 포함하는 구조체이다.
구조체 내부에는 우리가 리스트에 저장할 데이터가 담길 data 필드와
다음 노드를 가리키는 포인터가 저장되어 있는 link 필드로 이루어져 있다.
- data 필드는 element 타입의 데이터를 저장하고 있다.
- link 필드는 ListNode 타입을 가리키는 포인터로 정의되며, 다음 노드의 주소를 가진다.
typedef int element;
// 노드 타입을 구조체로 정의.
typedef struct {
element data;
struct ListNode *link;
} ListNode;
위의 코드는 노드의 정의일 뿐이다. 아직 노드가 생성된 것이 아님에 주의하자.
노드를 생성하려면 ListNode 변수를 생성해야 한다.
공백 리스트의 생성
앞전에 말했듯이 단순 연결 리스트는 헤드 포인터를 생성 후 이를 사용해 리스트의 첫번째 노드만 알면 모든 노드를 찾을 수 있다.
다음과 같이 노드를 가리키는 포인터 head를 정의한 순간 하나의 연결리스트가 만들어졌다고 볼 수 있다.
현재는 노드가 없으므로 head의 값은 NULL이 된다.
- 이렇게 생성된 포인터 head가 헤드 포인터가 된다.
ListNode *head = NULL; // 이제 연결리스트가 생성이 되었다.
// 어떠한 리스트가 공백인지를 검사하려면 헤드포인터가 NULL인지를 검사하면 된다.
노드의 생성
일반적으로 연결 리스트에서는 필요할 때마다 동적 메모리 할당을 이용하여 노드를 동적으로 생성한다. (malloc())
- malloc() 함수를 이용하여 노드의 크기만큼의 동적 메모리를 할당 받는다.
- 이렇게 할당된 동적 메모리가 하나의 노드가 된다.
- 동적 메모리의 주소를 헤드 포인터인 head에 저장.
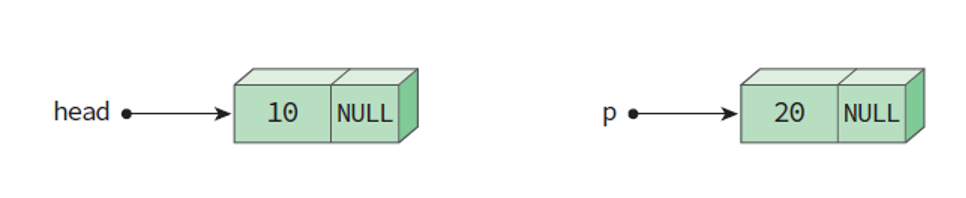
head = (ListNode *)malloc(sizeof(ListNode));- 노드가 생성되었으나 아직 노드 내부는 텅 빈 상태이다.
- 이렇게 노드가 생성된 후에는 노드에 데이터를 저장하고, 링크 필드를 NULL로 설정해야 한다.
- 처음 생성된 노드는 처음이자 마지막 노드이기 때문에 link 필드 값이 NULL이다.
head->data = 10; head->link = NULL;- 이제 같은 방식으로 노드를 하나 더 생성해보자.
ListNode *p; p =(ListNode *)malloc(sizeof(ListNode)); p->data = 20; p->link = NULL;- 연결리스트는 여러 개의 노드가 서로 연결되어 있다.
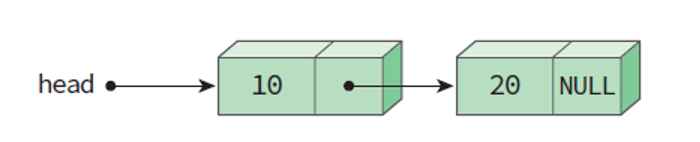
- 생성된 두개의 노드를 서로 연결해보자.
- 처음 생성된 노드 head의 link에 다음 노드인 p의 주소를 저장해주면 된다.
- 이렇게 되면 head 노드가 p노드를 가리키게 된다.
head->link = p;- 이제 리스트는 아래처럼 연결이 될 것이다.
- 이 과정을 반복하면 원하는 크기의 리스트를 생성할 수 있다.
생성된 노드 간의 연결
단순 연결 리스트의 연산 구현
원리를 알았으니 이제 함수를 구현하여 추상적으로 설계해보자.
insert_first(): 리스트의 시작 부분에 항목을 삽입하는 함수
insert(): 리스트의 중간 부분에 항목을 삽입하는 함수
delete_first(): 리스트의 첫 번째 항목을 삭제하는 함수
delete(): 리스트의 중간 항목을 삭제하는 함수
print_list(): 리스트를 방문하여 모든 항목을 출력하는 함수
// 단순 연결 리스트의 정의
ListNode *head; // 단순 연결 리스트는 원칙적으로 헤드 포인터만 있으면 된다.
삽입 연산 insert_first()
- 리스트의 첫 부분에 새로운 노드를 추가하는 함수
- 여기서 매 순간마다 생성되는 노드는 해당 리스트의 매 순간 첫 노드가 될 것이다.
- 따라서 매개변수로 헤드포인터를 넘겨 헤드 포인터가 생성될 노드를 가리키도록 해야 한다.
- 원하는 데이터 값도 매개변수로 받아 노드의 data 필드에 저장해주자.
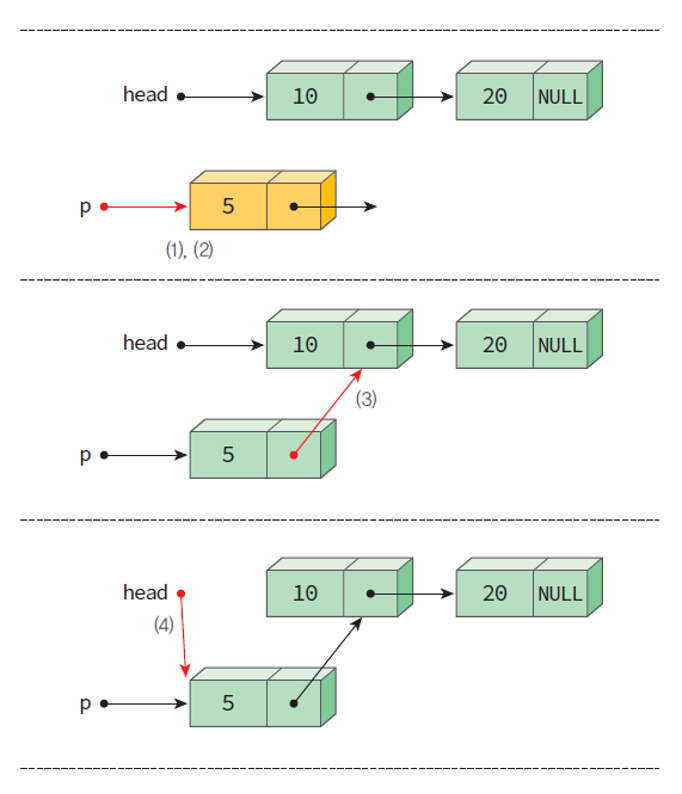
ListNode* insert_first(ListNode *head, element data){
ListNode *p = (ListNode *)malloc(sizeof(ListNode)); // 신규 노드 생성
p->data = data; // 생성된 노드에 파라미터로 넘어온 데이터 삽입
p->link = head; // 생성된 노드에 헤드 포인터 head가 가리키고 있던 기존 첫 노드의 주소를 알려준다.
head = p; // 헤드 포인터가 새로 생성된 노드 p를 가리키도록 한다.
return head; // 변경된 헤드 포인터 head를 반환한다.
}
삽입 연산 insert()
- insert()는 가장 일반적인 경우로서, 연결리스트의 중간에 새로운 노드를 삽입하는 연산이다.
- 반드시 삽입되는 위치의 선행 노드를 알아야 삽입이 가능하다.
- 선행 노드를 pre가 가리키고 있다고 가정 후 구현해보자.
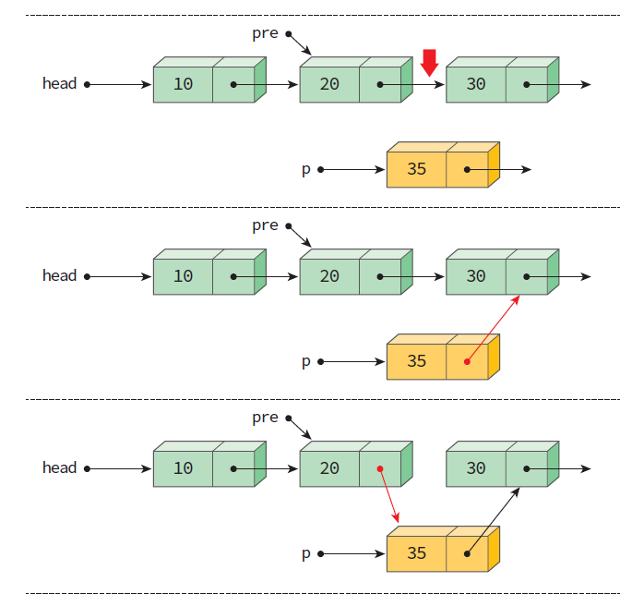
ListNode* insert(ListNode *head, ListNode *pre, element data) {
ListNode *n = (ListNode *)malloc(sizeof(ListNode));
n->data = data;
n->link = pre->link;
pre->link = n;
return head;
}
삭제 연산 delete_first()
delete_first()
- 첫번째 노드를 삭제하는 함수 delete_first()는 다음과 같은 원형을 가진다.
- 헤드 포인터의 값을 removed에 복사한다.
- 헤드 포인터의 값을 head->link로 변경한다.
- removed가 가리키던 동적 메모리를 반환한다.
- 변경된 헤드 포인터를 반환한다.
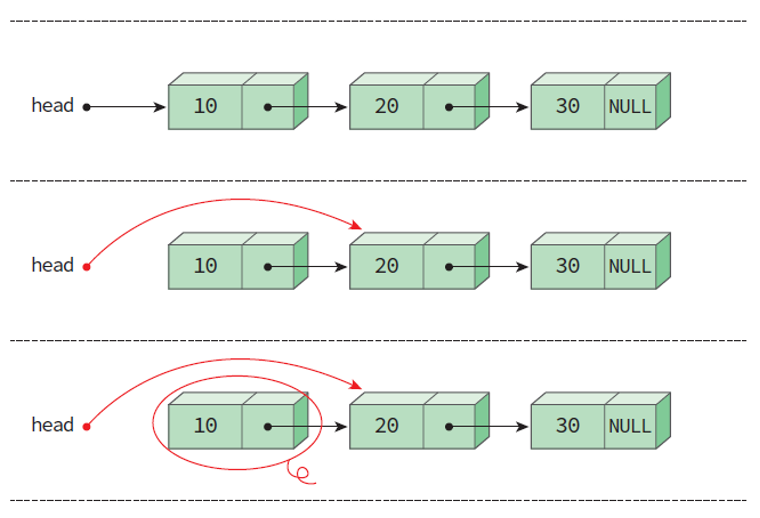
ListNode* delete_first(ListNode *head) {
ListNode *removed; // 삭제할 노드의 주소를 임시 복사해놓을 removed 생성.
if(head == NULL) return NULL; //헤드 포인터가 가리키는 것이 없으면 오류.
removed = head; // 헤드 포인터가 가리키고 있던 기존 첫번째 노드(삭제대상)를 removed에 복사.
head = removed->link // 기존 헤드 포인터가 가리키고 있던 첫번째 노드의 다음노드를 가리키도록 설정.
free(removed); // 삭제 대상인 첫번째 노드에게 할당된 메모리를 반환.
return head; // head 포인터가 가리키고 있던 노드가 갱신 되었으므로 반환하여 갱신.
}
삭제 연산 delete()
delete()
- 리스트 중간에 위치한 노드를 삭제할 수 있는 함수이다.
- 삭제할 노드를 찾는다.
- 노드 pre의 링크 필드가 삭제할 노드의 link를 가리키게 한다.
- 삭제할 노드에게 할당된 메모리를 반환한다.
- 변경된 헤드 포인터를 반환한다.
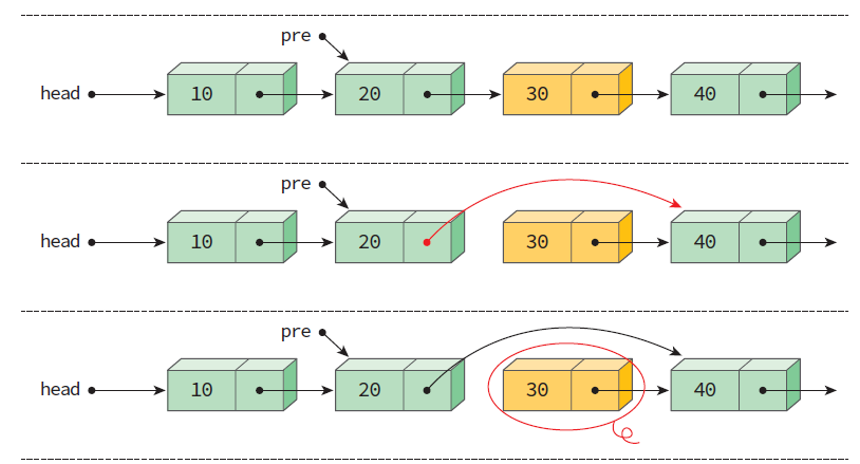
ListNode* delete(ListNode *head, ListNode *pre){
ListNode *removed;
removed = pre->link;
pre->link = removed->link;
free(removed);
return head;
}
리스트 출력 함수 print_list()
- 노드의 link 값이 NULL이 아니면 계속 link값을 따라가며 노드를 방문한다.
- 어떤 노드의 link값이 NULL이면 마지막 노드에 도달한 것이므로 반복을 중단한다.
void print_list(ListNode *head) {
pritf("\n Linked List: \n");
for(ListNode *p = head; p != NULL; p = p->link) {
printf("%d->", p->data);
}
printf("\n");
}
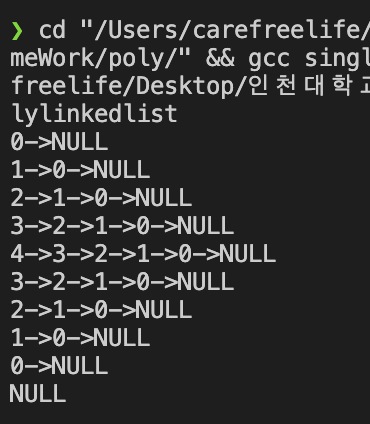
전체 테스트 프로그램 - Singly Linked List
단순 연결 리스트를 활용한 전체 테스트 프로그램을 작성해보자.
#include<stdio.h>
#include<stdlib.h>
typedef int element;
typedef struct ListNode{
element data;
struct ListNode *link;
}ListNode;
ListNode* insert_first(ListNode *head, element data) {
ListNode *p = (ListNode *)malloc(sizeof(ListNode));
p->data = data;
p->link = head; // 헤드 포인터의 값 복사
head = p;
return head;
}
ListNode* insert(ListNode *head, ListNode *pre, element data) {
ListNode *p = (ListNode *)malloc(sizeof(ListNode));
p->data = data;
p->link = pre->link;
pre->link = p;
return head;
}
ListNode* delete_first(ListNode *head) {
ListNode *removed;
removed = head;
head = removed->link;
free(removed);
return head;
}
ListNode* delete(ListNode *head, ListNode *pre) {
ListNode *removed = pre->link;
pre->link = removed->link;
free(removed);
return head;
}
void print_list(ListNode *head){
for(ListNode *p = head; p != NULL; p = p->link) {
printf("%d->", p->data);
}
printf("NULL \n");
}
int main(void) {
ListNode *head = NULL;
for(int i = 0; i < 5; i++) {
head = insert_first(head, i);
print_list(head);
}
for(int i = 0; i < 5; i++) {
head = delete_first(head);
print_list(head);
}
return 0;
}
Singly Linked List 테스트 결과
원형 연결 리스트 (Circular Linked List)
원형 연결 리스트를 알아보자.
- 원형 연결 리스트란
마지막 노드가 첫번째 노드를 가리키는 리스트이다.
- 마지막 노드의 링크가 NULL이 아닌, 첫번째 노드의 주소가 되는 리스트 이다.
- 원형 연결 리스트의 장점
하나의 노드에서 다른 모든 노드로의 접근이 가능해진다.- 마지막 노드에서 첫번째 노드로 접근이 가능해짐에 다음 노드로 이동하다 보면
결국 자기 자신에게로 돌아올 수 있으며 리스트 내의 모든 노드에 접근이 가능해진다.- 원형 연결 리스트에서는
헤드 포인터가 마지막 노드를 가리키도록 구성하면
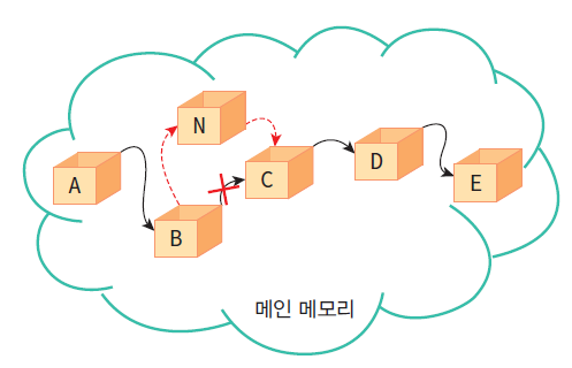
노드의 삽입 및 삭제가 단순 연결 리스트보다 용이해진다.<그림 2 참조>- 원형 연결 리스트에서 삽입 및 삭제 연산을 할 때에는 항상
선행 노드를 가리키는 포인터를 필요로 한다.
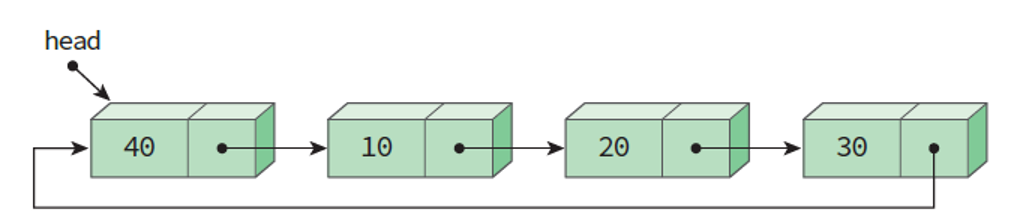
원형 연결 리스트의 모습 - Circular Linked List
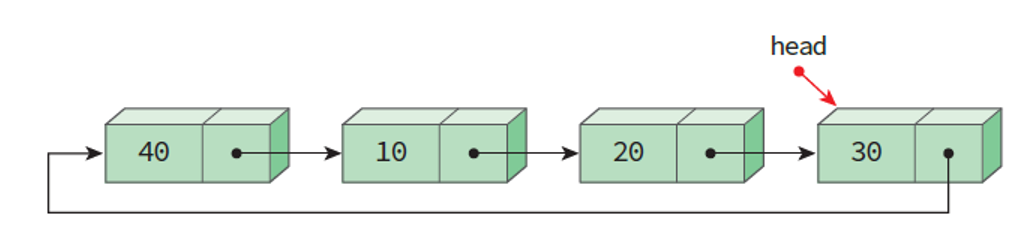
<그림 2> 원형 연결 리스트의 용이성 - Circular Linked List- 단순 연결 리스트에서 리스트의 끝에 노드를 추가하려면 head부터 마지막 노드까지 link를 타고 이동하여 추가해야 하지만 원형 리스트에서는 헤드 포인터가 마지막 노드를 가리키도록 구성한다면 리스트의 처음과 끝에서 효율적으로 노드 연산 실행을 할 수 있다.
- 헤드 포인터가 마지막 노드를 가리키고 있고, head->link가 첫 노드를 가리키고 있으므로 효율적인 삽입 및 삭제 연산이 가능해진다.
원형 연결 리스트의 정의
typedef int element;
typedef struct ListNode {
element data;
struct ListNode *link;
} ListNode;
// 원형 연결 리스트도 원칙적으로 헤드 포인터만 있으면 된다.
ListNode *head;
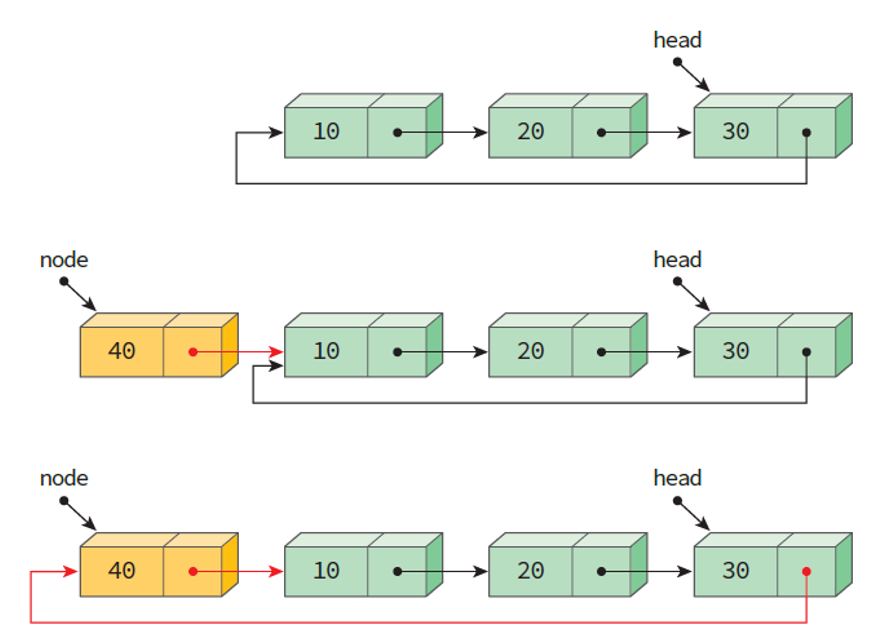
원형 연결 리스트의 처음에 삽입.
- 새로운 노드의 link가 첫 노드를 가리키게 한다.
- 마지막 노드의 link가 첫 노드를 가리키게 한다.
- 헤드 포인터가 마지막 노드를 가리킨다는 것만 기억하면 크게 어렵지 않다.
원형 연결 리스트의 처음에 노드 삽입 과정
// 원형 리스트의 처음에 삽입하는 함수
ListNode* insert_first(ListNode *head, element data) {
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
node->data = data;
// 만약 리스트에 노드가 하나도 없을 시,
if(head == NULL) {
head = node; // 신규 노드가 마지막 노드이자,
node->link = head; // 마지막 노드의 link인 첫번째 노드가 된다.
}
// 리스트에 노드가 존재 한다면
else {
node->link = head->link; //기존 헤드 포인터의 link가 가리키던 첫번째 노드를 생성된 신규 노드의 link가 가리키도록 한다.
head->link = node; // 헤드 포인터의 link가 신규 생성된 첫번째 노드인 node를 가리키도록 한다.
}
return head; // 변경된 헤드 포인터를 반환.
}
원형 리스트의 끝에 삽입하는 함수
// 원형 리스트의 끝에 삽입하는 함수
ListNode* insert_last(ListNode *head, element data) {
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
node->data = data;
if(head == NULL) {
head = node;
node->link = head;
}
else {
// 기존 헤드 포인터가 가리키던 마지막 노드의 link는 첫번째 노드의 주소.
// 따라서 head->link를 신규 생성된 node->link에 넣어
// node가 첫번째 노드를 가리키도록 해준다.
node->link = head->link;
// 이제 마지막 노드가 될 node(의 주소)를 기존 마지막 노드의 링크(head->link)에 연결.
head->link = node;
//헤드 포인터는 마지막 노드가 된 node를 가리키도록 갱신.
head = node;
}
return head; // 변경된 헤드 포인터를 반환.
}
원형 연결 리스트 테스트 프로그램
원형 연결 리스트 테스트 프로그램을 작성해보자.
// 원형 연결리스트는 마지막 노드의 link가 NULL이 아니기 때문에 마지막 노드에 도달했는지
// 검사하려면 헤드 포인터와 비교해야 한다.
// 또한 원형 연결리스트는 while문이 아닌 do while 문을 사용해야 한다.
#include<stdio.h>
#include<stdlib.h>
typedef int element;
typedef struct ListNode{
element data;
struct ListNode *link;
}ListNode;
//insert first
ListNode* insert_first(ListNode* head, element data) {
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
node->data = data;
if(head == NULL) {
head = node;
node->link = head;
}
else{
node->link = head->link;
head->link = node;
}
return head;
}
//insert last
ListNode* insert_last(ListNode *head, element data) {
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
node->data = data;
if(head == NULL) {
head = node;
node->link = head;
}
else{
node->link = head->link;
head->link = node;
head = node;
}
return head;
}
//print list
void print_list(ListNode *head) {
ListNode *p;
if(head == NULL) return;
p = head->link;
do
{
printf("%d->", p->data);
p = p->link;
} while (p != head);
printf("%d", p->data); // 마지막 노드(head)의 출력
}
int main(void) {
ListNode *head = NULL;
//insert_last / first가 반환한 헤드포인터를 head에 대입.
head = insert_last(head, 20);
head = insert_last(head, 30);
head = insert_last(head, 40);
head = insert_first(head, 10);
print_list(head);
return 0;
}
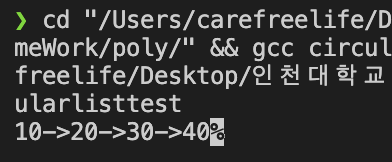
형 연결 리스트 테스트 프로그램 실행 결과
이중 연결 리스트 (Doubly Linked List)
이중 연결 리스트를 알아보자.
이중 연결 리스트의 구조
- 단순 연결 리스트와 원형 리스트는 한 노드의 후속 노드를 찾기는 쉽지만, 그에 비해 선행 노드를 찾기는 쉽지 않다. 이에 이중 연결 리스트가 만들어 졌다.
- 이중 연결 리스트:
- 하나의 노드가 선행 노드와 후속 노드에 대한 두 개의 링크를 가지는 리스트.
- 링크가 양방향으로 지원되어 양방향의 검색이 가능해진다.
- 헤드 포인터와는 다른 개념인 헤드 노드가 존재한다. (헤드 포인터도 가진다.)
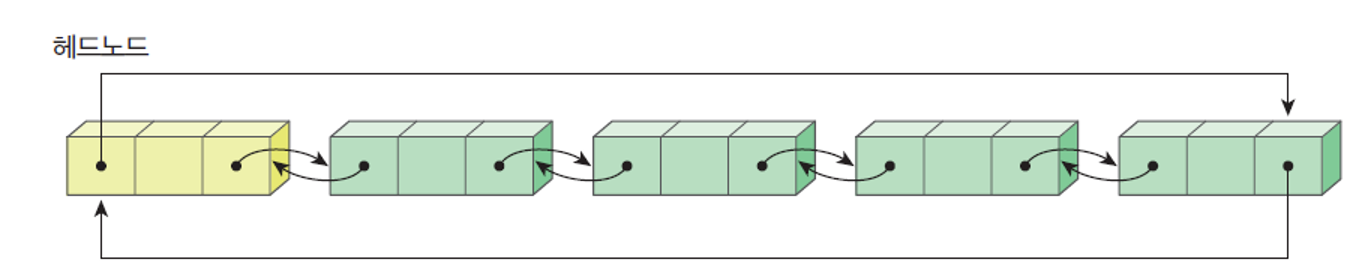
- 헤드 노드:
- 데이터를 가지지 않고 삽입 및 삭제 코드를 간단하게 할 목적으로 만들어진 노드.
- 리스트가 공백 상태일때 리스트에는 헤더 노드만 존재한다.
- malloc을 통해 구조체 변수로 생성한다.
- 헤드 포인터:
- 리스트의 첫번째 노드를 가리키는 포인터.
- 생성시 malloc 등으로 동적 메모리 할당을 하지 않는 포인터 변수이다.
이중 연결 리스트에서는 보통 헤드 노드가 존재하므로, 단순 연결 리스트처럼 헤드 포인터가 필요 없다.
즉 헤드 노드만 알고 있으면 어떤 노드로든 접근할 수 있다.
헤드 노드는 보통 main 함수안에 head라는 이름으로 생성되어 있다.
이중 연결 리스트는 사용하기 전에 반드시 초기화 해야 한다.
-> 헤더 노드의 링크 필드들이 자기 자신을 가리키고 있도록 초기화.
이중 연결 리스트의 구현
이중 연결 리스트를 구현해보자.
노드의 구조
- 이중 연결 리스트를 구현하기 위해 노드의 구조를 먼저 정의해보자.
- 이중 연결 리스트에서의 노드는 3가지의 필드를 가진다.
- 왼쪽 링크 필드(llink), 데이터 필드(data), 오른쪽 링크 필드(rlink)
- 링크 필드는 포인터로 이루어진다.
// 이중 연결 노드 타입
typedef int element;
typedef struct DListNode {
element data;
struct DListNode *llink;
struct DListNode *rlink;
} DListNode;
이중 연결 리스트에 대하여 항상 다음이 성립한다.
p = p->llink->rlink = p->rlink->llink이는 이중 연결 리스트에서 앞뒤로 똑같이 이동 할 수 있음을 나타낸다.
공백 리스트에서도 헤드 노드가 존재하기 때문에 성립한다.
이중 연결 리스트의 삽입 및 삭제 연산
이중 연결 리스트의 삽입 및 삭제 연산을 알아보자.
삽입 연산
이중 연결 리스트의 삽입 연산 구현 순서
- 위 그림의 순서대로 각 노드 링크 필드의 값을 바꾸어 주어야 한다.
- 새로 만들어진 노드의 링크를 먼저 수정하는 이유는
아직 아무 정보도 가지고 있지 않아 안전하기 때문이다.
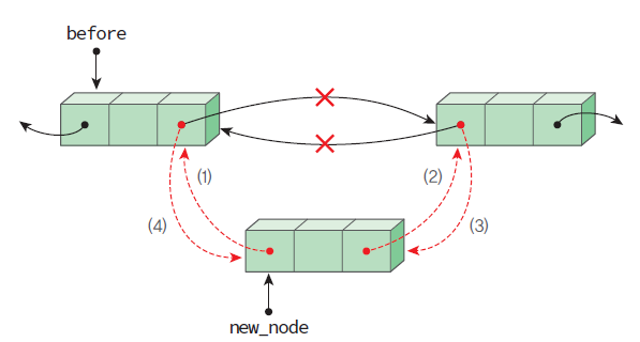
// 이중 연결 리스트의 삽입 함수
// head 포인터를 사용하지 않기 때문에 반환도 하지 않으므로 void
// before 노드의 오른쪽에 삽입한다.
void dinsert(DListNode *before, element data) {
DListNode *newnode = (DListNode *)malloc(sizeof(DListNode));
newnode->data = data;
// 새로 생성된 노드부터 연결 해준다.
newnode->llink = before;
newnode->rlink = before->rlink;
// 기존 노드를 새로 생성된 노드에 연결할 때에는 생성된 노드가 없다 생각하고
// (before->rlink == new node 오른쪽에 있을 노드)->llink = newnode
before->rlink->llink = newnode;
before->rlink = newnode;
}
// 이중 연결 리스트의 삭제 함수.
// 반환 하지 않으므로 void
// 노드 removed를 삭제한다.
void ddelete(DListNode *head, DListNode *removed) {
if (removed == head) return;
removed->llink->rlink = removed->rlink;
removed->rlink->llink = removed->llink;
free(removed);
}
이중 연결 리스트 - 테스트 프로그램
이중 연결 리스트의 테스트 프로그램을 작성해보자.
#include<stdio.h>
#include<stdlib.h>
typedef int element;
typedef struct DListNode {
element data;
struct DListNode *rlink;
struct DListNode *llink;
} DListNode;
void init(DListNode *phead) {
phead->rlink = phead;
phead->llink = phead;
}
//print_list
void print_dlist(DListNode *phead) {
for(DListNode *p = phead->rlink; p != phead; p = p->rlink) {
printf(" <-| |%d| |-> ", p->data);
}
printf("\n");
}
// dinsert
void dinsert(DListNode *before, element data) {
DListNode *newnode = (DListNode *)malloc(sizeof(DListNode));
newnode->data = data;
newnode->llink = before;
newnode->rlink = before->rlink;
before->rlink->llink = newnode;
before->rlink = newnode;
}
// ddelete
void ddelete(DListNode *head, DListNode *removed) {
if(removed == head) return;
removed->llink->rlink = removed->rlink;
removed->rlink->llink = removed->llink;
free(removed);
}
//main
int main(void) {
DListNode *head = (DListNode *)malloc(sizeof(DListNode));
init(head);
printf("추가 단계: \n");
for (int i = 0; i < 5; i++) {
// 헤드 노드의 오른쪽에 삽입
dinsert(head, i);
print_dlist(head);
}
printf("\n삭제 단계\n");
for (int i = 0; i < 5; i++) {
print_dlist(head);
ddelete(head, head->rlink);
}
free(head);
return 0;
}
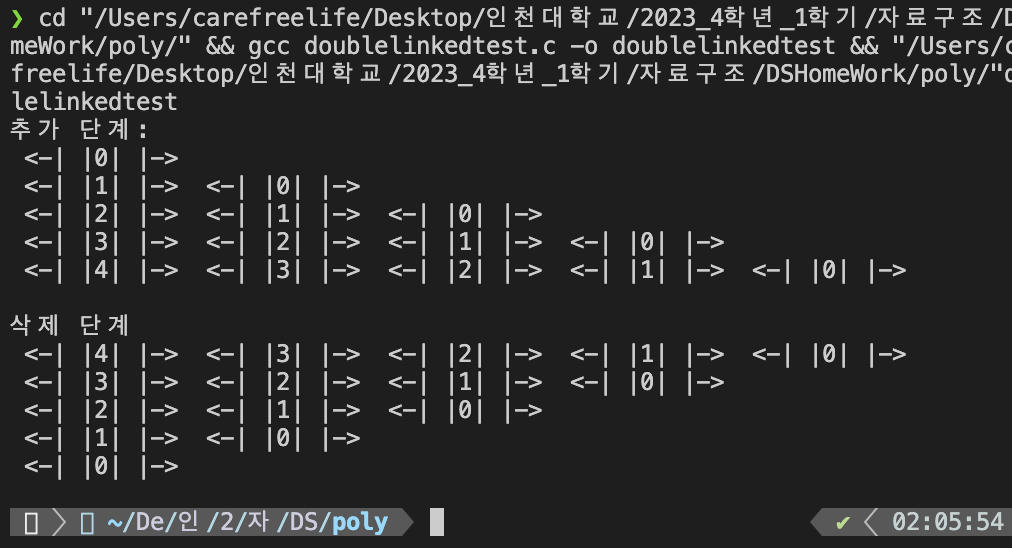
이중 연결 리스트의 테스트 프로그램 실행 결과
연결리스트의 구현 with C Delete_same_nodes
C 언어를 활용하여 연결리스트를 생성하고, 알고리즘에 따라 제거해보자.
군 제대 복학 후 4년만에 자료구조 전공 강의에서 마주친 C언어..
있지도 않은 기억을 되짚어가며 구글링, TA님, 전공 책 등의 도움으로 간신히 구현에 성공했다..중간에 꺾일 뻔 했다 진심으로…;;
지금부터 그 극악무도한 과정을 함께 살펴보자
( 아는 것이 없어 처음엔 수업듣기도 벅차고 어려웠으나 1주 정도 오기로 구현해내고 난 후에
자료구조 수업듣는데에 많은 도움이 된 것 뿐만 아니라 큰 자극이 되었던 과제이다.
막상 구현하고 나니 그렇게 많은 시간을 쏟을 문제가 아니었던것 같다.
하지만 이 또한 내 자신이 그만큼 성장을 했고 보이는 것이 많아졌기 때문이라는 확신이 든다.
본인이 자료구조 수업을 처음 접하거나 C언어, 특히 포인터를 잘 모른다면
개인적으로 꼭 한번 자신의 힘으로 구현해보길 추천한다. 😊)
delete_same_nodes 의 구현
🔥 문제 🔥
단순 연결 리스트에 0~99 사이의 임의의 정수 한 개를 가진 노드를 생성하여 리스트의 끝에 집어넣는 일을 100번 반복해보자. 이렇게 생성된 단순 연결리스트를 처음부터 탐색하여 만약 숫자가 중복된다면 해당 노드를 삭제한다. 예를 들어 11 -> 7 -> 2 -> 11 -> 9 ... 라면 11이 중복되므로 11 -> 7 -> 2 -> 9... 가 된다. 이렇게 생성된 단순 연결 리스트의 숫자들을 처음부터 끝까지 출력해보시오.
여기서부터 코드를 토글리스트(접기 / 펼치기)로 구현 해두었습니다.
각 순서를 보고 자신의 힘으로 작성해보신 이후에 펼쳐 보시면 좋을 것 같습니다!!
아래 목차별로 클릭하시면 코드가 나옵니다.
1. List 와 Node 형식 정의 (클릭)
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
typedef int element; //node에 담길 데이터 타입의 변수 정의
// 리스트의 node를 구조체 형식으로 정의.
// 각 node는 int형 타입으로 정의 된 element 타입의 data와
// 다음 노드의 주소를 가지고 있는 link 변수를 가지고 있다.
// (ListNode 구조체의 link 변수는 다음 '노드'를 가리키므로
// 자신과 같은 타입인 ListNode 구조체 타입을 가지고 있다.)
typedef struct {
element data;
struct ListNode* link;
} ListNode;
// List의 타입을 정의.
// ListType 이라는 구조체에 List의 정보를 담는다.
// List의 크기를 나타내는 int형 변수 size와
// List에 구현될 처음과 끝 노드를 가리키는 ListNode* head, ListNode* tail 변수를 가진다.
typedef struct {
int size;
ListNode* head;
ListNode* tail;
} ListType;
2. 단순 연결리스트의 ADT (클릭)
// header 노드를 사용하여 head 부터 tail까지의 data 값을 출력.
void print(ListType* plist)
{
ListNode* p = plist->head;
printf("Structure of Related List: ");
for (; p; p = p->link) {
printf("%d->", p->data);
}
printf("\n");
}
// 오류함수
void error(char *message){
fprintf(stderr, "%s\n", message);
exit(1);
}
// 헤더 노드 생성
ListType* create() {
ListType *L = (ListType *)malloc(sizeof(ListType));
if(L == NULL) {
error("헤더 노드 메모리 할당 오류");
}
L->head = L->tail = NULL;
L->size = 0;
return L;
}
// 생성된 노드를 탐색하여 같은 data값을 가진 노드를 삭제한다.
int deleteSame(ListType *L, ListNode *n){
// 임시 노드 세 개 생성.
// x : 첫번째 루프에서 기준 노드로 잡고 x와 같은 데이터 값을 가진 노드를 찾는다.
// y : 두번째 루프에서 기준 노드인 x와 같은 중복 노드가 있는지 x 이후의 노드 전체를 탐색한다.
// temp : 중복 노드 y 발견 시, 노드 y 삭제 전 반환할 y의 data와 할당된 메모리를 위해 y의 주소를 가리키고 있는다.
ListNode *x, *y, *temp;
int sum = 0;
// 파라미터로 받은 노드 n를 임시노드 x에 복사.
x = n;
// 첫번째 루프. 파라미터로 받은 노드가 없거나
// 해당 노드가 마지막 노드가 아닐때까지 루프.
// 이 노드 x와 같은 값을 가진 노드를 리스트의 처음부터 끝까지 탐색하여 찾는다.
while(x != NULL && x->link != NULL){
// 두번째 임시노드 y도 파라미터로 들어온 노드를 가리킨다.
// y 포인터를 이용해 x노드와 같은 값을 가진 노드를 다음 루프에서 탐색한다.
y = x;
// 노드 x부터 마지막 노드까지 턴마다 다음노드를 가리킨다.
while(y->link != NULL){
//처음 x가 가리키고 있는 노드와 다음 노드의 data 값이 같은지를 y를 다음 노드 역할을 수행시켜 비교.
//만약 현재 노드와 다음노드의 data가 같다면,
if(x->data == y->link->data){
//세번째 임시 노드인 temp에 중복 노드인 y의 주소를 가리키도록 해놓는다.
// 후에 노드 y가 삭제되면 반환할 y의 데이터와 할당된 메모리를 찾지 못하기 때문에 임시 저장용도.
temp = y->link;
// 이후, 중복노드 y의 다음 노드 와의 연결(y->link)을 끊고
// 다다음노드와 연결한다.(y->link->link)
y->link = y->link->link;
printf("중복 노드 제거: %d \n", temp->data);
sum += 1; // 중복노드의 총 개수 파악용
L->size--; // 리스트 사이즈 -1 갱신
// 그 후, 연결이 끊어진 중복노드 y에게 할당된 메모리 반환을 위해
// y의 주소를 임시 저장해둔 temp를 사용하여 y의 메모리 반환을 해준다.
free(temp);
}
//만약 중복노드가 아니라면, y는 그 다음 노드로 연결되어 중복 노드인지 확인할 준비를 한다.
else{
y = y->link;
}
}
//한 노드 x의 중복 검사가 tail까지 완료되면 x를 다음 노드로 연결해 다음 비교 준비를 한다.
x = x->link;
}return sum; // 중복 노드의 총 개수를 반환한다.
}
// 노드 생성 및 리스트의 뒤로 추가
void insert_last(ListType *L, int data){
// 동적 할당된 노드 생성
ListNode *N = (ListNode *)malloc(sizeof(ListNode));
if(N == NULL) {
error("메모리 할당 에러");
}
// 파라미터로 받은 난수 n을 신규 생성된 노드의 data 필드에 넣어준다.
N->data = data;
// 가장 마지막에 삽입되는 노드는 다음 노드가 없기 때문에 link 필드가 null 이다.
N->link = NULL;
// 만약 헤더 노드의 tail이 NULL(아무것도 가리키고 있지 않음)이라면
// 가장 처음 추가된 노드이기 때문에 해당 노드는 리스트에서 처음이자 끝 노드가 된다.
// 그러므로, 헤더노드 L의 head, tail 필드 둘 다 노드 N을 가리키고 있어야 한다.
if(L->tail == NULL) {
L->head = L->tail = N;
}
// 헤더 노드가 가리키고 있는 것이 있다면, 그 순간부터는 노드가 두 개 이상이므로
// 헤더 노드의 head 필드와 tail 필드가 같지 않다.
// 즉 마지막 노드를 가리키고 있는 tail의 link 필드가 새로 생성된 노드 N을 가리키도록 한다.
// 이후 변경된 tail 필드를 갱신 해준다. (L->tail = N)
else {
L->tail->link = N;
L->tail = N
}
// 노드가 하나 생성되었으므로 리스트의 size++
L->size++;
}
3. main 함수 (클릭)
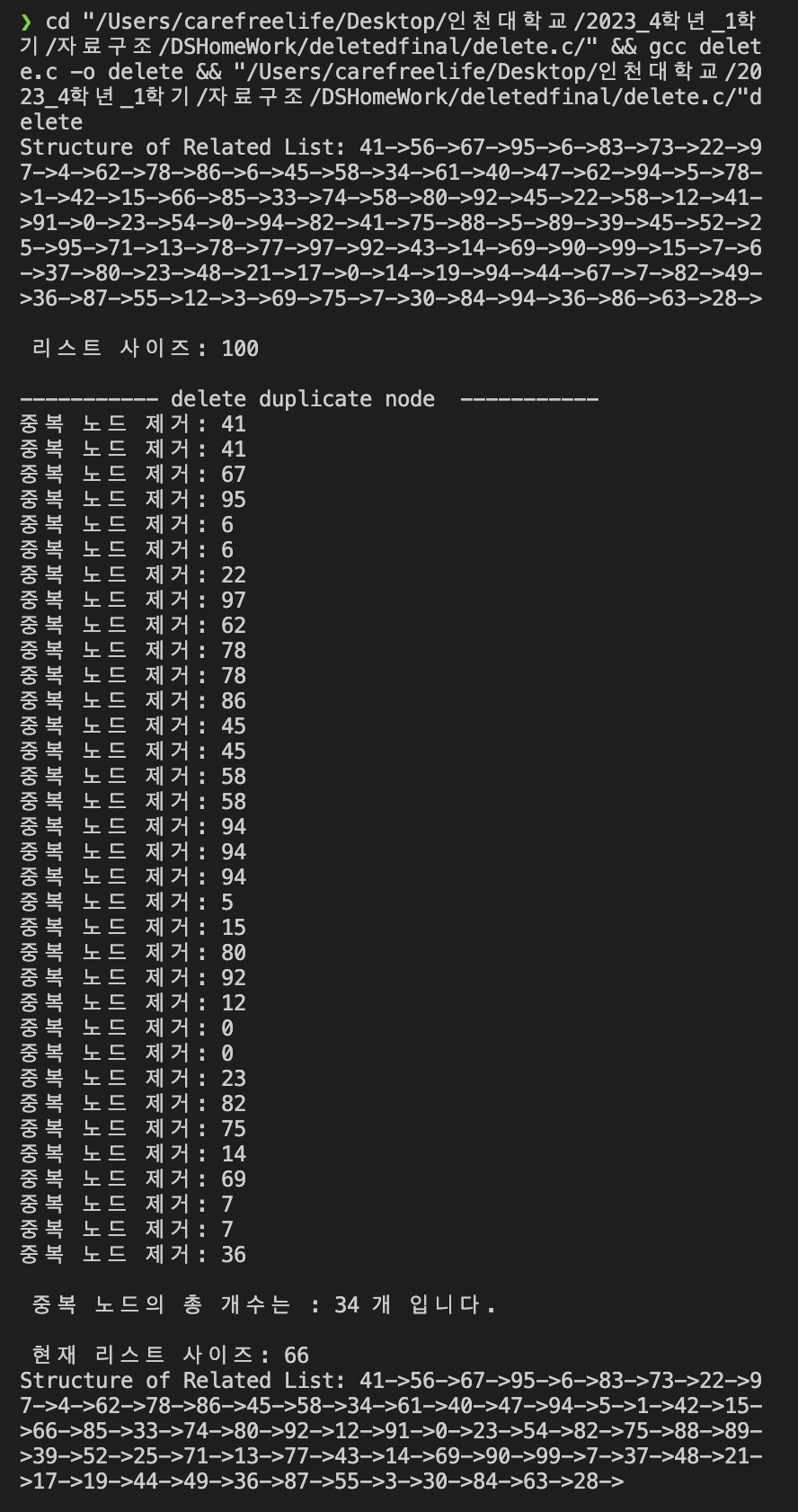
int main() {
//헤더노드 선언
ListType *listHeader;
//헤더노드 생성
listHeader = create();
//난수 초기화
srand(time(NULL));
//insert_last 함수를 100번 시행하여 100개의 (random data 값을 가진) 노드가 있는 연결리스트 구현.
for(int i = 0; i<100; i++){
insert_last(listHeader, rand() % 100);
}
// 구현된 연결리스트 확인용
print(listHeader);
printf("\n 리스트 사이즈: %d \n", listHeader->size);
// 아래에 중복이 제거된 연결리스트 출력
printf("\n----------- delete duplicate node -----------\n");
//중복 제거 함수 실행
printf("\n 중복 노드의 총 개수는 : %d 개 입니다. \n", deleteSame(listHeader, listHeader->head));
//최종 연결리스트 확인용
printf("\n 현재 리스트 사이즈: %d \n", listHeader->size);
print(listHeader);
//종료
return 0;
}
DeleteSameNodes 실행 결과
최대한의 설명을 코드 블럭 내의 주석으로 달아 놓았습니다.
혹시 이해가 안가거나 추가적인 설명이 필요한 부분, 오류 등의 피드백은 언제든지 환영합니다!
긴 글 읽어주셔서 감사합니다. 연결 리스트 (Linked List) 포스팅을 마칩니다.
참고: C언어로 쉽게 풀어쓴 자료구조 <개정 3판> 천인국, 공용해, 하상국 지음
Task Lists
- Data Structure : 연결 리스트 (Linked List) 란?
- 연결 리스트의 구조
- 연결 리스트의 종류
- 단순 연결 리스트 구현 - C
- 전체 테스트 프로그램 - Singly Linked List
- 원형 연결 리스트 (Circular Linked List)
- 원형 연결 리스트 테스트 프로그램
- 이중 연결 리스트 (Doubly Linked List)
- 이중 연결 리스트의 구현
- 이중 연결 리스트 - 테스트 프로그램
- 연결리스트의 구현 with C Delete_same_nodes



Comments