
[Data Structure]
우선순위 큐(Priority Queue)
우선순위 큐(Priority Queue) 의 소개
우선 순위 큐(Priority Queue) : 우선 순위를 가진 항목들을 저장하는 큐
FIFO(First-In-First-Out) : 선입선출 순서가 아닌
우선 순위(Priority)가 높은 데이터가 먼저 나가게 된다.
스택, 큐, 우선순위 큐사실 가장 일반적인 큐는 우선순위 큐이다.
- 스택이나 큐도 우선순위 큐를 사용하여 구현이 가능하기 때문.
- 배열, 연결리스트 등 여러 형태로 구현이 가능하나 가장 효율적인 구조는 히프(heap)이다.

우선순위 큐 ADT
// 객체 : element 형의 우선 순위를 n개 가진 요소들의 모임
// 연산
create() // 우선 순위 큐를 생성
init(q) // 우선 순위 큐 q를 초기화
is_empty(q) // 우선 순위 큐 q가 비어있는지를 검사
is_full(q) // 우선 순위 큐 q가 포화 상태인지 검사
insert(q, x) // 우선 순위 큐 q에 요소 x를 추가
delete(q) // 우선 순위 큐로부터 가장 우선 순위가 높은 요소를 삭제하고 해당 요소를 반환
find(q) // 우선 순위가 가장 높은 요소를 반환
우선 순위 큐는 0개 이상의 요소 모임이며 각 요소들은 우선 순위 값을 가지고 있다.
가장 중요한 연산
- insert() : 요소의 삽입
- delete() : 요소의 삭제
- 최소 우선 순위 큐: 가장 우선순위가 낮은 요소를 삭제.
- 최대 우선 순위 큐: 가장 우선순위가 높은 요소를 삭제.
다양한 형태로 구현한 우선순위 큐
우선 순위 큐의 구현 - Heap
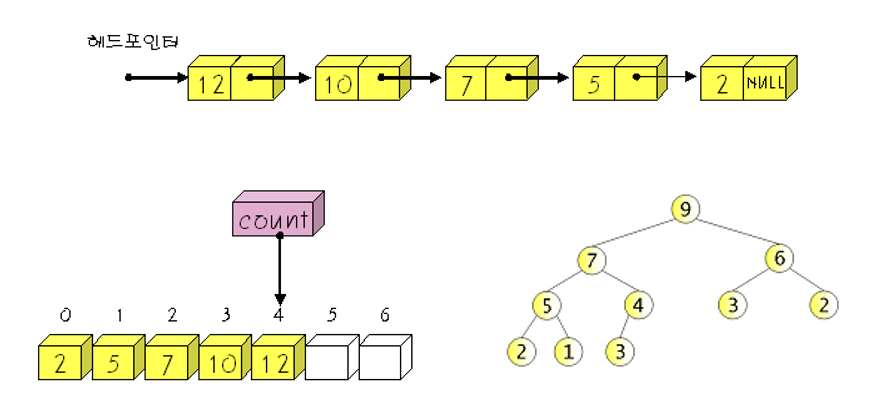
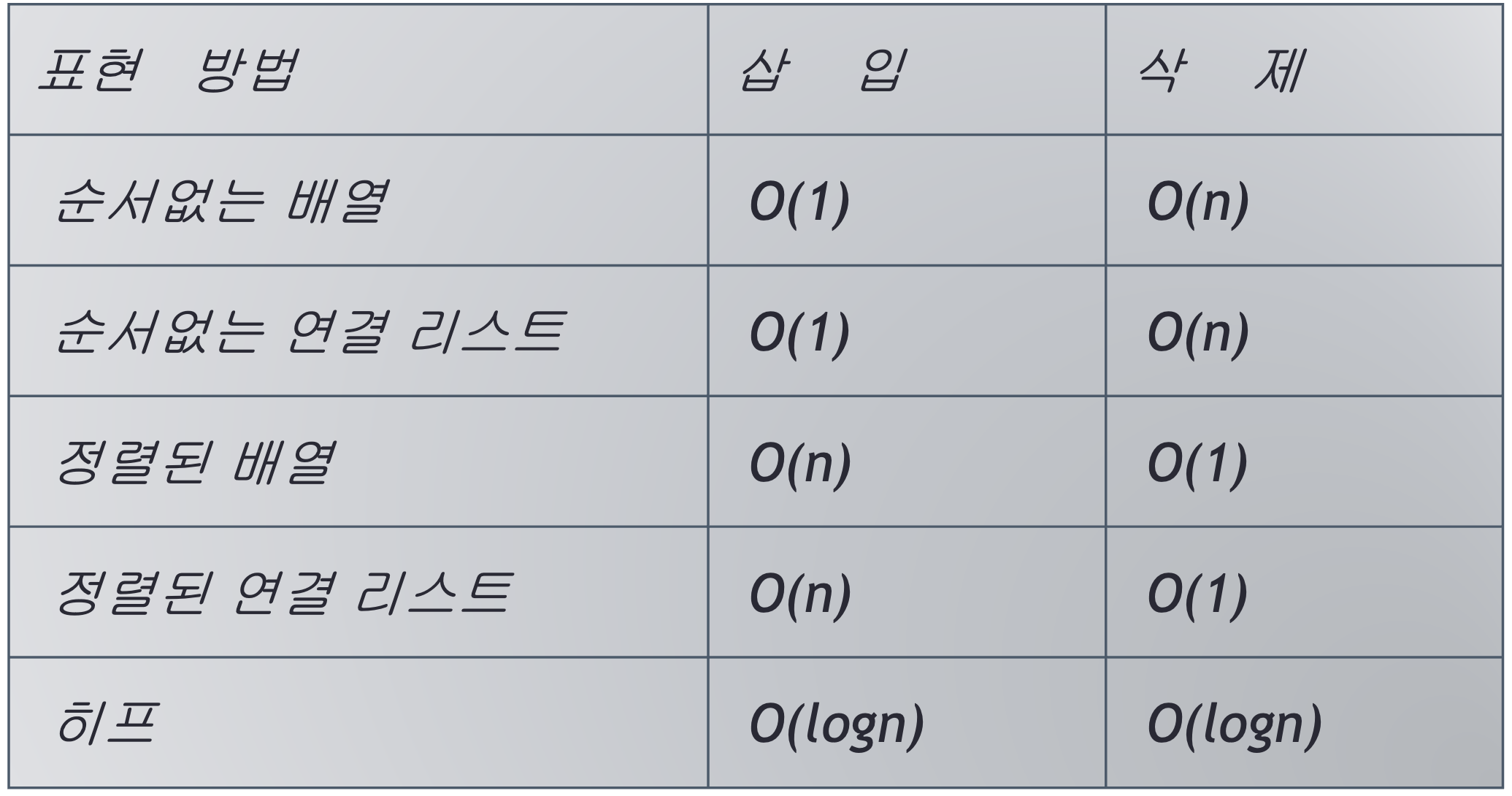
정렬이 되어있지 않은 배열 / 연결리스트를 사용해서 우선순위 큐를 구현
- 삽입은 배열의 맨 끝에 요소를 추가 / 시간 복잡도: O(1)
- 삭제 시에는 가장 우선순위가 높은 요소를 찾아야 함
- 정렬이 되어 있지 않으므로 요소 전체를 탐색 / 시간 복잡도: O(n)
- 요소 삭제 후 이후 요소들을 한 칸씩 앞으로 이동시켜줘야 함
정렬이 되어 있는 배열 / 연결리스트를 사용하여 우선순위 큐를 구현
- 삽입시 적절한 삽입위치를 탐색을 통해 찾은 후 삽입
- 배열의 경우 삭제 시 우선순위에 따라 가장 앞이나 뒤의 요소를 삭제
- 연결리스트의 경우 첫째 노드를 삭제 (가장 우선순위가 높은 요소를 연결리스트의 첫번째 노드로 한다)
우선 순위 큐의 다양한 구현 방법 및 시간복잡도
heap 란?
- 노드의 key들이 다음 식을 만족하는 완전 이진 트리
- key(부모노드) >= key(자식노드)
- 중복된 key 값을 허용.
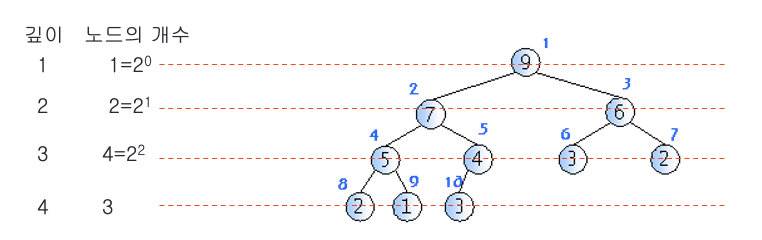
- Heap의 높이
- n개의 노드를 가지고 잇는 히프의 높이는 O(log_2 n)
- 히프는 완전 이진 트리.
- 마지막 레벨 h를 제외하고는 각 레벨 i에 2^(i-1) 개의 노드가 존재.
히프의 높이
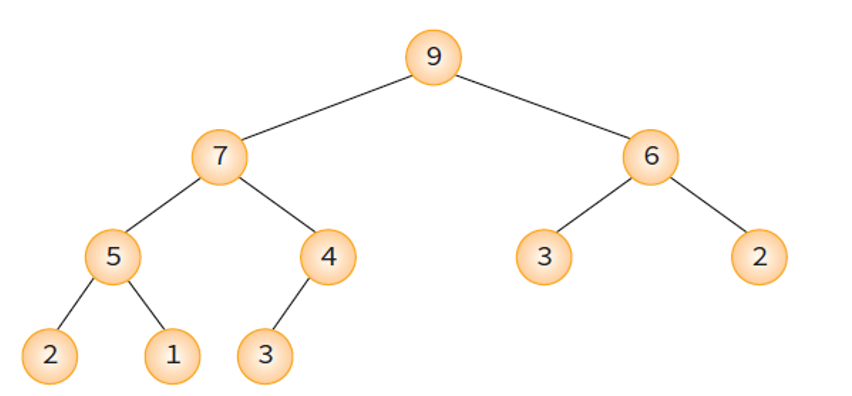
히프(Heap) 트리의 예- 느슨한 정렬 상태를 유지. -> 완전히 정렬이 된 것은 아니지만 어느정도 정렬이 되어있다.
- 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있다는 정도.
- 히프의 목적은 삭제 연산이 수행될 때마다 가장 큰 값을 찾아내는 것. (가장 우선순위가 높은 것은 루트 노드에 있다.)
- Heap의 시간복잡도는 O(log_2 n)으로서 타 방법보다 상당히 효율적이다.
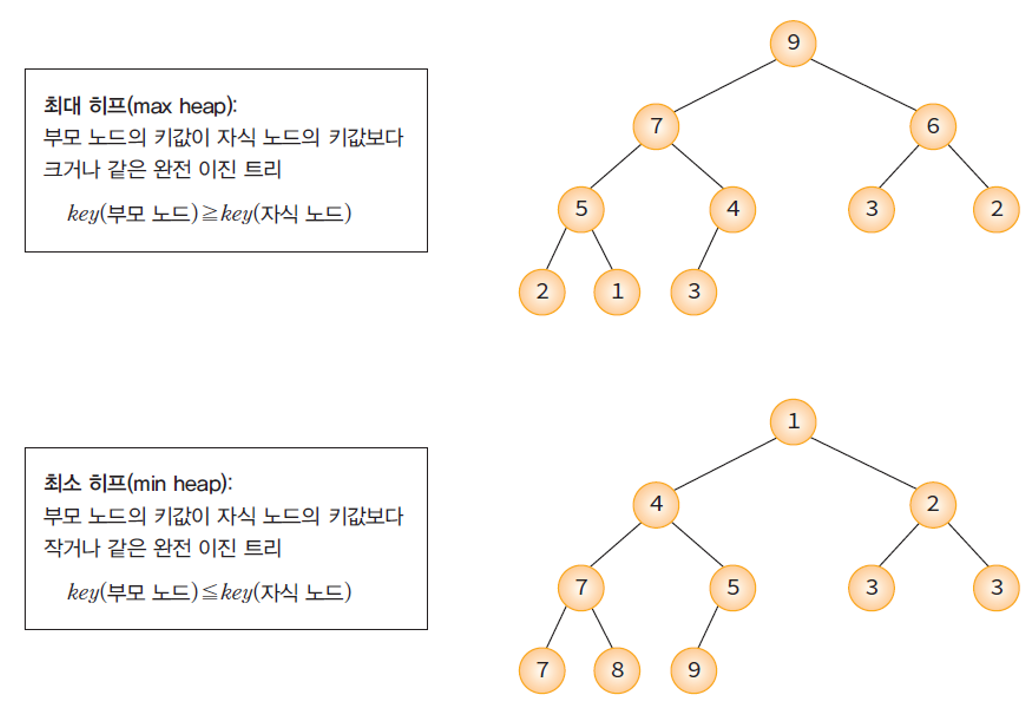
Heap의 종류
- 최대 히프 (Max Heap):
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리.
- key(부모 노드) >= key(자식 노드)
- 최소 히프 (Min Heap):
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- key(부모 노드) <= key(자식 노드)
히프의 종류 두 가지
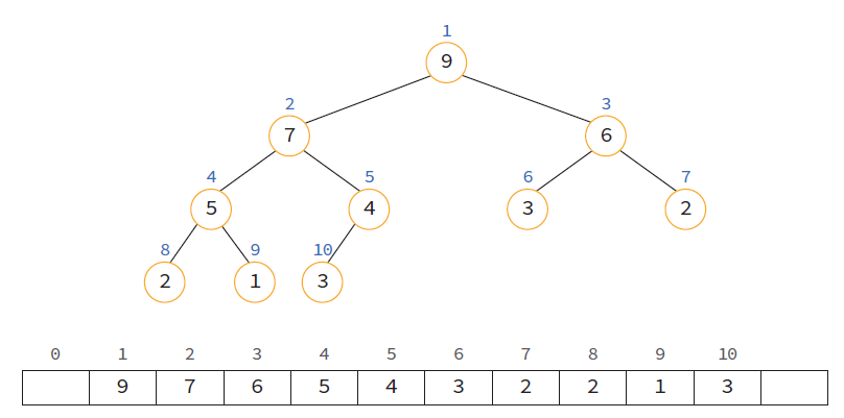
Heap의 구현
Heap는 배열을 이용하여 구현
- 완전 이진 트리이므로 각 노드에 indexing이 가능하다.
- index 로서 0을 사용하게 되면 계산이 복잡해지므로 index는 1부터 사용.
히프의 구현 방법
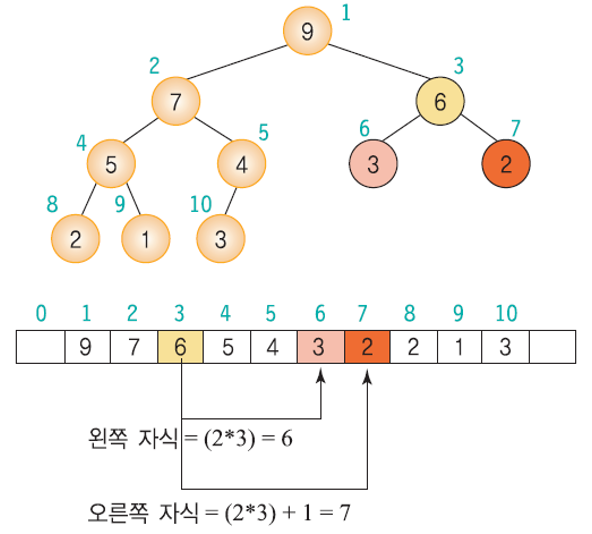
- 부모노드와 자식노드를 찾기 쉽다.
- 왼쪽 자식의 인덱스 : (부모의 인덱스) * 2
- 오른쪽 자식의 인덱스 : (부모의 인덱스) * 2 + 1
- 부모의 인덱스 : (자식의 인덱스) / 2
히프의 특성
Heap의 정의
히프는 1차원 배열로 표현 될 수 있다.
Heap의 각 요소들을 구조체 element로 정의, element의 1차원 배열을 만들어 Heap를 구현한다.
- heap_size : 현재 히프안에 저장된 요소의 개수
#define MAX_ELEMENT 200
// 요소
typedef struct {
int key;
} element;
// 히프
typedef struct {
element heap[MAX_ELEMENT];
int heap_size; // 현재 히프안에 저장된 요소의 개수
} HeapType;
Heap의 삽입 연산 (Up Heap)
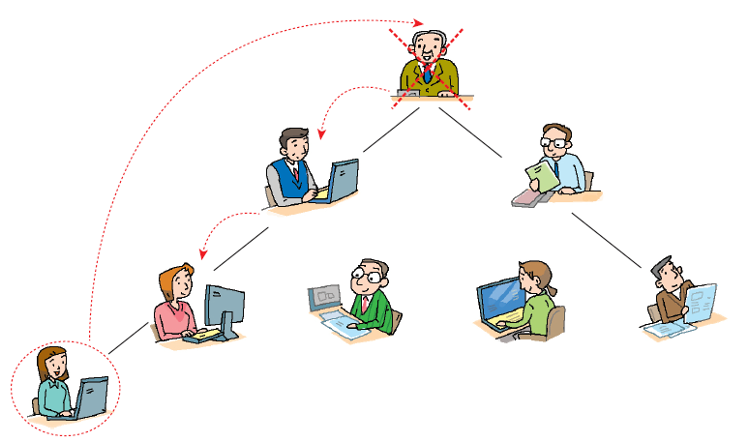
히프의 삽입 연산은 다음의 과정과 비슷하다.
신입 사원이 들어오면 말단 위치에 앉힌다.
신입 사원의 능력을 봐서 점차 위로 승진 시킨다.
- 히프에 새로운 요소가 들어오면 일단 새로운 노드를 히프의 마지막 노드에 이어 삽입.
- 삽입 후 해당 노드를 부모 노드들과 비교 및 교환하여 히프의 성질을 만족시킨다.
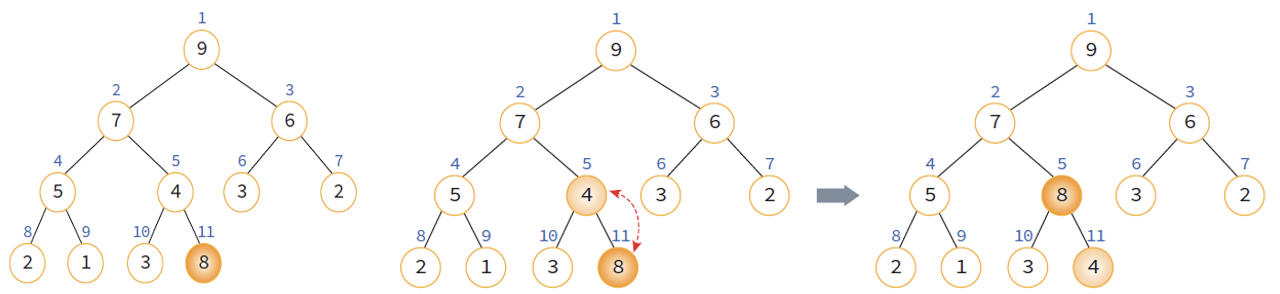
Up Heap 연산
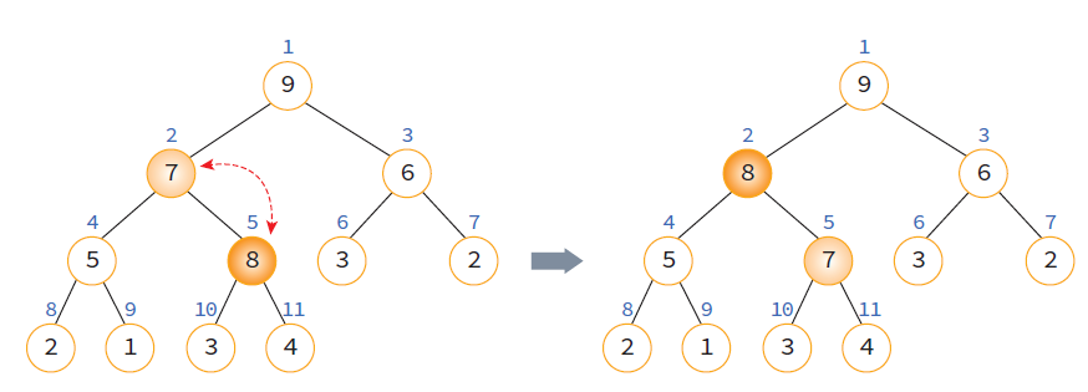
UpHeap 연산 1
UpHeap 연산 2
- 번호 순으로 가장 마지막 위치에 이어 새로운 요소 8이 삽입된다.
- 부모 노드인 4와 비교하여 삽입된 노드 8이 더 크므로 교환.
- 부모 노드 7과 비교하여 삽입 노드 8이 더 크므로 교환.
- 삽입노드 8이 부모노드인 9보다 작으므로 교환을 멈추고 현재 위치에 머무른다.
// Upheap(삽입) 알고리즘 - pseudo code
insert_max_heap(A, key):
// 히프 크기(현재 히프에 저장된 요소의 개수)를 하나 증가시킨다.
heap_size ← heap_size + 1;
i ← heap_size;
A[i] ← key; // 증가된 히프 크기 위치에 새로운 노드를 삽입
// i가 루트 노드가 아니고, i번째 노드가 i의 부모노드보다 크면 실행
while i != 1 and A[i] > A[PARENT(i)] do
A[i] <-> A[PARENT]; // i번째 노드와 해당 노드의 부모 노드를 교환
i ← PARENT(i); // 한 레벨 위로 올라감 (승진)
// Upheap(삽입) 알고리즘 - C code
// 현재 요소의 개수가 heap_size인 히프 h에 item을 삽입.
// 삽입 함수
void insert_max_heap(HeapType *h, element item){
int i;
i = ++(h->heap_size);
// 트리를 거슬러 올라가며 부모노드와 비교
while((i != 1) && (item.key > h->heap[i / 2].key)){
h->heap[i] = h->heap[i / 2].key;
i /= 2;
}
h->heap[i] = item; // 비교가 끝나고 멈춘 자리에 새로운 노드를 삽입.
}
Heap의 삭제 연산 (Down Heap)
히프의 삭제 연산은 다음과 비슷하다.
회사에서 사장의 자리가 비게 되면 제일 말단 사원을 사장 자리로 올린 후 능력에 따라 강등.
- 최대 히프에서의 삭제 : 가장 큰 키 값을 가진 노드를 삭제
- 루트 노드의 삭제
1. 루트 노드를 삭제한다. (가장 큰 key값 / 가장 높은 우선 순위)
2. 마지막 노드를 루트 노드로 이동.
3. 루트에서부터 단말 노드까지의 경로에 위치한 노드들과 비교 및 교환하며 내려가 히프의 성질을 만족.
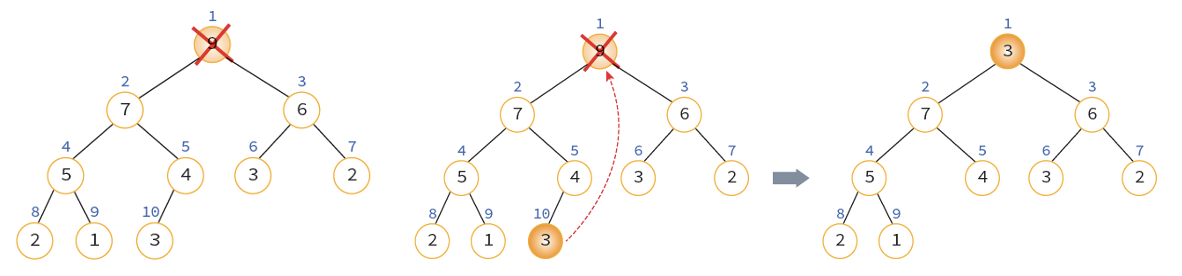
히프에서의 삭제 연산 (Down Heap)
히프에서의 삭제 연산 (Down Heap)
- 루트 노드를 삭제한다.
- 빈 루트 노드 자리에 히프의 마지막 노드를 가져온다.
- 새로운 루트인 3과 하위의 자식 노드들을 비교하며 위치 교환.
- 이때 자식중 더 큰 값과 교환된다 (최대 히프이기 때문에, 최소 히프인 경우 더 작은 값이 루트노드로)
- 적절한 위치를 찾을 때까지 반복.
// Heap의 삭제 연산 (Down Heap) - pseudo code
delete_max_heap(A):
item ← A[1]; // 루트 노드의 삭제 후 반환을 위해 값 임시 복사.
A[1] ← A[heap_size]; // 말단 노드를 루트 노드로 옮김
heap_size ← heap_size - 1; // 히프의 사이즈를 하나 줄인다.
i ← 2; // 루트의 왼쪽 자식 (== 인덱스는 무조건 2) 부터 비교를 시작
while i <= heap_size do // index i가 히프 트리를 벗어나지 않으면 실행
// 좌 / 우 자식 중 더 큰 값의 인덱스를 largest로 옮김
if i < heap_size and A[i+1] > A[i]
then largest ← i+1; // 오른쪽 자식의 인덱스를 largest로 복사
else largest ← i; // 왼쪽 자식이 더 크면 해당 인덱스를 largest로 복사
// largest의 부모 노드가 largest 보다 크면
if A[PARENT(largest)] > A[largest]
the break; // 중지
// largest가 largest의 부모 노드보다 크면
A[PARENT(largest)] <-> A[largest]; // 두 노드를 교환
i ← CHILD(largest); // 한 레벨 밑으로 내려간다. (강등)
return item; // 최대값이었던 루트 노드의 값을 반환
// Heap의 삭제 연산 (Down Heap) - C code
#include <stdio.h>
#include <stdlib.h>
#define MAX_ELEMENT 200
typedef struct {
int key;
} element;
typedef struct {
element heap[MAX_ELEMENT];
int heap_size;
} HeapType;
// Heap 동적 생성
HeapType* create(){
return (HeapType *)malloc(sizeof(HeapType));
}
// Heap 초기화
void init(HeapType *h){
h->heap_size = 0;
}
// 현재 요소의 개수가 heap_size 인 히프 h에 item을 삽입.
// 삽입 함수
void insert_max_heap(HeapType *h, element item){
int i;
i = ++(h->heap_size);
// 트리를 거슬러 올라가며 부모노드와 비교
while((i != 1) && (item.key > h->heap[i / 2].key)){
h->heap[i] = h->heap[i / 2];
i /= 2;
}
h->heap[i] = item; // 비교가 끝나고 멈춘 자리에 새로운 노드를 삽입.
}
// 삭제 함수
element delete_max_heap(HeapType *h){
int parent, child;
element item, temp;
item = h->heap[1];
temp = h->heap[(h->heap_size)--];
parent = 1;
child = 2;
while (child <= h->heap_size) {
// 현재 노드의 자식노드 중 더 큰 값을 찾는다.
// 오른쪽 자식이 더 크면
if((child < h->heap_size) &&
h->heap[child].key < h->heap[child + 1].key){
child++;
}
if (temp.key >= h->heap[child].key) break;
// 한 단계 아래로 이동
h->heap[parent] = h->heap[child];
parent = child;
child *= 2;
}
h->heap[parent] = temp;
return item;
}
int main(void) {
element e1 = { 10 }, e2 = { 5 }, e3 = { 30 };
element e4, e5, e6;
HeapType* heap;
heap = create(); // 히프 생성
init(heap); // 초기화
// 삽입
insert_max_heap(heap, e1);
insert_max_heap(heap, e2);
insert_max_heap(heap, e3);
// 삭제
e4 = delete_max_heap(heap);
printf("< %d > ", e4.key);
e5 = delete_max_heap(heap);
printf("< %d > ", e5.key);
e6 = delete_max_heap(heap);
printf("< %d > \n", e6.key);
free(heap);
return 0;
}
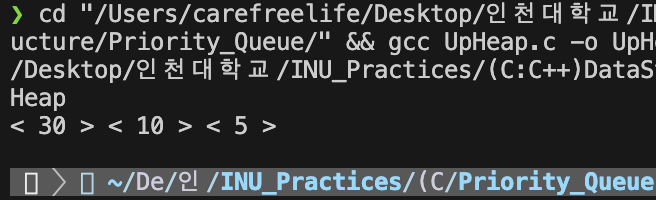
Upheap, Downheap (삽입, 삭제) 실행 결과히프의 복잡도 분석
- 삽입 연산
- 최악의 경우, 루트 노드까지 올라가야 한다.
- 트리의 높이에 해당하는 비교 및 이동 연산이 필요.
- O(log_2 n)
- 삭제 연산
- 최악의 경우 말단 노드까지 내려가야 한다.
- 트리의 높이에 해당하는 비교 및 이동 연산이 필요.
- O(log_2 n)
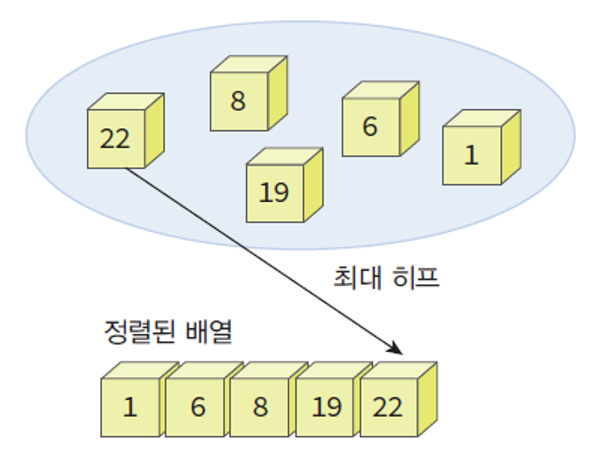
히프 정렬 (Heap Sort)
- 히프를 이용하면 정렬이 가능.
- 정렬해야 할 n개의 요소들을 최대 히프에 삽입.
- 한번에 하나씩 요소를 히프에서 삭제하여 저장.
- 최소 히프인 경우 삭제되는 요소들은 값이 증가되는 순서.
- 하나의 요소를 히프에 삽입 / 삭제하는 데에 O(log_2 n) 소요
n개의 요소를 정렬하는데 O(n * log_2 n) 소요 (빠른 편)
히프 정렬이 최대로 유용한 경우:
- 전체 자료를 정렬하는 것이 아닌 가장 큰 값 몇 개가 필요한 경우.
히프 정렬
// HeapSort - C code
void heap_sort(element a[], int n){
int i;
HeapType *h;
h = create();
init(h);
for(i = 0; i < n; i++){
insert_max_heap(h, a[i]);
}
for(i = (n-1); i >= 0; i--){
a[i] = delete_max_heap(h);
}
free(h);
}
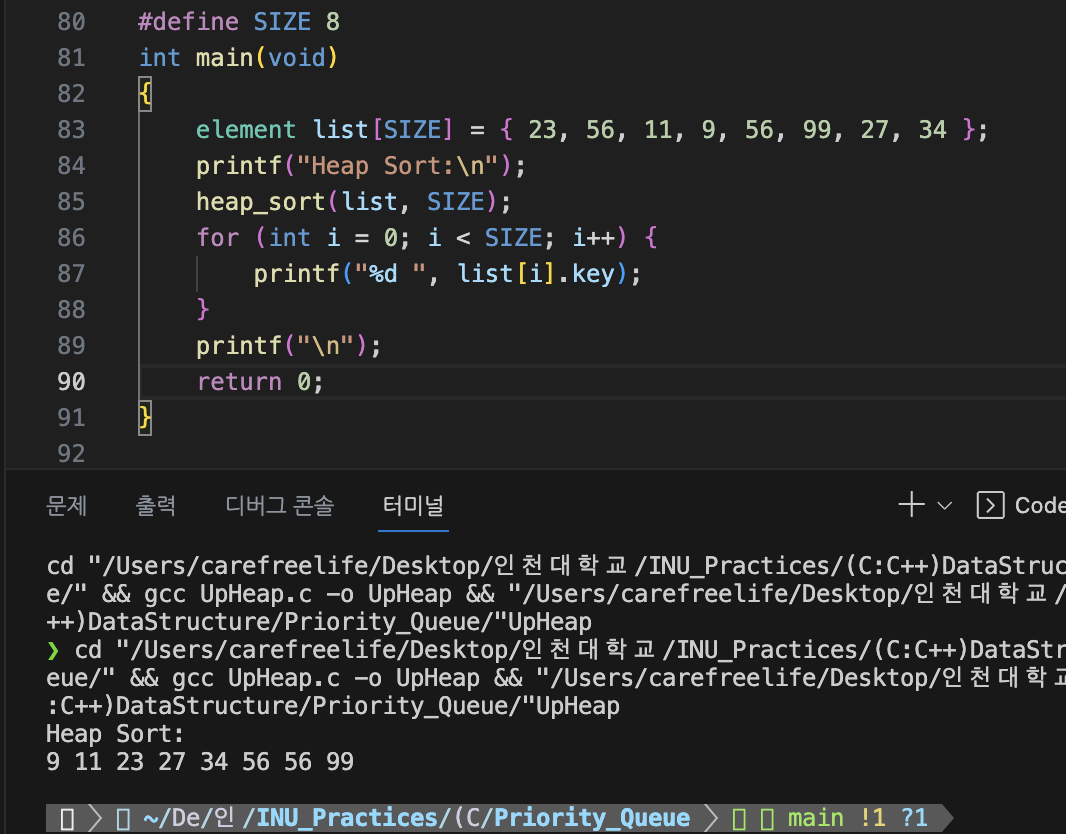
#define SIZE 8
int main(void)
{
element list[SIZE] = { 23, 56, 11, 9, 56, 99, 27, 34 };
printf("Heap Sort:\n");
heap_sort(list, SIZE);
for (int i = 0; i < SIZE; i++) {
printf("%d ", list[i].key);
}
printf("\n");
return 0;
}
히프 정렬 - 실행 결과
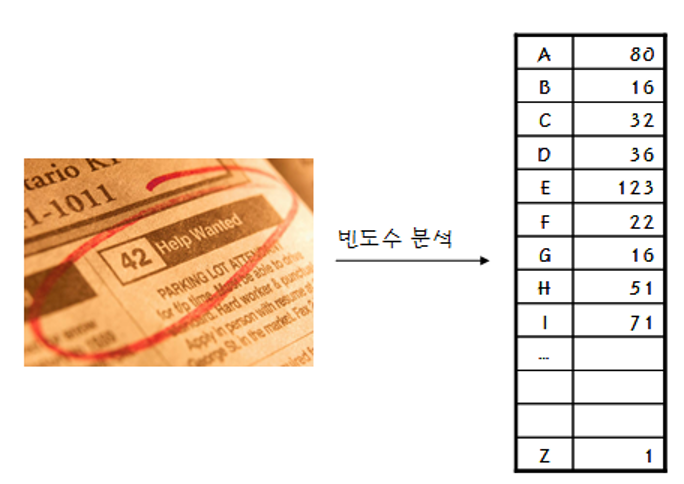
허프만 코드 (Huffman codes)
이진 트리는 각 글자의 빈도가 알려져 있는 메시지의 내용을 압축하는데 사용될 수 있다.
이때 사용되는 이진 트리 : 허프만 코딩 트리
허프만 코딩 트리
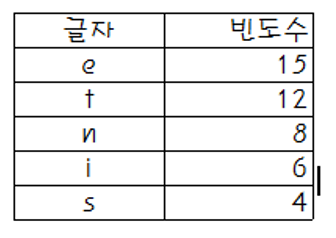
주어진 텍스트가 e, t, n, i, s 의 5개 글자로만 이루어졌다고 가정
각 글자의 빈도수는 아래의 그림과 같다고 가정 (총 45회)
- 각 글자는 3bit(1, 0 으로 이루어진 세 자릿수)로 표현이 가능하므로 (3 * 45 = 145 bit) 가 필요
일반적인 텍스트의 표현 방법
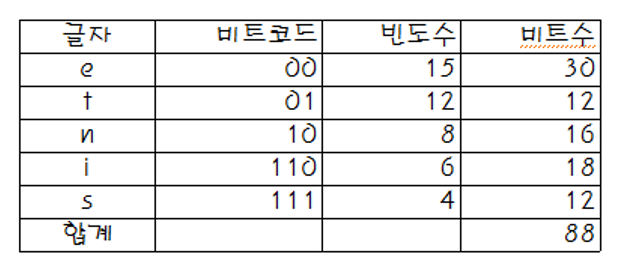
그러나 자주 나오는 글자는 2bit, 그렇지 않은 경우 3bit로 표현하는 경우 (아래 그림) 88bit 로 표현이 가능해짐.
허프만 코딩 트리를 사용하여 압축한 텍스트의 모습
- 이 경우 비트 코드는 혼동을 주면 안되며(중복 x), 글자의 비트 코드는 알려져 있어야 한다.
- 이러한 압축법을 허프만 코딩이라고 하고, 글자에 해당하는 비트 코드들을 허프만 코드라고 한다.
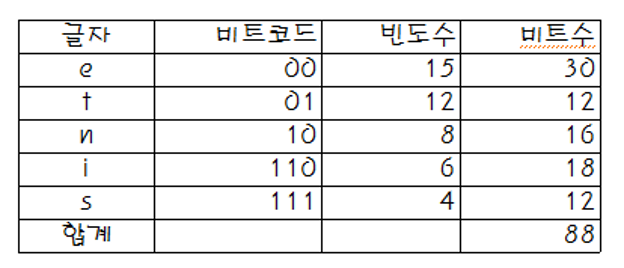
허프만 코드 예시
01000010 (2 or 3 bit)
- 어디서 끊을 것인가? 01 / 010
- 이 경우 테이블에 010이 존재하지 않으므로 01 임을 알 수 있다. 01 = t
- 다음 코드는 00 / 000
- 마찬가지로 테이블에 000이 없으므로 00 임을 알 수 있다. 00 = e
- 나머지도 마찬가지로 00 = e, 10 = n
- 결과는 teen 임을 알 수 있다.
- 위의 조건이 성립하기 위해서 모든 허프만 코드는 다른 허프만 코드의 첫 부분이 될 수 없다.
- 한 코드가 다른 코드의 첫 부분(집합)이 된다면 경계선을 나눌 수 없어 코드의 판별이 불가능.
*오류 : 't'의 비트수는 24(12 * 2).
허프만 코드 생성 절차
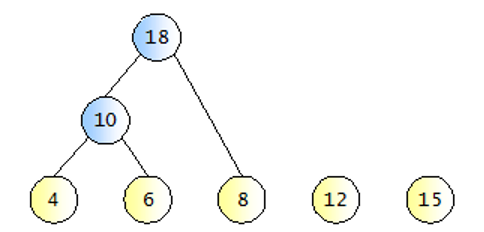
- 모든 문자를 출현 빈도수에 따라 나열
- 목록에서 가장 빈도가 낮은 문자를 두 개 골라 이진트리 생성. (최소 힙 사용)
- 생성한 이진트리의 루트는 두 문자의 빈도수의 합
- 목록에서 위의 이진트리에서 사용된 단말노드 두 개를 제외하고 루트 노드를 목록에 삽입.
- 목록에 1개만 남을 때까지 반복.
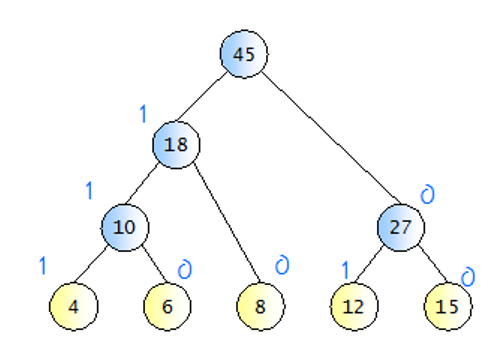
- 왼쪽 자식은 1, 오른쪽 자식은 0을 나타냄.
- 완성된 이진트리의 루트 노드에서 각 단말노드 까지 내려가며 (1 / 0) 을 읽으면 해당 단말 노드의 허프만 코드가 된다.
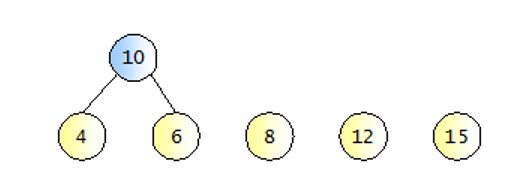
허프만 코드 생성 절차 1, 2
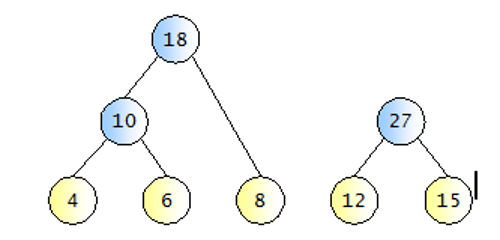
허프만 코드 생성 절차 3, 4
허프만 코드의 구현
#include <stdio.h>
#include <stdlib.h>
#define MAX_ELEMENT 200
typedef struct TreeNode {
int weight;
char ch;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
typedef struct {
TreeNode* ptree;
char ch;
int key;
} element;
typedef struct {
element heap[MAX_ELEMENT];
int heap_size;
} HeapType;
// 생성 함수
HeapType* create()
{
return (HeapType*)malloc(sizeof(HeapType));
}
// 초기화 함수
void init(HeapType* h)
{
h->heap_size = 0;
}
// 현재 요소의 개수가 heap_size인 히프 h에 item을 삽입한다.
// 삽입 함수
void insert_min_heap(HeapType* h, element item)
{
int i;
i = ++(h->heap_size);
// 트리를 거슬러 올라가면서 부모 노드와 비교하는 과정
while ((i != 1) && (item.key < h->heap[i / 2].key)) {
h->heap[i] = h->heap[i / 2];
i /= 2;
}
h->heap[i] = item; // 새로운 노드를 삽입
}
// 삭제 함수
element delete_min_heap(HeapType* h)
{
int parent, child;
element item, temp;
item = h->heap[1];
temp = h->heap[(h->heap_size)--];
parent = 1;
child = 2;
while (child <= h->heap_size) {
// 현재 노드의 자식노드중 더 작은 자식노드를 찾는다.
if ((child > h->heap_size) &&
(h->heap[child].key) > h->heap[child + 1].key)
child++;
if (temp.key < h->heap[child].key) break;
// 한 단계 아래로 이동
h->heap[parent] = h->heap[child];
parent = child;
child *= 2;
}
h->heap[parent] = temp;
return item;
}
// 이진 트리 생성 함수
TreeNode* make_tree(TreeNode* left,
TreeNode* right)
{
TreeNode* node =
(TreeNode*)malloc(sizeof(TreeNode));
node->left = left;
node->right = right;
return node;
}
// 이진 트리 제거 함수
void destroy_tree(TreeNode* root)
{
if (root == NULL) return;
destroy_tree(root->left);
destroy_tree(root->right);
free(root);
}
int is_leaf(TreeNode* root)
{
return !(root->left) && !(root->right);
}
void print_array(int codes[], int n)
{
for (int i = 0; i < n; i++)
printf("%d", codes[i]);
printf("\n");
}
void print_codes(TreeNode* root, int codes[], int top)
{
// 1을 저장하고 순환호출한다.
if (root->left) {
codes[top] = 1;
print_codes(root->left, codes, top + 1);
}
// 0을 저장하고 순환호출한다.
if (root->right) {
codes[top] = 0;
print_codes(root->right, codes, top + 1);
}
// 단말노드이면 코드를 출력한다.
if (is_leaf(root)) {
printf("%c: ", root->ch);
print_array(codes, top);
}
}
// 허프만 코드 생성 함수
void huffman_tree(int freq[], char ch_list[], int n)
{
int i;
TreeNode *node, *x;
HeapType* heap;
element e, e1, e2;
int codes[100];
int top = 0;
heap = create();
init(heap);
for (i = 0; i<n; i++) {
node = make_tree(NULL, NULL);
e.ch = node->ch = ch_list[i];
e.key = node->weight = freq[i];
e.ptree = node;
insert_min_heap(heap, e);
}
for (i = 1; i<n; i++) {
// 최소값을 가지는 두개의 노드를 삭제
e1 = delete_min_heap(heap);
e2 = delete_min_heap(heap);
// 두개의 노드를 합친다.
x = make_tree(e1.ptree, e2.ptree);
e.key = x->weight = e1.key + e2.key;
e.ptree = x;
printf("%d+%d->%d \n", e1.key, e2.key, e.key);
insert_min_heap(heap, e);
}
e = delete_min_heap(heap); // 최종 트리
print_codes(e.ptree, codes, top);
destroy_tree(e.ptree);
free(heap);
}
int main(void)
{
char ch_list[] = { 's', 'i', 'n', 't', 'e' };
int freq[] = { 4, 6, 8, 12, 15 };
huffman_tree(freq, ch_list, 5);
return 0;
}
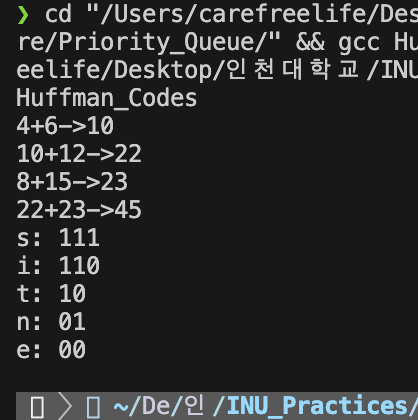
허프만 코드 - 실행 결과
쉘

최대한의 설명을 코드 블럭 내의 주석으로 달아 놓았습니다.
혹시 이해가 안가거나 추가적인 설명이 필요한 부분, 오류 등의 피드백은 언제든지 환영합니다!
긴 글 읽어주셔서 감사합니다. 포스팅을 마칩니다.
참고: C언어로 쉽게 풀어쓴 자료구조 <개정 3판> 천인국, 공용해, 하상국 지음
Task Lists
- [x]
- [x]
- [x]
- [x]
- [x]
- [x]
- [x]
- [x]
- [x]



Comments