
Data Structure - Tree(자료구조 - 트리란?)
1. 트리의 개념 (Tree)
1-1. 트리의 개념

이미지 출처자료 구조의 트리(Tree). 나무를 거꾸로 엎어놓은 것 같은 모습을 하고 있다.
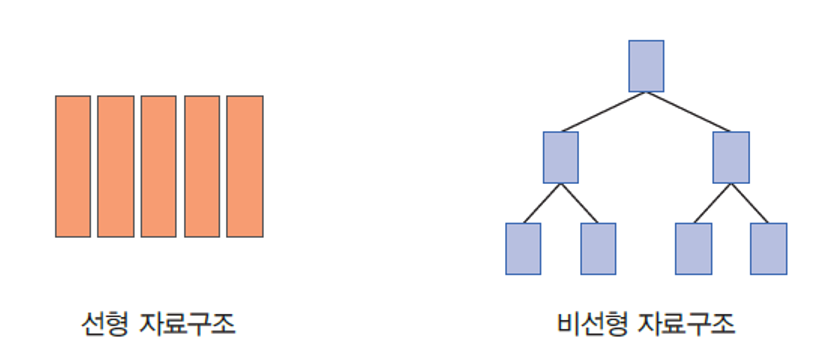
이전에 배운 선형 자료 구조와 달리 데이터 간의 계층이 존재한다면
우리는 트리(Tree)라는 자료구조를 사용해야 한다.
- 부모 - 자식 관계를 가진 노드들로 이루어져 있다.
- 계층적인 자료구조(hierarchical structure):
- 트리(Tree)
- 가계도, 컴퓨터의 디렉토리 구조 등
- 선형 자료 구조 (linear data structure):
- 리스트, 스택, 큐 등
요즘 가장 큰 이슈가 되고 있는 인공지능(AI)도 트리를 사용한다.
대표적인 것이 결정 트리(decision tree)이다.
결정 트리는 인간의 의사 결정 구조를 표현하는 한 가지 방법이다.
1-2. 트리의 용어
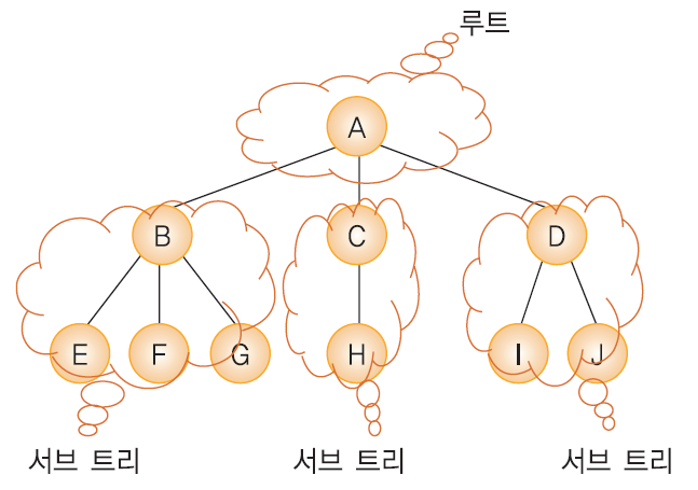
트리(Tree)의 모습.
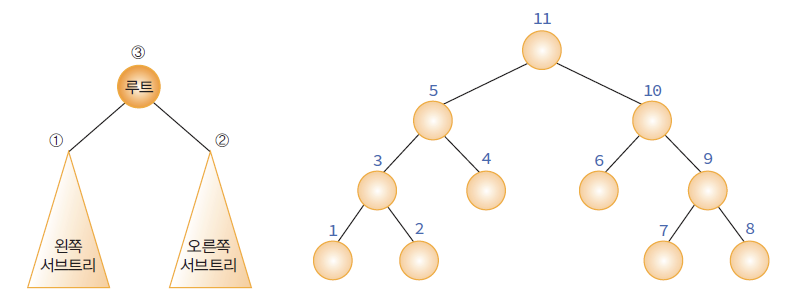
- 트리는 한 개 이상의 노드로 이루어진 유한 집합.
- 트리의 최상단에 위치하는 하나의 노드는 루트노드(Root Node)라고 불리며,
- 그 하위의 나머지 노드들은 서브트리(Sub Tree) 라고 불린다.
- 노드 (node) : A, B, C, D, E, F, G, H, I, J
- 루트 노드 : A
- A의 서브 트리 : {B, E, F, G}, {C, H}, {D, I, J} 와 같은 3개의 집합.
- B의 서브 트리 : {E}, {F}, {G}
- 위 처럼 루트 노드와 서브 트리는 자식 노드가 존재 하는 한 하위로 내려가며 계속 분류된다.
- 간선 (Edge) : 루트와 서브 트리를 잇는 선.
- 노드들 간에는 부모 관계, 형제 관계, 조상 관계가 존재.
- A는 B의 부모 노드(Parent node)가 된다.
- 마찬가지로 B는 A의 자식 노드(Children node)가 된다.
- B, C, D는 형제 관계(Sibling)이다.
- 조상 노드(Ancestor node) : 루트 노드에서 임의의 노드 까지의 경로를 이루고 있는 노드들.
- 후손 노드(Descendent node) : 임의의 노드 하위에 연결된 모든 노드들. (어떤 노드의 서브 트리에 속하는 모든 노드들)
- 단말 노드(Terminal node / Leaf node) : 자식 노드가 없는 트리의 최하위 노드. (<–> 비단말 노드)
- 노드의 차수(degree) : 어떤 노드가 가지고 있는 자식 노드의 개수.
- (A의 경우 B, C, D의 세 자식을 가지고 있으므로 deg(A) = 3 이 된다.)
- 단말 노드의 경우 자식이 없으므로 차수는 0이 된다.
- 트리에서의 레벨(level)은 트리의 각 층에 번호를 나타낸다.
- 루트의 레벨은 1이고, 한 층씩 내려갈수록 레벨은 1씩 증가한다.
- (루트의 레벨은 책 및 사람마다 0부터 시작하는 경우도 있다.)
- A의 레벨은 1, B의 레벨은 2이다.
- 트리의 높이(height) : 트리가 가지고 있는 최대 레벨
- 위 트리의 레벨은 3.
- 트리들의 집합 : Forest
1-3. 트리의 종류
트리의 종류에는 크게 이진 트리(binary tree)와 일반 트리가 있다.
이진 트리의 소개 (Binary Tree)
----------------------------------------------------- 이진 트리는 다음과 같이 정의된다. ----------------------------------------------------- 1. 공집합이거나, 2. 루트와 왼쪽 서브 트리, 오른쪽 서브 트리로 구성된 노드들의 유한 집합. 3. 이진 트리의 서브 트리들은 모두 이진 트리여야 함. -----------------------------------------------------
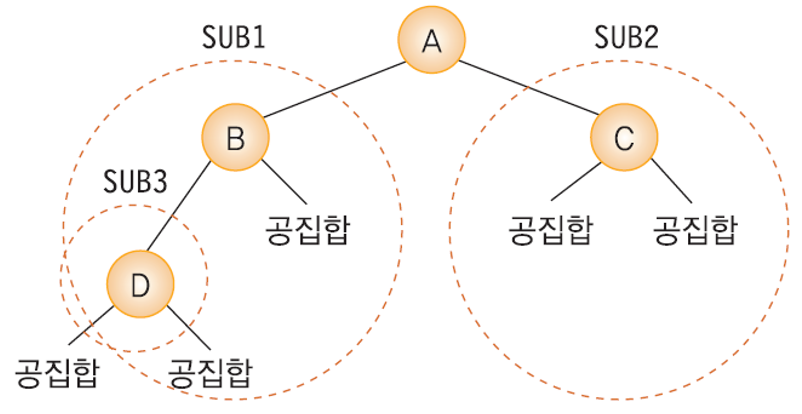
이진 트리의 검증
- 이진 트리 :
- 모든 노드가 2개의 서브 트리를 가지고 있는 트리.
- 서브 트리는 공집합일수 있다.
- 일반 트리와는 다르게 이진트리는 노드를 하나도 갖지 않을 수도 있다.
- 이진트리의 노드에는 최대 2개 까지의 자식 노드가 존재한다.
- 모든 노드의 차수가 2 이하. -> 구현하기가 편리한 장점
- 이진 트리에는 서브 트리간의 순서가 존재한다.
- 왼쪽 서브트리와 오른쪽 서브트리를 구분한다.
- 모든 노드가 2개의 서브 트리를 가지고 있는 트리.
2-1. 이진 트리의 성질
이진 트리의 성질 1
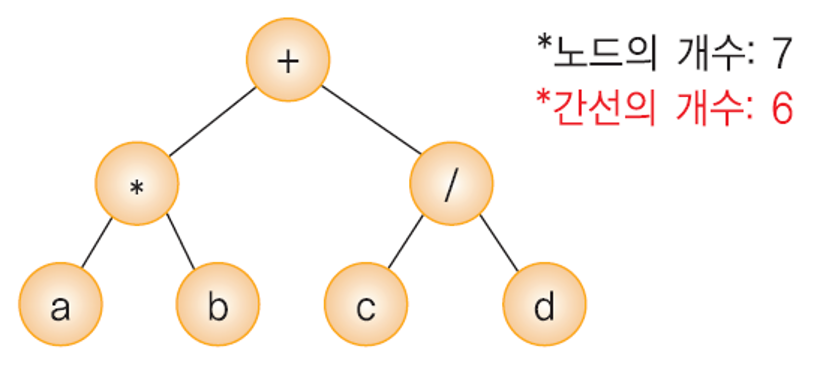
- 노드의 개수가 n개 이면 간선(edge)의 개수는 n-1 개.
- [why ?]
- 이진트리에서의 노드는 루트를 제외하면 정확하게 하나의 부모 노드를 가진다.
- 부모와 자식 간에는 정확하게 하나의 간선만이 존재 하므로 간선의 개수는 항상 n-1 개가 된다.
이진 트리의 성질 2
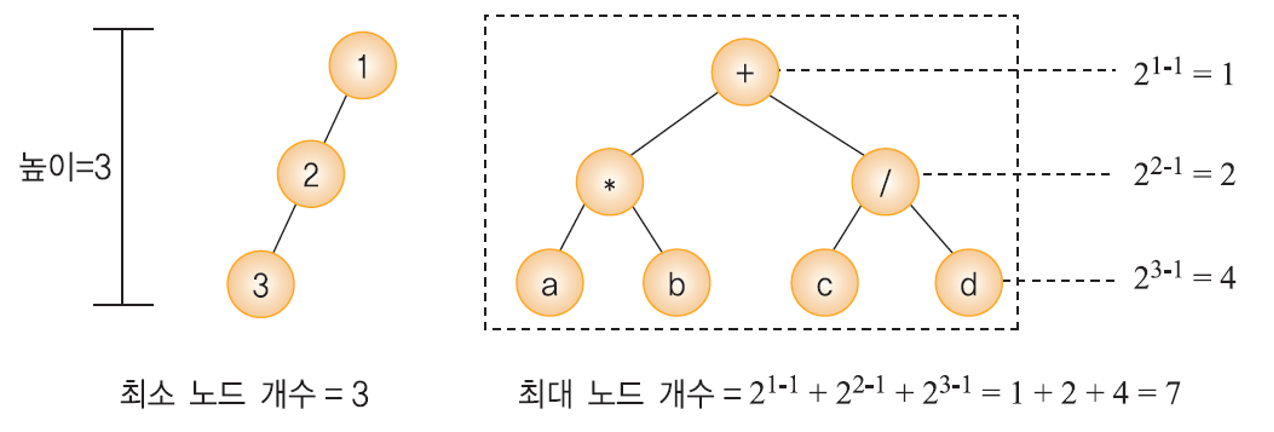
- 높이가 최대 h인 이진트리의 경우, 최소 h개의 노드를 가지며 최대 2^h-1개의 노드를 가진다.
- [why ?]
- 한 레벨에는 적어도 하나의 노드가 존재.
- 높이가 h인 이진트리는 적어도(최소) h개의 노드를 가진다. = 경사 이진트리
- 하나의 노드는 최대 2개의 자식 노드를 가질 수 있다.
- 따라서, 레벨 i에서의 최대 노드 개수는 2^(i-1) 이 된다.
- 그러므로, 아래와 같이 전체 노드의 최대 개수를 구할 수 있는 식이 완성된다.
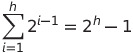
이진 트리의 최대 노드 개수 (전체)
이진 트리의 성질 3
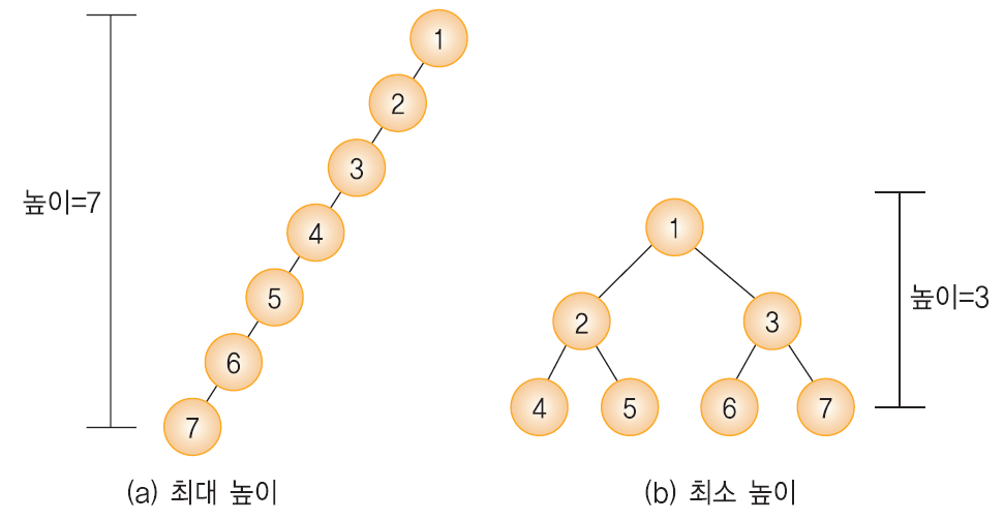
- n개의 노드를 가지는 이진 트리의 높이
[why ?]
- 최대 n
- 레벨 당 최소 하나의 노드가 존재 해야 하므로 n개의 노드 존재 시 가능한 최대 높이는 n이다.
- 최소 ⌈log(n+1)⌉
- 높이 h의 이진 트리가 가질 수 있는 노드의 최대값은 2^h - 1
- n <= 2^h - 1 의 부등식이 성립 할 수 있다.
- 양 변에 log를 취하여 정리 : h >= log(n+1)
- h는 정수이어야 하므로 h >= ⌈log(n+1)⌉ 와 같이 올림 연산을 취해준다.
- 최대 n
2-2. 이진 트리의 분류
이진 트리의 분류
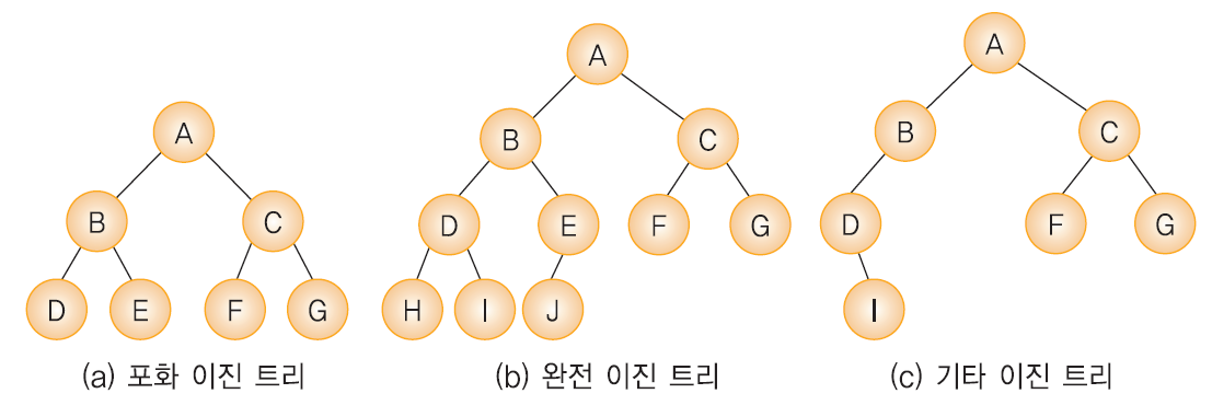
1. 포화 이진 트리 (full binary tree)
이진 트리의 분류
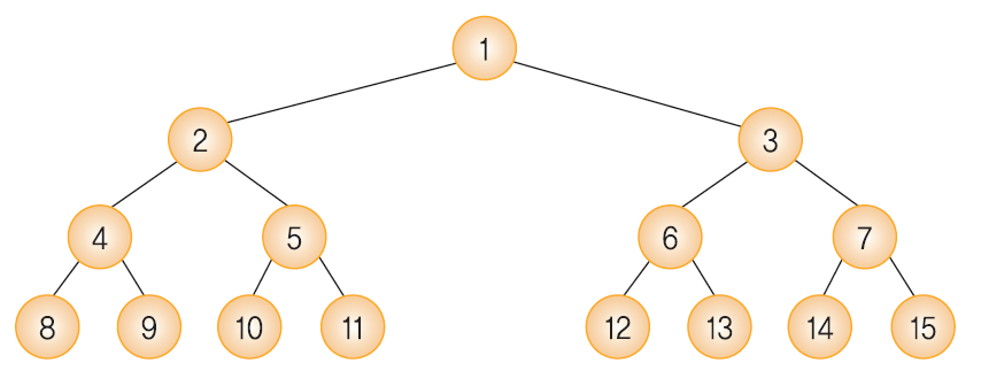
- 말 그대로 이진 트리의 각 레벨 마다의 최대 노드 만큼 꽉 채워져 있는 이진트리이다.
- 높이가 k인 포화 이진트리는 정확히 2^k - 1 개의 노드를 가진다.
- 일반적으로 포화이진트리의 노드 개수는 아래와 같이 계산된다.
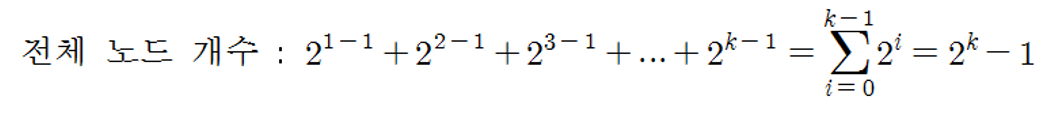
포화 이진 트리에서의전체 노드 개수 = 2^(1-1) + 2^(2-1) + 2^(3-1) + 2^(4-1) = 2^4 - 1 = 15
- 포화 이진 트리는 위 사진과 같이 번호를 붙일 수 있으며, 레벨 단위로 왼쪽에서 오른쪽으로 부여한다.
- 포화 이진 트리에서의 번호는 항상 일정하다. - 루트 노드의 오른쪽 자식 번호는 항상 ‘3’이다.
2. 완전 이진 트리 (full binary tree)
완전 이진 트리의 모습
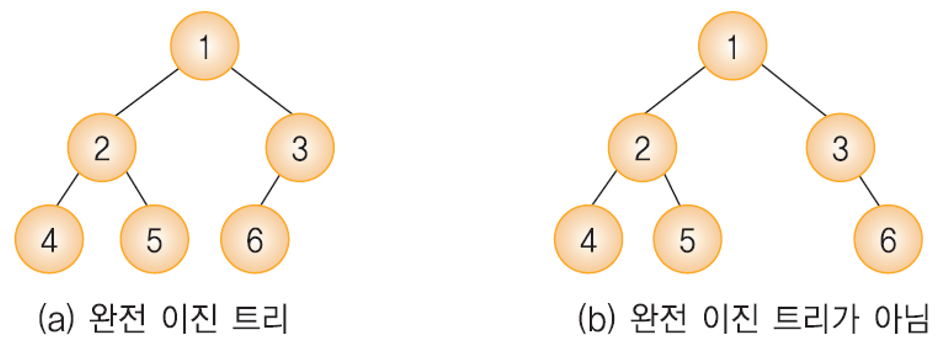
- 완전 이진 트리는 높이가 k일때 레벨 1, 즉 루트 노드 부터 k-1 즉 leaf 노드 전 레벨까지 가능한 모든 노드가 채워져 있고, 마지막 레벨 k에서는 왼쪽부터 오른쪽으로 노드가 순서대로 채워져 있는 이진트리이다.
- 마지막 레벨에서는 노드가 꽉 차있지 않아도 되지만, 중간에 빈 곳이 있으면 안된다. (왼쪽 부터 쭉 채워져 있어야 한다.)
- 포화이진트리는 항상 완전이진트리. 그 반대는 성립하지 않는다.
- 포화이진트리의 노드 번호와 완전이진트리의 노드 번호는 1대1로 대응한다.
- 위 그림의 a는 완전이진트리 이지만, b는 마지막 레벨에서 중간(3의 왼쪽 자식)이 비어있으므로 완전이진트리가 아니다.
이진 트리의 표현
이진 트리를 컴퓨터 프로그램 안에서 어떻게 표현 할 수 있는지 알아보자.
다음의 두 가지 방법이 있다.
1. 배열을 이용하는 방법
2. 포인터를 이용하는 방법
배열 표현법
- 배열을 이용하는 방법은 주로 포화이진트리 / 완전이진트리에서 주로 사용되는 방법 (일반 이진트리에서도 사용은 가능)
- 저장하고자 하는 이진 트리를 완전이진트리라 가정.
- 이진트리의 깊이가 k이면 최대 2^k - 1 개의 공간을 연속적으로 할당한다.
- 완전이진트리의 번호대로 노드들을 저장한다.
이진 트리의 배열 표현법
- 그림 a를 보면, 트리의 각 노드에 번호가 먼저 부여되고, 해당 번호를 index로 하여 배열에 순차적으로 저장된다.
- 포화이진트리 및 완전이진트리의 경우에는 노드가 번호 순으로 전부 존재하므로 배열의 중간에 빈 공간이 생기지 않는다.
- 간선의 밀도(density)가 높다면 배열 표현법을 사용하자. - 극단적인 예로 경사이진트리와 같은 일반 이진트리의 경우에는 각 레벨마다 빈 노드가 존재하므로 배열 표현법을 사용시 많은 메모리의 누수가 발생한다.
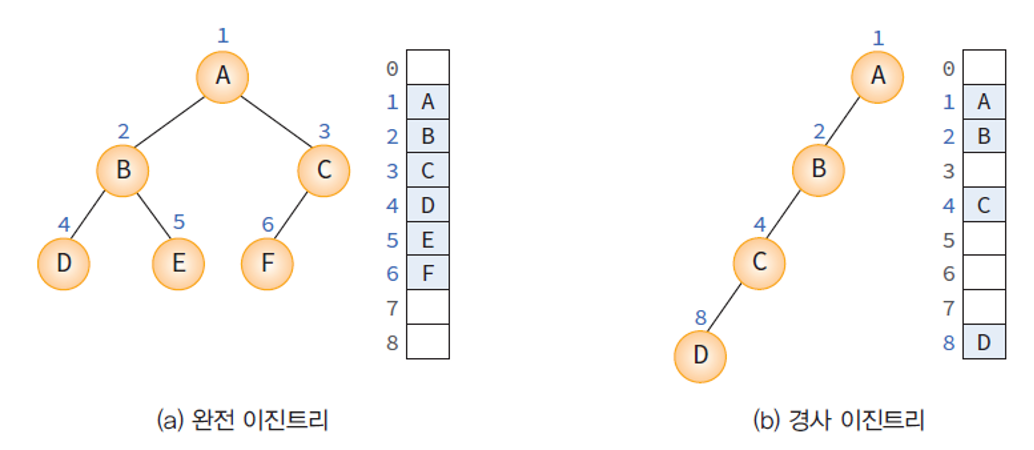
배열 표현법에서는 인덱스만 알면 노드의 부모나 자식을 쉽게 알 수 있으며 다음과 같은 공식이 존재한다.
노드 i의 부모노드 인덱스 = i/2
노드 i의 왼쪽 자식 노드 인덱스 = 2 * i
노드 i의 부모노드 인덱스 = 2 * i + 1
인덱스 0을 사용하지 않는 편이 계산을 간단하게 만들기 때문에 index[0]은 사용하지 않는다.
링크 표현법
- 트리에서의 노드가 구조체로 표현되고, 각 노드가 포인터를 가지고 있다.
- 해당 포인터를 이용하여 노드와 노드를 연결하는 방법이다.
이진 트리 - 링크 표현법
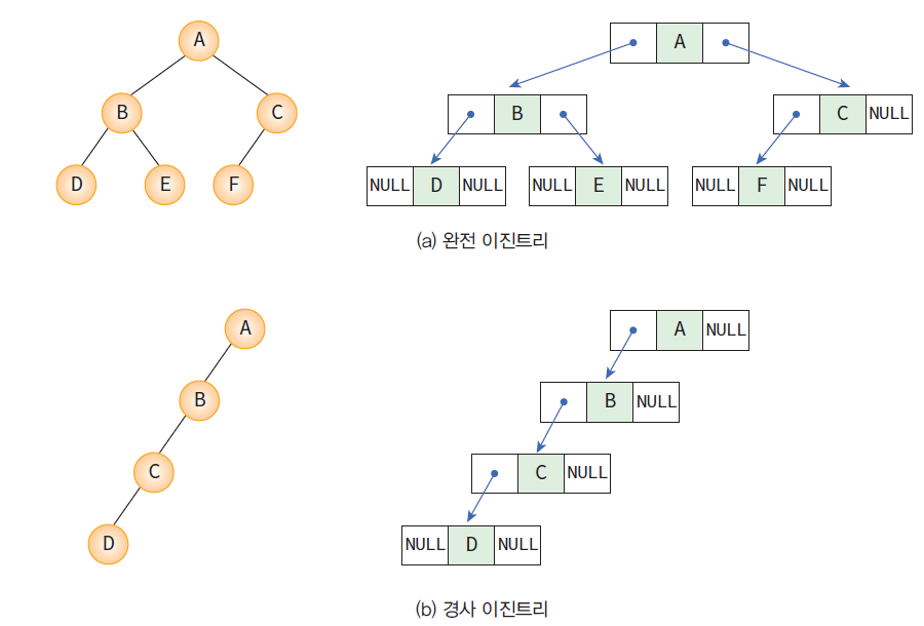
- 각 노드의 모습을 보면, 노드마다 3개의 필드를 가지는 것을 볼 수 있다.
- 데이터 필드 : 데이터를 저장
- 왼쪽 포인터 필드 : 왼쪽 자식 노드를 가리키는 포인터 필드
- 오른쪽 포인터 필드 : 오른쪽 자식 노드를 가리키는 포인터 필드
- 좌우의 포인터 필드를 사용하여 부모 노드와 자식 노드를 연결한다.
노드를 C언어의 구조체와 포인터를 사용하여 정의해보자.
// 노드의 정의
// 구조체를 사용하여 노드의 구조를 정의
// 포인터를 사용하여 링크의 정의
// TreeNode 는 트리 노드에 대한 타입을 새로 정의 한 것.
typedef struct TreeNode {
int data;
struct TreeNode* left;
struct TreeNode* right;
} TreeNode;
링크로 표현된 트리는 루트노드(최상단 노드)를 가리키는 포인터만 있으면 트리 내부의 모든 노드들에 접근할 수 있다.
C언어와 링크 표현법을 사용하여 간단하게 이진트리를 구성해보자.
#include<stdio.h>
#include<stdlib.h>
#include<memory.h>
typedef struct TreeNode {
int data;
struct TreeNode* left;
struct TreeNode* right;
} TreeNode;
int main(void) {
// 노드 세개 생성
TreeNode *n1;
TreeNode *n2;
TreeNode *n3;
n1 = (TreeNode*)malloc(sizeof(TreeNode));
n2 = (TreeNode*)malloc(sizeof(TreeNode));
n3 = (TreeNode*)malloc(sizeof(TreeNode));
// 첫번째 노드 n1을 설정
n1->data = 10;
n1->left = n2;
n1->right = n3;
// 두번째 노드 n2을 설정
n2->data = 10;
n2->left = NULL; // 자식노드가 없다 == leaf 노드
n2->right = NULL;
// 세번째 노드 n3을 설정
n3->data = 30;
n3->left = NULL; // 자식노드가 없다 == leaf 노드
n3->right = NULL;
drawBinarySearchTree(n1, 0);
// 동적 할당 메모리 반환
free(n1);
free(n2);
free(n3);
return 0;
}
실행 결과
- 왼쪽 부터 최상단 루트 노드이다.
- 노드 n1 = 10
- 노드 n2 = 20
- 노드 n3 = 30
위와 같이 트리가 잘 구성된 것을 볼 수 있다.- 아래는 이진 탐색 트리를 시각화 시켜주는 함수이다.
// 이진 탐색 트리를 그리는 함수 void drawBinarySearchTree(TreeNode* root, int space) { if (root == NULL) { return; } space += 5; drawBinarySearchTree(root->right, space); printf("\n"); for (int i = 5; i < space; i++) { printf(" "); } printf("%d\n", root->data); drawBinarySearchTree(root->left, space); }
이진 트리의 순회
이진트리의 순회(traversal) 란?
이진트리에 속하는 모든 노드를 한 번씩 방문하여 노드가 가지고 있는 데이터를 목적에 맞게 처리하는 것을 의미.
이전의 선형 자료구조는 데이터를 순회하는 방법이 하나 뿐이었으나 트리는 여러 순서로 각 노드가 가지고 있는 데이터에 접근 가능하다.
이진 트리의 순회 방법 3가지
전위, 중위, 후위 순회
이진 트리를 순회하는 표준 방법에는 전위, 중위, 후위 세 가지 방법이 있다.
세가지 방법은 루트 노드와 좌, 우 자식 노드중 어떤 노드를 먼저 방문하는 지에 따라 구분 된 것이다.
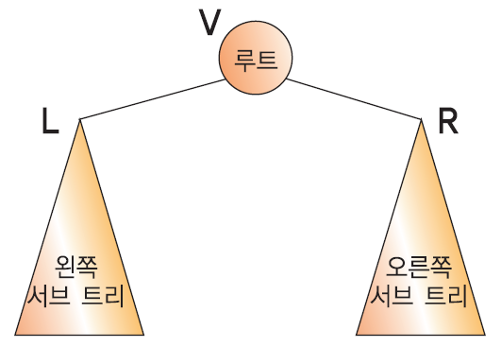
루트 방문을 V, 왼쪽 서브 트리 방문을 L, 오른쪽 서브 트리 방문을 R 이라 하자. (일반적으로 왼쪽 서브트리 -> 오른쪽 서브트리 순으로 방문한다)
전위 순회(preorder traversal) - VLR : 루트(V) -> 왼쪽 서브 트리(L) -> 오른쪽 서브 트리(R)
중위 순회(inorder traversal) - LVR : 왼쪽 서브 트리(L) -> 루트(V) -> 오른쪽 서브 트리(R)
후위 순회(postorder traversal) - LRV : 왼쪽 서브 트리(L) -> 오른쪽 서브 트리(R) -> 루트(V)
이진 트리의 순회 방법
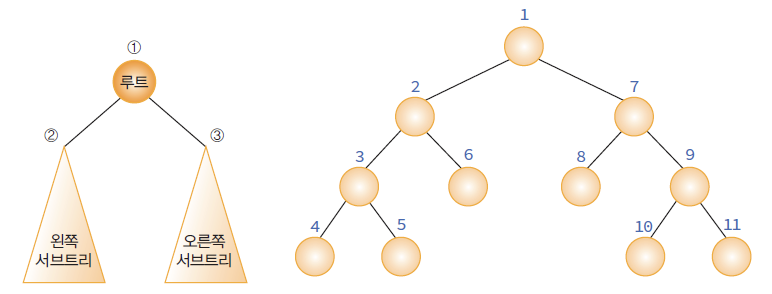
- 이진트리에서 루트의 좌, 우 서브 트리도 마찬가지로 이진트리로 구성되어 있는 것을 알 것이다.
- 따라서 각 서브 트리 방문시에도 같은 순회 방법을 계속해서 적용 해나가며 방문한다.
- 이진 트리를 보면 전체 트리와 각 서브트리들의 모양이 같다(공집합을 가진 노드까지 생각하자).
- 따라서 전체 트리 순회에 사용한 알고리즘은 서브트리에서도 그대로 사용할 수 있는 것이다.
- 대신 작업(문제)의 크기가 점점 작아진다.
- 어디서 많이 본 구조이지 않은가?
문제의 구조는 같으나 크기만 점차 작아지는 경우는 이전에 배웠던 "순환(recursion)"을 사용할 수 있다
이와 같은 이유로 이진 트리의 순회는 순환 알고리즘을 적용하여 구현할 수 있다.
순환 호출을 사용하게 되면 스택을 사용하게 되는 것이다. (코드상에는 존재하지 않는다.)
추가적으로 수식에서 각 순회 방법을 사용하면 이전에 배운 표기법을 아래와 같이 도출 할 수 있다.
전위 순회 - 전위표기법
후위 순회 - 후위표기법
중위 순회 - 중위 표기법
1. 전위 순회 (preorder)
전위 순회는 루트를 먼저 방문한 후 왼쪽 서브트리, 오른쪽 서브트리 순으로 방문한다.
1. 루트 노드를 방문한다.
2. 왼쪽 서브트리를 방문한다.
3. 오른쪽 서브트리를 방문한다.
이진 트리의 전위 순회
- 전위 순회에서 루트 노드를 방문했다고 가정해보자.
- 다음 차례는 왼쪽 서브트리인데, 왼쪽 서브트리의 어떤 노드를 먼저 방문해야 할까?
- 정답은 왼쪽 서브트리의 왼쪽 서브트리를 다시 방문해야 한다.
- 앞서 말한 것처럼, 모든 트리는 같은 구조를 가지고 있기 때문에 왼쪽 서브트리에서도 마찬가지로 LVR 을 적용, 왼쪽 서브트리부터 방문한다.
- 만약 NULL(트리의 끝)을 만나게 되면, 이후 순서인 오른쪽 서브트리를 방문하고, LVR을 종료하며 이전 레벨로 돌아간다.
- 왼쪽 서브트리 각 노드마다의 전체 LVR이 종료 되었으니 가장 처음 실행되었으나 끝나지 않은 처음의 LVR 중 R을 오른쪽 서브트리를 방문하여 실행한다.
- 왼쪽 서브트리처럼 오른쪽 서브트리의 각 노드마다의 LVR이 끝나게 되면 전위 순회가 종료 된다.
- 만약 NULL(트리의 끝)을 만나게 되면, 이후 순서인 오른쪽 서브트리를 방문하고, LVR을 종료하며 이전 레벨로 돌아간다.
즉, 모든 서브트리에 대하여 같은 알고리즘을 반복하는 것이다.
전위 순회는 구조화된 문서와 같은 자료를 관리하는 것에 유용하게 사용된다.
2. 중위 순회 (inorder)
중위 순회는 왼쪽 서브트리를 먼저 방문한 후 루트 노드, 오른쪽 서브트리 순으로 방문한다.
1. 왼쪽 서브트리를 방문한다.
2. 루트 노드를 방문한다.
3. 오른쪽 서브트리를 방문한다.
이진 트리의 중위 순회
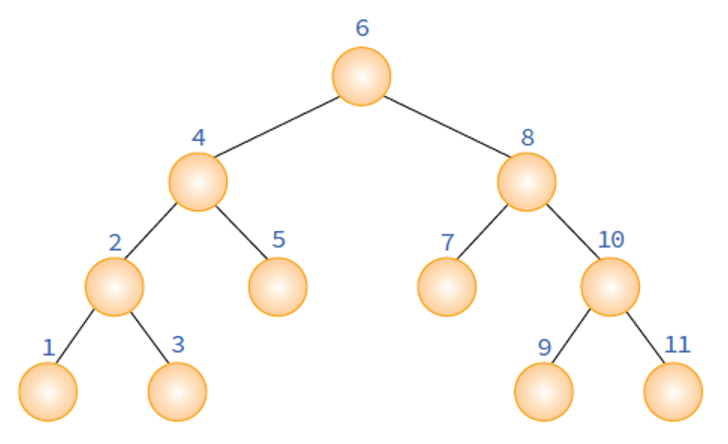
- 중위 순회도 전위 순회와 같은 방식의 알고리즘이나, 순서만 다르다.
중위 순회는 수식과 같은 자료를 관리하는 것에 유용하게 사용된다.
3. 후위 순회 (postorder)
후위 순회는 왼쪽 서브트리를 먼저 방문한 후 오른쪽 서브트리, 루트 노드 순으로 방문한다.
1. 왼쪽 서브트리를 방문한다.
2. 오른쪽 서브트리를 방문한다.
3. 루트 노드를 방문한다.
이진 트리의 후위 순회
- 후위 순회도 전위, 중위 순회와 같은 방식의 알고리즘이나, 순서만 다르다.
- 아래에서부터 거슬러 올라가며 데이터를 쌓아 최종 데이터를 도출하는 방식에 유용하다.
- 아래에서부터 데이터를 저장한 후 해당 노드를 지워가는 방식으로 구현.
후위 순회는 디렉터리의 용량 계산과 같은 알고리즘에 유용하게 사용된다.
전위, 중위, 후위 순회 구현
알고리즘
함수의 매개변수는 루트를 가리키는 포인터
좌, 우 서브트리 방문 함수 = 전체트리 방문 함수를 재호출 (다른점 : 매개변수 - 서브 트리의 루트노드를 매개변수로)
#include<stdio.h>
#include<stdlib.h>
#include<memory.h>
typedef struct TreeNode {
int data;
struct TreeNode* left;
struct TreeNode* right;
} TreeNode;
// 전위 순회
void preorder(TreeNode* root) {
if (root != NULL){
printf("[%d]", root->data); // 노드 방문 및 작업 수행
preorder(root->left); // 왼쪽 서브트리 순회
preorder(root->right); //오른쪽 서브트리 순회
}
}
// 중위 순회
void inorder(TreeNode* root){
if(root != NULL){
inorder(root->left); // 왼쪽 서브트리 순회
printf("[%d]", root->data); // 노드 방문 및 작업 수행
inorder(root->right); //오른쪽 서브트리 순회
}
}
// 후위 순회
void postorder(TreeNode* root) {
if(root != NULL){
postorder(root->left); // 왼쪽 서브트리 순회
postorder(root->right); //오른쪽 서브트리 순회
printf("[%d]", root->data); // 노드 방문 및 작업 수행
}
}
// 15
// 4 20
// 1 16 25
TreeNode n1={1, NULL, NULL};
TreeNode n2={4, &n1, NULL};
TreeNode n3={16, NULL, NULL};
TreeNode n4={25, NULL, NULL};
TreeNode n5={20, &n3, &n4};
TreeNode n6={15, &n2, &n5};
TreeNode *root= &n6;
int main(void) {
printf("중위 순회=");
inorder(root);
printf("\n");
printf("전위 순회=");
preorder(root);
printf("\n");
printf("후위 순회=");
postorder(root);
printf("\n");
return 0;
}
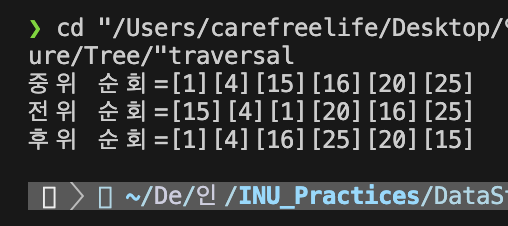
실행 결과
레벨 순회 (level order)
레벨 순회는 각 노드를 레벨 순으로 검사하는 순회 방법이다.
- 루트 노드의 레벨은 1이고 하위 레벨로 내려갈수록 레벨은 증가한다.
- 동일한 레벨의 경우에는 좌 -> 우 순으로 방문한다.
- 지금까지의 순회법이 스택(순환 호출)을 사용했던 것에 비해 레벨 순회는 큐(Queue)를 사용한다.
큐(queue)를 사용하는 레벨 순회의 모습
- 레벨 순회 코드는 큐에 노드가 하나라도 있으면 계속 반복하는 코드로 이루어짐.
- 한번의 반복 : 큐에 있는 노드를 꺼내(dequeue) 방문(작업) 후 해당 노드의 자식 노드를 큐에 삽입(enqueue)
- 큐에 더 이상 노드가 남아있지 않을 때까지 위와 같은 과정을 반복.
#include<stdio.h>
#include<stdlib.h>
#include<memory.h>
// ================ 원형큐 코드 시작 =================
#define MAX_QUEUE_SIZE 100
typedef struct TreeNode {
int data;
struct TreeNode* left;
struct TreeNode* right;
} TreeNode;
typedef TreeNode * element;
typedef struct { // 큐 타입
element data[MAX_QUEUE_SIZE];
int front, rear;
} QueueType;
// 오류 함수
void error(char *message){
fprintf(stderr, "%s\n", message);
exit(1);
}
// 공백 상태 검출 함수
void init_queue(QueueType *q){
q->front = q->rear = 0;
}
// 공백 상태 검출 함수
int is_empty(QueueType *q){
return (q->front == q->rear);
}
// 포화 상태 검출 함수
int is_full(QueueType *q){
return ((q->rear + 1) % MAX_QUEUE_SIZE == q->front);
}
// 삽입 함수
void enqueue(QueueType *q, element item){
if (is_full(q))
error("큐가 포화상태입니다");
q->rear = (q->rear + 1) % MAX_QUEUE_SIZE;
q->data[q->rear] = item;
}
// 삭제 함수
element dequeue(QueueType *q){
if (is_empty(q))
error("큐가 공백상태입니다");
q->front = (q->front + 1) % MAX_QUEUE_SIZE;
return q->data[q->front];
}
// 레벨 순회
void level_order(TreeNode* ptr){
QueueType q;
init_queue(&q); // 큐 초기화
if (ptr == NULL) return;
// 노드 삽입
enqueue(&q, ptr);
// 큐에 노드가 한 개도 없을 때까지 실행.
while (!is_empty(&q)) {
ptr = dequeue(&q); // 큐에서 노드를 하나 꺼낸다.
printf(" [%d] ", ptr->data); // 해당 logic의 작업을 한다.
if (ptr->left) // 해당 노드의 왼쪽 자식이 있으면 삽입.
enqueue(&q, ptr->left);
if (ptr->right) // 해당 노드의 오른쪽 자식이 있으면 삽입.
enqueue(&q, ptr->right);
}
}
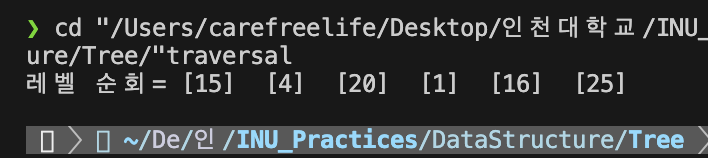
// 15
// 4 20
// 1 16 25
TreeNode n1={1, NULL, NULL};
TreeNode n2={4, &n1, NULL};
TreeNode n3={16, NULL, NULL};
TreeNode n4={25, NULL, NULL};
TreeNode n5={20, &n3, &n4};
TreeNode n6={15, &n2, &n5};
TreeNode *root= &n6;
int main(void) {
// printf("중위 순회=");
// inorder(root);
// printf("\n");
// printf("전위 순회=");
// preorder(root);
// printf("\n");
// printf("후위 순회=");
// postorder(root);
// printf("\n");
// 큐를 사용하는 레벨 순회 추가
printf("레벨 순회=");
level_order(root);
printf("\n");
return 0;
}
레벨 순회 실행 결과
그래서 어떤 순회를 사용해야 하는 건가요?
순서에 상관없이 모든 노드를 방문하기만 하면 되는 알고리즘에서는 3가지 순회 중 구현하기 편한 것을 사용하면 된다.
만약 노드를 방문하여 작업하는 것에 순서가 필요하다면,
(1.) 자식노드를 처리한 후에 부모노드를 처리 -> 후위 순회
(디렉토리의 용량 계산 - 하위 디렉토리의 용량부터 계산하며 올라와 전체 용량을 계산)
(2.) 부모노드를 처리한 후에 자식노드를 처리 -> 전위 순회
(구조화 된 문서의 출력 - 제목 -> 목차 -> 챕터 -> 내용)
(3.) 자식노드의 처리 중간에 부모노드의 처리가 필요한 경우 -> 중위 순회
(수식 트리 - 두 피연산자 사이에 연산자 필요 전위, 중위, 후위 모두 가능)
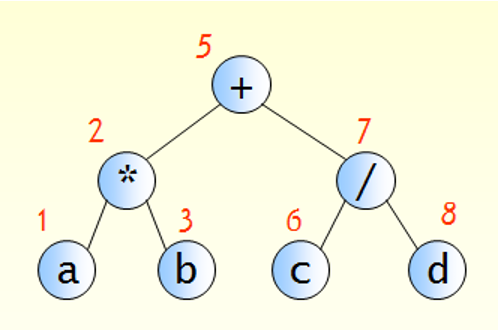
트리의 응용(1) : 수식 트리
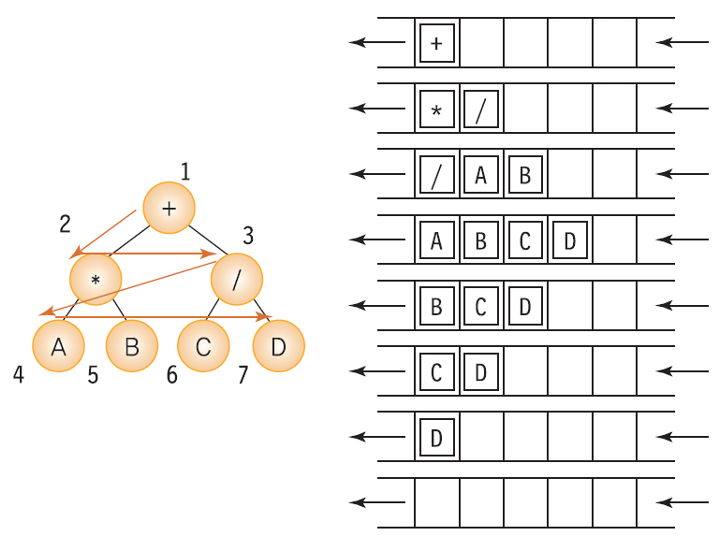
이진 트리는 수식 트리(expression tree)를 처리하는데 사용될 수 있다.
피연산자들은 단말 노드(leaf node)가 되고, 연산자들은 비단말 노드가 된다.
이진 트리를 활용한 수식 트리 - a + b 를 수식 트리로 표현한 것
위와 같은 수식 트리를 앞에서 배운 전위, 중위, 후위 순회를 사용하여 읽게 되면
각각 전위, 중위, 후위 표기 수식이 된다.
어떤 순회 방법을 사용하냐에 따라 이진 수식 트리의 표기법을 바꿀 수 있다.
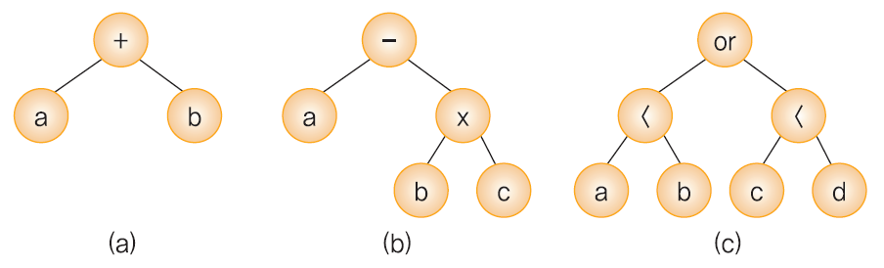

- 수식 트리의 루트 노드는 연산자이고, 그 자식 노드들은 피연산자인 단말 노드부터 연산자인 해당 부모 노드와 만나 연산이 실행된다.
- 따라서, 연산자들의 피연산자인 양쪽의 자식 노드들을 먼저 꺼내 부모 노드의 연산자로 연산.
- 이는 자식노드를 먼저 방문한 후 부모노드를 방문하는 후위 순회를 사용해야 하는 것이다.
- 프로그램의 구조 - 1. 후위 순회를 사용. 2. 서브 트리의 값을 순환 호출로 계산. 3. 비단말 노드를 방문할 때 양쪽 서브 트리의 값을 노드에 저장된 연산자를 이용하여 계산.
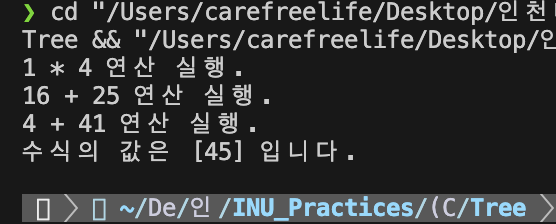
수식 트리의 계산 순서

수식트리의 계산 알고리즘을 C 코드와 함께 살펴보자.
#include<stdio.h>
#include<stdlib.h>
typedef struct TreeNode {
int data;
struct TreeNode* left;
struct TreeNode* right;
}TreeNode;
// +
// * +
//1 4 16 25
TreeNode n1={1, NULL, NULL};
TreeNode n2={4, NULL, NULL};
TreeNode n3={'*', &n1, &n2};
TreeNode n4={16, NULL, NULL};
TreeNode n5={25, NULL, NULL};
TreeNode n6={'+', &n4, &n5};
TreeNode n7={'+', &n3, &n6};
TreeNode *root= &n7;
// 수식 계산 함수
int evaluate(TreeNode *root){
if(root == NULL){
return 0;
}
// 자식 노드가 없는 말단 노드(== 피연산자)이면 방문.(숫자 데이터 꺼냄)
if(root->left == NULL && root->right == NULL){
return root->data;
}
// 말단 노드가 아닌 부모노드(== 연산자) 이면 말단노드(== 피연산자)가 나올 때까지 후위 순회.
else{
int op1 = evaluate(root->left); // evaluate 함수의 recursion. (L)
int op2 = evaluate(root->right);// evaluate 함수의 recursion. (R)
printf("%d %c %d 연산 실행.\n", op1, root->data, op2);
switch(root->data){ // L -> R 이 끝난 후 루트 노드(V)에 방문하여 연산 작업 실행. : 후위 순회
case '+':
return op1 + op2;
case '-':
return op1 - op2;
case '*':
return op1 * op2;
case '/':
return op1 / op2;
}
}
return 0;
}
int main(void){
printf("수식의 값은 [%d] 입니다.\n", evaluate(root));
return 0;
}
수식 트리 계산 프로그램 실행 결과
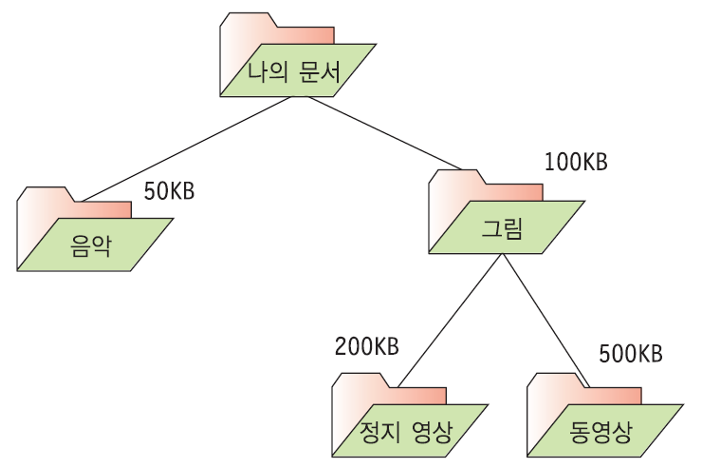
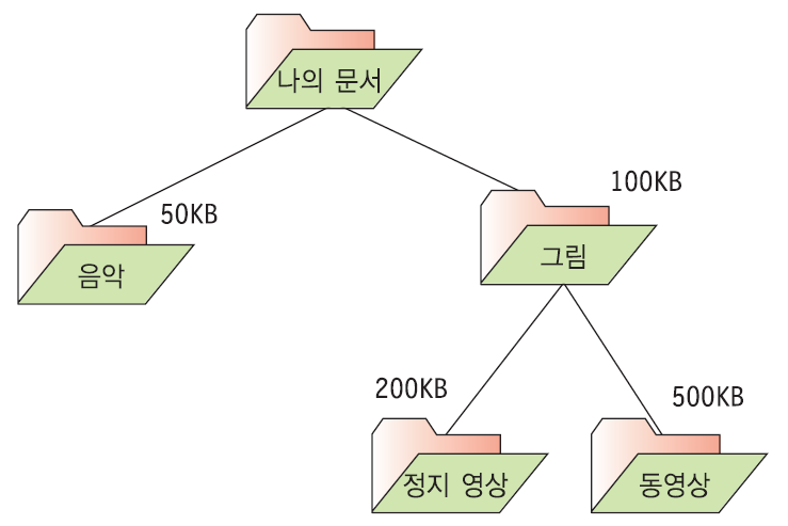
트리의 응용 (2) : 디렉토리 용량 계산 - 후위 순회
이진 트리의 후위 순회를 이용하여 디렉토리 용량 계산하기
- 트리의 응용 : 디렉토리 용량 계산
- 이진 트리를 사용하기 때문에 하나의 디렉토리 안에 2개를 초과하는 디렉토리가 존재하면 안된다.
- 상위 디렉토리의 용량은 하위 디렉토리 용량의 합을 통해 구할 수 있다.
- 후위 순회를 사용하여 하위 디렉토리를 먼저 방문한 후 루트 노드의 용량을 계산하자.
- 순환 호출되는 함수가 용량을 반환하도록 구현
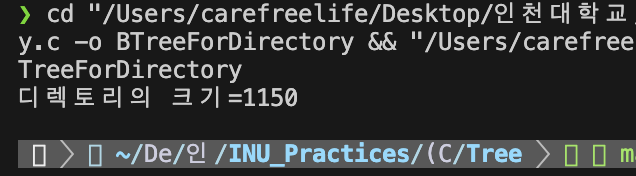
#include<stdio.h> #include<stdlib.h> typedef struct TreeNode { int data; struct TreeNode *left; struct TreeNode *right; }TreeNode; int cal_dir_size(TreeNode* root){ int left_size, right_size = 0; if(root == NULL){ return 0; } left_size = cal_dir_size(root->left); // 왼쪽 자식 값 반환 (L) right_size = cal_dir_size(root->right); // 오른쪽 자식 값 반환 (R) return root->data + left_size + right_size; // L + R + V 용량 반환 } int main (void){ TreeNode n4 = { 700, NULL, NULL }; TreeNode n5 = { 300, NULL, NULL }; TreeNode n3 = { 130, &n4, &n5 }; TreeNode n2 = { 20, NULL, NULL }; TreeNode n1 = { 0, &n2, &n3 }; printf("디렉토리의 크기=%d\n", cal_dir_size(&n1)); return 0; }
디렉토리 용량 계산 결과
트리의 응용 (3) : 이진 트리의 추가 연산
1. 노드의 개수 구하기
노드의 개수 구하기
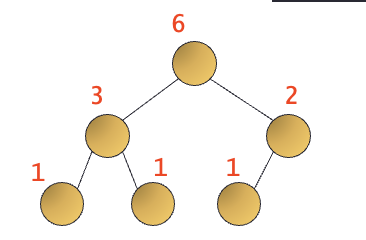
- 탐색 트리 안의 노드의 개수를 세어 표시한다.
- 각각의 서브트리에 대하여 순환 호출 후, 반환 되는 값에 1을 더하여 반환.
-
int get_node_count(TreeNode* node){ int count = 0; if(node != NULL){ count = 1 + get_node_count(node->left) + get_node_count(node->right); } return count; }
2. 단말 노드의 개수 구하기
- 왼쪽 자식과 오른쪽 자식이 동시에 0(NULL)이 되면 단말 노드이므로 1 반환.
- 그 외는 비단말 노드이므로 각각의 서브트리에 대하여 순환호출, 반환되는 값을 서로 더한다.
-
int get_leaf_count(TreeNode* node){ int count = 0; if(node!=NULL){ if(node->left == NULL && node->right == NULL){ return 1; } else{ count = get_leaf_count(node->left) + get_leaf_count(node->right); } } return count; }
3. 높이 구하기
전체 트리의 높이 구하기(이진 트리)
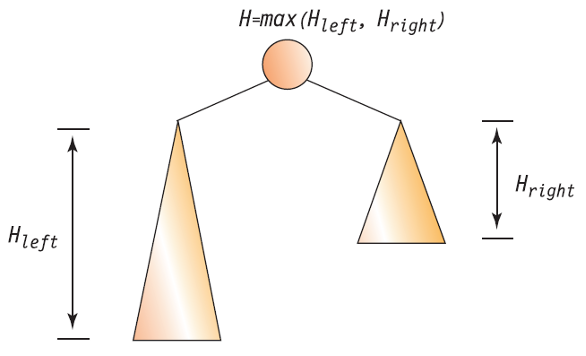
- 각 서브트리에 대한 순환 호출이 끝나면 각각의 서브트리에 대한 높이가 반환되어 온다.
- 전체 트리의 높이는 각 서브트리의 높이 합으로 구할 수 없다.
- 서브트리의 높이의 최대 값을 찾아야 한다.
-
int get_height(TreeNode* node){ int height = 0; if(node != NULL){ height = 1 + max(get_height(node->left), get_height(node->right)); } }
스레드 이진 트리 (Threaded Binary Tree)
- 이진트리의 NULL 링크를 이용하여 순환호출 없이도 트리의 노드들을 순회
- 중위 순회시 후속 노드인 중위 후속자(inorder successor)나 선행 노드인 중위 선행자(inorder predecessor)를 NULL 링크에 저장시켜 놓은 트리가 스레드 이진 트리이다.
- 스레드를 이용하여 노드들을 순회 순서대로 연결시켜 놓은 트리.
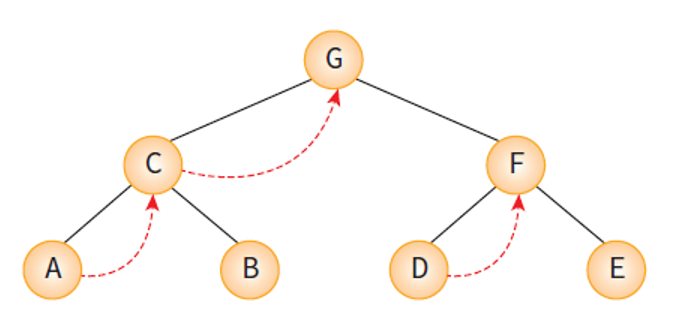
스레드 이진트리의 모습- 스레드 트리는 순회를 빠르게 하는 장점이 있으나, 스레드를 설정하기 위하여 삽입 / 삭제 함수가 더 많은 일을 해야 한다.
- 단말 노드와 비단말 노드의 구별을 위해 구조체에 is_thread 필드가 필요하다.
- 만약 위와 같이 NULL 링크가 스레드에 저장되면 링크에 저장된 것이 (자식을 가리키는 포인터 or NULL을 대신한 스레드) 중 어떤 것이 저장되어 있는 것인지를 구별할 태그 필드가 필요.
- 따라서, 다음과 같이 노드의 구조를 변경
-
typedef struct TreeNode { int data; struct TreeNode* left; struct Treenode* right; int is_thread; // 만약 오른쪽 link가 스레드(중위 후속자) 이면 TRUE 오른쪽 자식이면 FALSE }
-
- 노드의 중의 후속자를 반환하는 함수 find_successor 를 작성.
// find_successor(TreeNode* node)
// node의 is_thread 가 TRUE 이면, 바로 오른쪽 자식이 중위 후속자이므로 오른쪽 자식을 반환.
// 만약 오른쪽 자식이 NULL이면 더 이상 후속자가 없다는 것이므로 NULL 반환.
// node의 is_thread가 FALSE이면 서브 트리의 가장 왼쪽 노드로 가야한다.
// -> 왼쪽 자식이 NULL 이 될 때까지 왼쪽 링크를 타고 이동한다.
TreeNode* find_succesor(TreeNode* node){
// nodeR 은 node의 오른쪽 포인터
TreeNode* nodeR = node->right;
// 만약 오른쪽 포인터가 NULL 이거나 node가 스레드이면 즉각 오른쪽 포인터를 반환
// node == 스레드: 오른쪽 자식이 중위 후속자이므로 반환
// node->right == NULL: 더 이상 후속자가 없다는 뜻이므로 NULL 반환
if(nodeR == NULL || node->is_thread == TRUE){
return nodeR;
}
// 만약 nodeR이 위의 if문에서 걸리지 않은 오른쪽 자식이면 다시 가장 왼쪽 노드로 이동.
while(nodeR->left != NULL) nodeR = nodeR->left;
return nodeR;
}
// 스레드 버전 중위 순회 함수
// 중위 순회는 트리의 가장 왼쪽 노드부터 시작. -> 왼쪽 자식이 NULL이 될 때까지 왼쪽으로 이동.
// 이후 데이터를 출력하고, 중위 후속자를 찾는 함수를 호출하여 후속자가 NULL이 아니면 계속 루프를 반복.
void thread_inorder(TreeNode* root){
TreeNode* node;
node = root;
while(node->left) node = node->left // 가장 왼쪽 노드로 이동
do{
printf("%c ", node->data); // 데이터 출력
node = find_succesor(node) // 후속자 함수 호출
}while(node) // NULL이 아니면 게속 loop.
}
최대한의 설명을 코드 블럭 내의 주석으로 달아 놓았습니다.
혹시 이해가 안가거나 추가적인 설명이 필요한 부분, 오류 등의 피드백은 언제든지 환영합니다!
긴 글 읽어주셔서 감사합니다. 포스팅을 마칩니다.
참고: C언어로 쉽게 풀어쓴 자료구조 <개정 3판> 천인국, 공용해, 하상국 지음
Task Lists
- 트리의 개념 (Tree)
- 트리의 용어
- 트리의 종류
- 이진 트리의 성질
- 이진 트리의 분류
- 이진 트리의 표현 : 배열 / 링크
- 이진 트리의 순회
- 이진 트리의 순회 방법 3가지 : 전위, 중위, 후위
- 전위, 중위, 후위 순회 구현
- 레벨 순회 (level order)
- 트리의 응용(1) : 수식 트리
- 트리의 응용 (2) : 디렉토리 용량 계산 - 후위 순회
- 트리의 응용 (3) : 이진 트리의 추가 연산
- 스레드 이진 트리 (Threaded Binary Tree)



Comments