
Data Structure - 그래프 (Graph) (3) - Dijkstra, Floyd, Topological Sort
최단 경로 (Shortest path) 문제
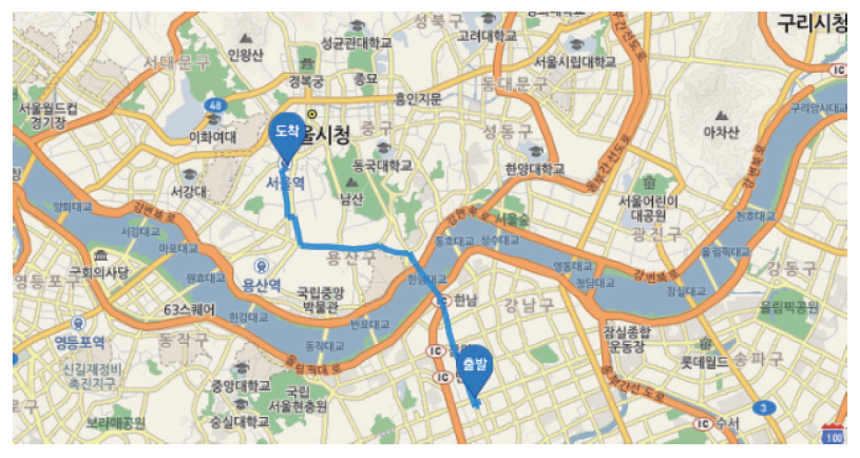
최단 경로 예시 - 정점은 도시, 도시 간 거리는 간선의 가중치가 될 수 있다.
최단 경로 (Shortest path) 문제는 네트워크의 정점 i와 정점 j를 연결하는 경로 중에서 각 간선마다의 가중치 합이 최소가 되는 경로를 찾는 문제이다.
- 간선의 가중치는 비용, 거리, 시간 등을 나타낼 수 있다.
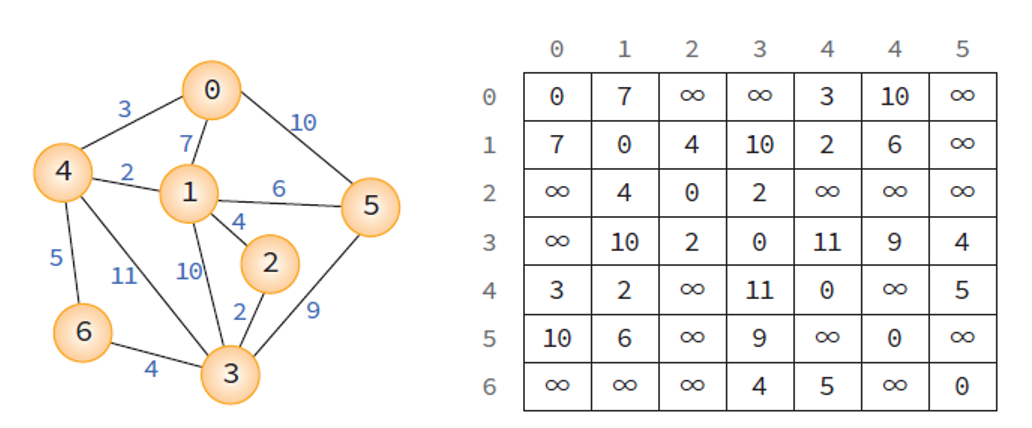
네트워크와 가중치를 인접행렬로 표현한 모습.
- 정점 0 -> 정점 3
- 최단 거리 : (0, 4, 1, 2, 3) , 비용 : 3 + 2 + 4 + 2 = 11
- (0, 1, 2, 3) : 정점을 거치는 횟수는 적지만, 비용이 (7 + 4 + 2 = 13) 으로 많이 든다.
- 어떤 방법으로 최단 경로를 찾을 것인가?
- Dijkstra 알고리즘 : 하나의 시작 정점에서 다른 정점까지의 최단 경로를 구한다.
- Floyd 알고리즘 : 모든 정점에서 다른 모든 정점까지의 최단 경로를 구한다.
- 가중치 인접 행렬에서는 정점 간 간선이 존재하지 않으면 무한대(정수의 최대 값)를 행렬에 저장.
Dijkstra의 최단 경로 알고리즘
최단 경로 알고리즘
- 하나의 시작 정점으로부터 모든 다른 정점까지의 최단 경로를 탐색.
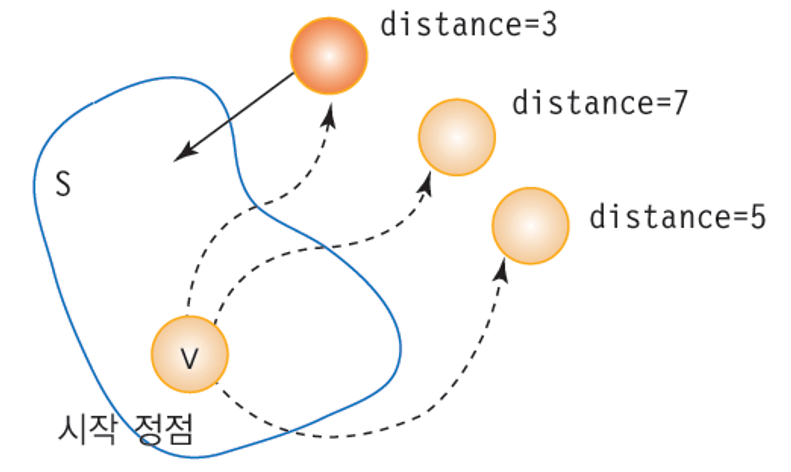
- 집합 S : 시작 정점 v로부터의 최단 경로가 이미 발견된 정점들의 집합
- distance[] : 시작 정점 v에서 집합 S에 포함되는 정점들만 거쳐 다른 정점으로 가는 최단거리를 기록.
- 매 단계에서 가장 distance 값이 작은 정점을 S에 추가.
- 시작 정점을 v라 하면, distance[v] = 0
- 다른 정점에 대한 distance 값은 시작 정점 v와 해당 정점 간의 가중치 값.
- 가중치 인접 행렬을 weight 이라 하면, distance[w] = weight[v][w]
최단 경로 알고리즘에서 최단 경로의 증명
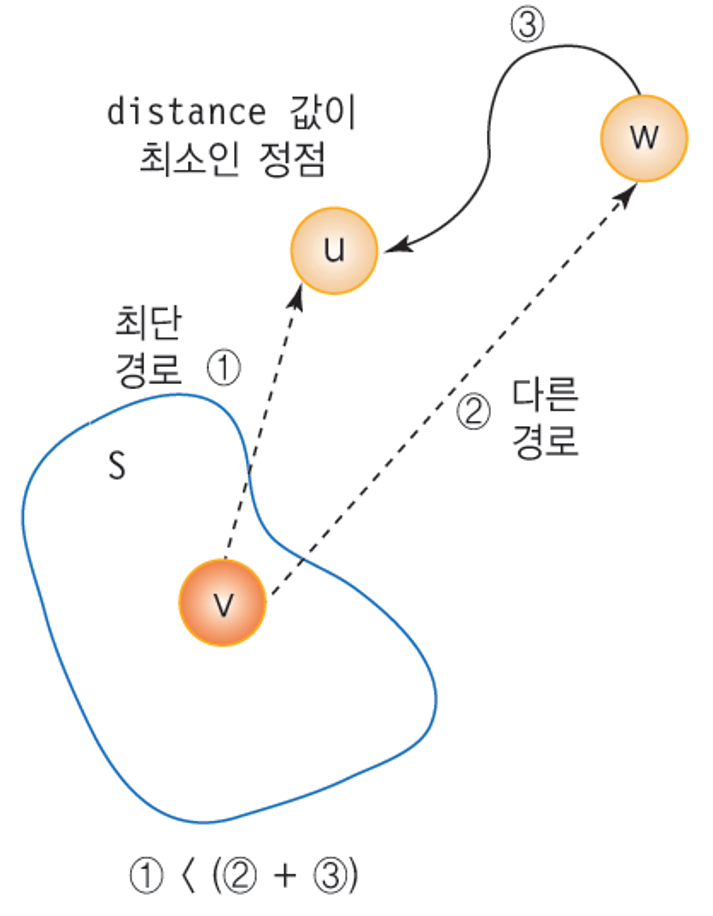
최단 경로의 증명
- 각 단계에서 S안에 있지 않은 정점 중에서 가장 distance 값이 작은 정점을 S에 추가한다.
- 정점 w를 거쳐서 정점 u로 가는 더 짧은 경로가 있다고 가정.
- 정점 v -> u 까지의 거리 = (v -> w) + (w -> u)
- 하지만 현재 distance 값이 가장 작은 정점은 u이기 때문에, 경로 2는 경로 1보다 항상 길 수 밖에 없다.
- 따라서 매 단계의 집합 S에 속하지 않는 정점들 중에서 가장 작은 distance 값을 가진 정점들을 추가해
나가며 시작 정정메서 모든 정점 까지의 최단 거리를 구할 수 있다.
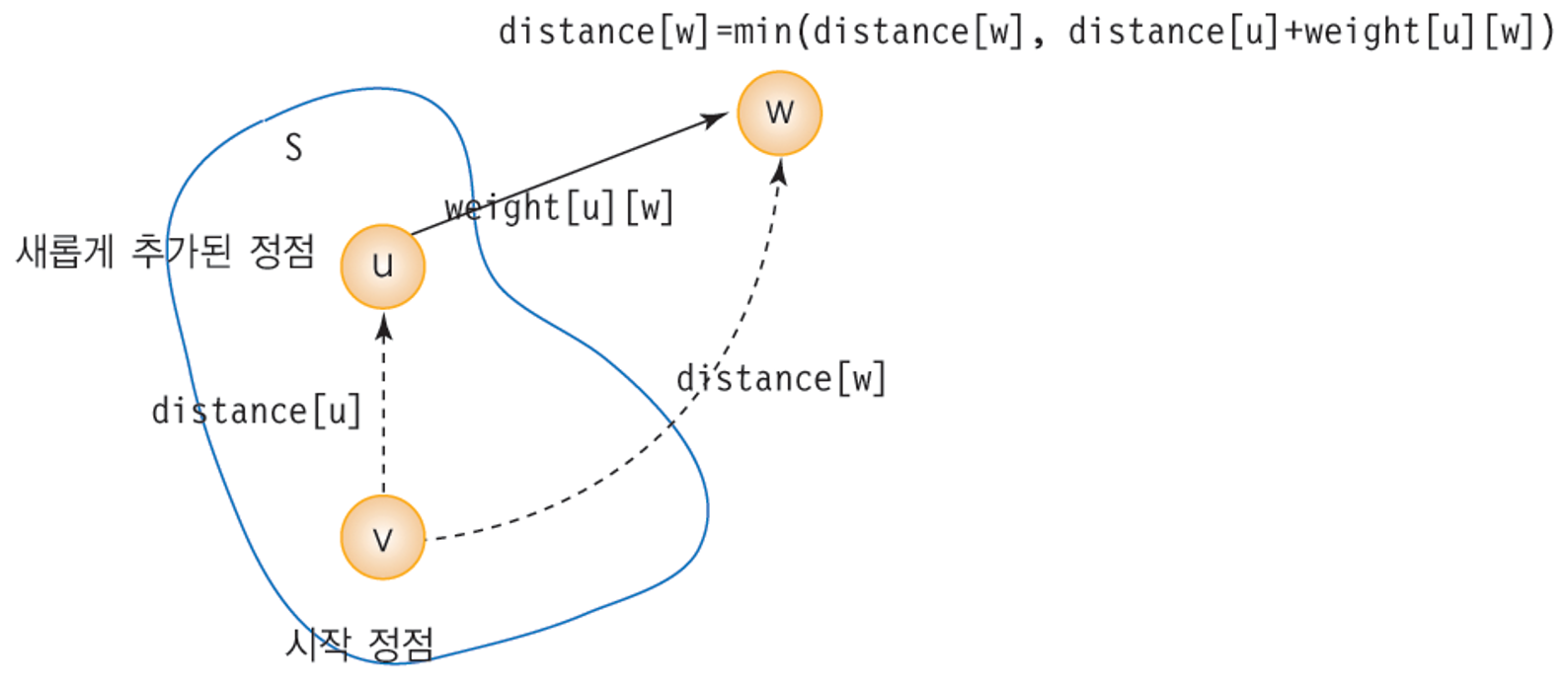
최단 경로 알고리즘에서의 distance값 갱신
- 새로운 정점 u가 추가되면 S에 속하지 않은 다른 정점들의 distance값을 갱신 해주어야 한다.
- 새로 추가된 정점 u를 거쳐 갈 수 있게 된 거리와 기존 거리를 비교하여 더 작은 거리로 distance 값을 수정.
- distance[w] = min(distance[w], distance[u] + weight[u][w])
pseudo code 로 Dijkstra 알고리즘을 정리해보자.
// 최단거리 알고리즘 - Dijkstra
// 입력: 음수가 아닌 가중치를 가진 가중치 그래프 G
// 출력: distance 배열, distance[u]는 v에서 u까지의 최단 거리이다.
shortest_path(G, V)
s ← {v}
for 각 정점 w ⍷ G do
distance[w] ← weight[v][w];
while 모든 정점이 S에 포함되지 않으면 do
u ← 집합 S에 속하지 않는 정점 중에서 최소 distance 정점;
S ← S U {u}
for u에 인접하고 S에 있는 각 정점 z do
if distance[u] + weight[u][z] < distance[z]
then distance[z] ← distance[u] + weight[u][z];
각 단계에서의 distance 값 변화 1
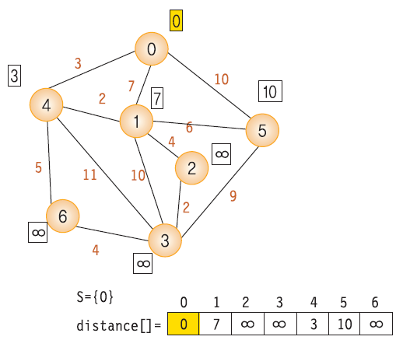
- 시작 노드 : v = 0, v와 근접한 노드 1(w = 7), 4(w = 3), 5(w = 10) 값을 distance 배열에 저장.
각 단계에서의 distance 값 변화 2
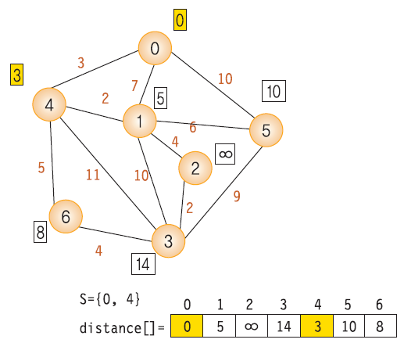
- 새로운 정점 1, 4 가 집합 s에 추가되었으므로, 해당 정점들을 통해 또 다른 정점에 도달 할 수 있게 된다.
- 4 -> 6(w = 3 + 5) / 4 -> 3(w = 3 + 11) / 4 -> 1(w = 3 + 2)
- S = {0, 4}
각 단계에서의 distance 값 변화 3
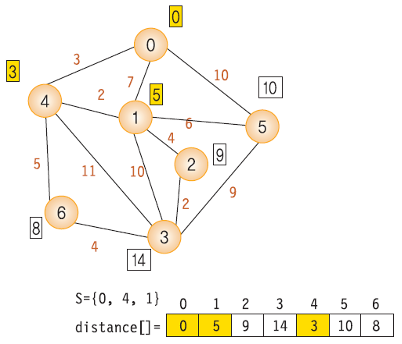
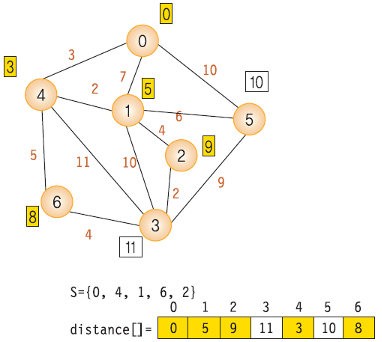
- 1 -> 2(w = 3 + 2 + 4)
- S = {0, 4, 1}
각 단계에서의 distance 값 변화 4
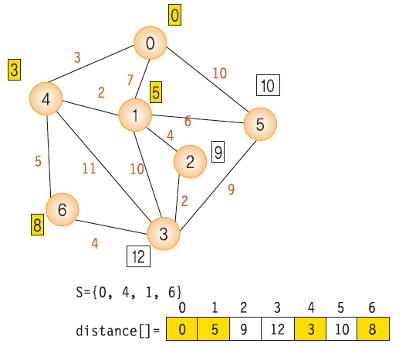
- S = {0, 4, 1, 6}
각 단계에서의 distance 값 변화 5- S = {0, 4, 1, 6, 2}
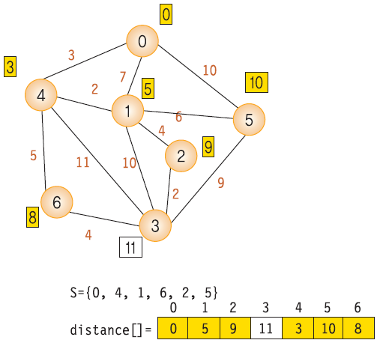
각 단계에서의 distance 값 변화 6- S = {0, 4, 1, 6, 2, 5}
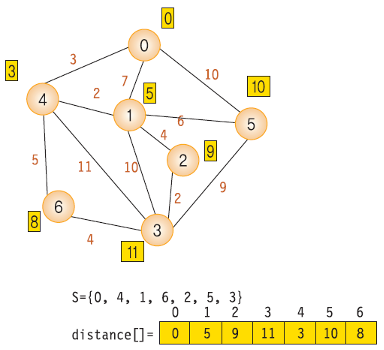
각 단계에서의 distance 값 변화 7- S = {0, 4, 1, 6, 2, 5, 3}
Dijkstra 알고리즘의 구현
함수 호출 : shortest_path(0, MAX_VERTICES) (시작 정점이 0)
호출 결과 : 배열 distance에 0번(시작 정점)으로부터 다른 모든 정점으로의 최단 경로 거리를 저장.
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#define TRUE 1
#define FALSE 0
#define MAX_VERTICES 100
#define INF 1000000 // 무한대 (두 정점 사이의 간선이 없는 경우)
typedef struct GraphType {
int n;
int weight[MAX_VERTICES][MAX_VERTICES];
}GraphType;
// 시작 정점으로부터의 최단 경로 거리
int distance[MAX_VERTICES];
// 방문한 정점 표시
int found[MAX_VERTICES];
//
int choose(int distance[], int n, int found[]){
int i, min, minpos;
min = INT_MAX;
minpos = -1;
for(int i = 0; i < n; i++){
if(distance[i] < min && !found[i]){
min = distance[i];
minpos = i;
}
}
return minpos;
}
void print_status(GraphType *g){
static int step = 1;
printf("STEP %d: ", step++);
printf("distance: ");
for(int i = 0; i < g->n; i++){
if(distance[i] == INF){
printf(" * ");
}
else{
printf("%2d ", distance[i]);
}
}
printf("\n");
printf(" found: ");
for(int i = 0; i < g->n; i++){
printf("%2d ", found[i]);
}
printf("\n\n");
}
void shortest_path(GraphType *g, int start){
int i, u, w;
// distance, found 배열 초기화
for(i = 0; i < g->n; i++){
distance[i] = g->weight[start][i];
found[i] = FALSE;
}
found[start] = TRUE; // 시작 정점 방문 표시
distance[start] = 0; // 시작 정점의 거리는 0
for(i = 0; i < g->n - 1; i++){
print_status(g);
u = choose(distance, g->n, found);
found[u] = TRUE;
for(w = 0; w < g->n; w++){
if(!found[w]){
if(distance[u] + g->weight[u][w] < distance[w])
distance[w] = distance[u] + g->weight[u][w];
}
}
}
}
int main(void)
{
GraphType g = { 7,
{ { 0, 7, INF, INF, 3, 10, INF },
{ 7, 0, 4, 10, 2, 6, INF },
{ INF, 4, 0, 2, INF, INF, INF },
{ INF, 10, 2, 0, 11, 9, 4 },
{ 3, 2, INF, 11, 0, INF, 5 },
{ 10, 6, INF, 9, INF, 0, INF },
{ INF, INF, INF, 4, 5, INF, 0 } }
};
shortest_path(&g, 0);
return 0;
}
Dijkstra 알고리즘 실행 결과
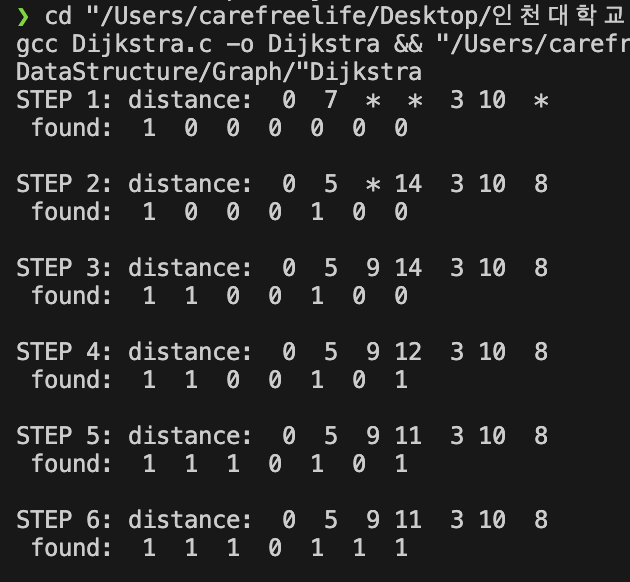
Dijkstra 의 분석
- 네트워크에 n개의 정점이 있다면,
- 최단 경로 알고리즘은 주 반복문을 n번 반복, 내부 반복문을 2n번 반복
- 시간 복잡도 : O(n^2)
Floyd 의 최단 경로 알고리즘
Floyd의 최단 경로 알고리즘
- 그래프에 존재하는 모든 정점 사이의 최단 경로를 한번에 찾아주는 알고리즘
- 2차원 배열 A를 이용하여 3중 반복 루프로 구성
- 가중치 인접 행렬 weight[][] == A
- weight[i][j] 에서 i==j 이면, 즉 행렬의 대각선 부분은 0으로 만들어준다.
- 만약 두개의 정점 i, j 사이에 간선이 존재하지 않으면 weight[i][j] = ⚭
- 간선이 존재하면 weight[i][j] = 간선의 가중치
Floyd 의 최단 경로 알고리즘 - pseudo code
Floyd(G):
for k ← 0 to n - 1
for i ← 0 to n - 1
for j ← 0 to n - 1
A[i][j] = min(A[i][j], A[i][k] + A[k][j])
Floyd 최단 경로 알고리즘의 동작 원리
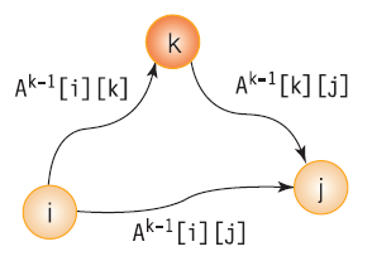
- A(k)[i][j]:
- 0 부터 k까지의 정점 만을 이용한 정점 i에서 j까지의 최단 경로 길이
- A(-1) == weight 배열의 값 -> A(0) -> A(1) -> A(2) -> A(n-1) 순서로 최단 경로를 구해간다.
- A(k-1)까지 구해진 상태에서 k번째 정점이 추가로 고려되는 상황 생각.
Floyd 최단 경로 알고리즘 - k번째 정점의 추가
- 0부터 k까지의 정점만을 사용하여 정점 i에서 정점 j로 가는 최단 경로는 2가지.
- 정점 k를 거치지 않는 경우:
- A(k)[i][j] 는 k보다 큰 정점은 통과하지 않으므로 최단거리는 그대로 A(k-1)[i][j].
- 정점 K를 거치는 경우:
- i에서 k까지의 최단거리인 A(k-1)[i][k] + k에서 j까지의 최단거리인 A(k-1)[k][j].
Floyd의 최단 경로 프로그램 구현
#include <stdio.h>
#include <stdlib.h>
#define TRUE 1
#define FALSE 0
#define MAX_VERTICES 100
#define INF 1000000 // 무한대 (간선이 존재하지 않는 경우)
typedef struct GraphType {
int n; // 정점의 개수
int weight[MAX_VERTICES][MAX_VERTICES];
}GraphType;
int A[MAX_VERTICES][MAX_VERTICES];
void printA(GraphType *g){
int i, j;
printf("==============================\n");
for(i = 0; i < g->n; i++){
for(j = 0; j <g->n; j++){
if(A[i][j] == INF){
printf(" * ");
}
else printf("%3d ", A[i][j]);
}
printf("\n");
}
printf("==============================\n");
}
void floyd(GraphType *g){
int i, j, k;
for(i = 0; i < g->n; i++){
for(j = 0; j < g->n; j++){
A[i][j] = g->weight[i][j];
}
}
printA(g);
for(k = 0; k < g->n; k++){
for(i = 0; i< g->n; i++){
for(j = 0; j < g->n; j++){
if(A[i][k] + A[k][j] < A[i][j])
A[i][j] = A[i][k] + A[k][j];
}
}
printA(g);
}
}
int main(void)
{
GraphType g = { 7,
{ { 0, 7, INF, INF, 3, 10, INF },
{ 7, 0, 4, 10, 2, 6, INF },
{ INF, 4, 0, 2, INF, INF, INF },
{ INF, 10, 2, 0, 11, 9, 4 },
{ 3, 2, INF, 11, 0, INF, 5 },
{ 10, 6, INF, 9, INF, 0, INF },
{ INF, INF, INF, 4, 5, INF, 0 } }
};
floyd(&g);
return 0;
}
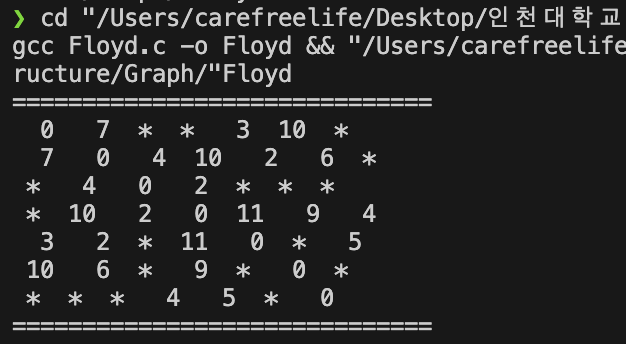
Floyd 최단 경로 알고리즘 - 실행 결과
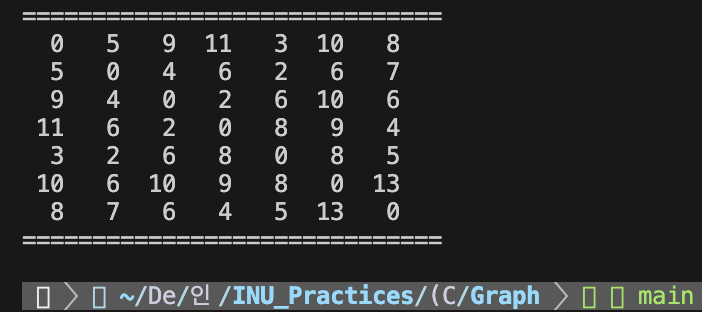
Floyd 최단 경로 알고리즘의 분석
- 두 정점 사이의 최단 경로를 찾는 Dijkstra 알고리즘의 시간 복잡도는 O(n^2).
- 모든 정점 쌍의 최단 경로를 구하는 Floyd 알고리즘의 시간 복잡도는
Dijkstra 알고리즘을 n번 반복해야 하므로, O(n^3)
위상 정렬 (Topological Sort) 이란?
위상 정렬 (Topological Sort) :
- 방향 그래프에 존재하는 각 정점들의 선행 순서를 위배하지 않으면서 모든 정점을 나열하는 것
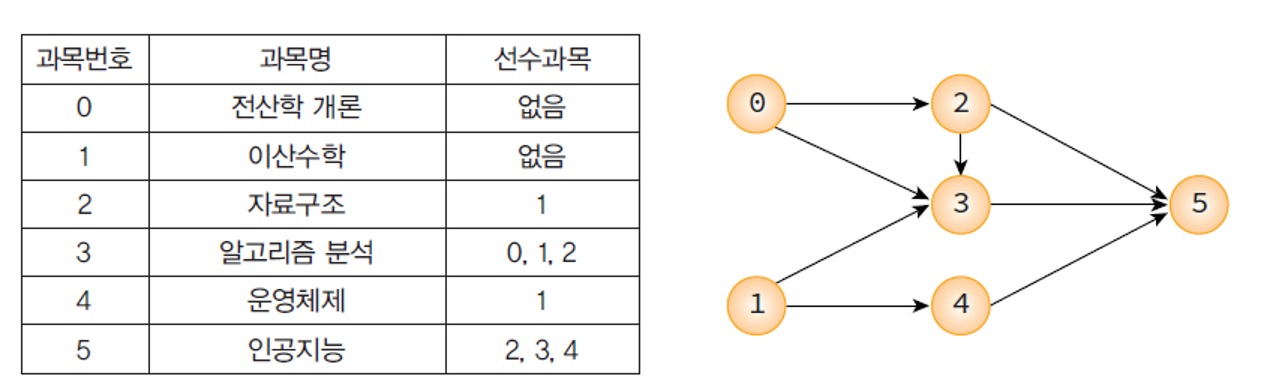
위상 정렬의 예
- 위상 순서(topological order) : (0, 1, 2, 3, 4, 5) , (1, 0, 2, 3, 4, 5)
- 위상 순서가 아닌 것 : (2, 0, 1, 3, 4, 5) -> 2번 정점이 0번 정점을 선행하고 있기 때문.
위상 정렬 알고리즘
1. 진입 차수가 0인 정점을 선택.
2. 선택된 정점과 해당 정점에 연결된 모든 간선을 삭제.
3. 기존 진입 차수가 0이었던 정점과 간선을 삭제함으로써 새로이 진입 차수가 0인 정점 및 간선의 선택과 삭제를 반복.
4. 모든 정점이 선택 - 삭제되면 알고리즘이 종료.
- 선택되는 정점의 순서 == 위상 순서
- 진입 차수가 0인 정점이 여러개 존재할 경우 아무거나 선택.
- 위와 같은 경우 복수의 위상 순서 존재 가능.
위상 정렬 알고리즘 - pseudo code
// Input : 그래프 G = (V, E)
// Output : 위상 정렬 순서
topo_sort(G)
for i ← 0 to n - 1 do
if(모든 정점이 선행 정점을 가지면)
then 사이클이 존재하고 위상 정렬 불가;
선행 정점을 가지지 않는 정점 v 선택;
v를 출력;
v와 v에서 나온 모든 간선들을 그래프에서 삭제;
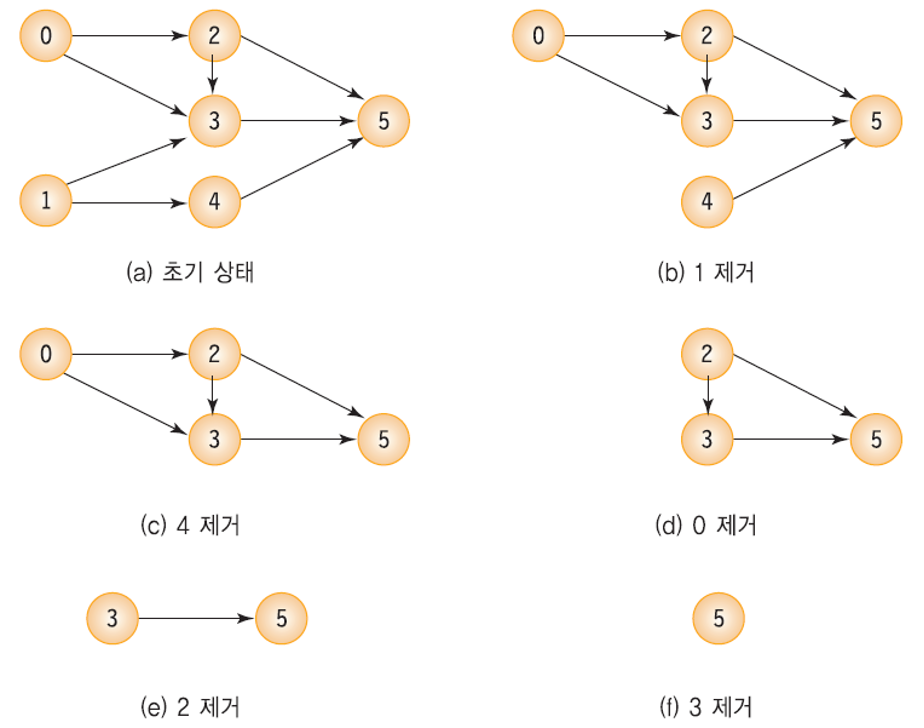
위상 정렬의 과정
- 내차수가 0인 정점 1과 연결된 간선을 제거하면 내차수가 0인 정점은 {0, 4} 가 된다.
- 둘 중 정점 4를 선택, 삭제 한다면 다음 단계에서 내차수가 0인 정점은 {0} 만 남게 된다.
- 따라서 0을 선택, 삭제한 후 내차수가 0이 된 정점 2 제거 -> 정점 3 제거 -> 정점 5 제거 순으로 진행된다.
- 결과로 1, 4, 0, 2, 3, 5 가 도출된다 (== 위상 순서).
위상 정렬 알고리즘의 구현
1. 각 정점의 진입 차수를 기록할 1차원 배열 in_degree 생성. -> 정점에 연결된 간선의 개수
2. 정점 i는 in_degree가 0인 경우 후보 정점이 된다.
3. 정점이 삭제되면 해당 정점에 인접한 정점의 in_degree는 1이 감소.
4. 후보 정점들은 스택에 push하여 저장해두고, 각 단계마다 pop하여 출력 후 인접 정점들의 in_degree를 감소시킨다.
5. 위 과정을 전체 정점이 출력될 때까지 반복한다.
/* 위상 정렬 알고리즘 */
#include <stdio.h>
#include <stdlib.h>
#define TRUE 1
#define FALSE 0
#define MAX_VERTICES 50
typedef struct GraphNode{
int vertex;
struct GraphNode *link;
}GraphNode;
typedef struct GraphType {
int n; // 정점의 개수
GraphNode *adj_list[MAX_VERTICES];
}GraphType;
// 그래프 초기화
void init_graph(GraphType *g){
g->n = 0;
for(int v = 0; v < g->n; v++){
g->adj_list[v] = NULL;
}
}
void insert_vertex(GraphType *g, int v){
if(((g->n) + 1) > MAX_VERTICES){
fprintf(stderr, "그래프: 정점의 개수 초과");
return;
}
g->n++;
}
// 간선 삽입 연산, v를 u의 인접 리스트에 삽입한다.
void insert_edge(GraphType *g, int u, int v){
GraphNode *node;
if(u >= g->n || v >= g->n){
fprintf(stderr, "그래프 : 정점 번호 오류");
return;
}
node = (GraphNode *)malloc(sizeof(GraphNode));
node->vertex = v;
node->link = g->adj_list[u];
g->adj_list[u] = node;
}
#define MAX_STACK_SIZE 100
typedef int element;
typedef struct {
element stack[MAX_STACK_SIZE];
int top;
}StackType;
// 스택 초기화 함수
void init_stack(StackType *s){
s->top = -1;
}
// 공백 상태 검출 함수
int is_empty(StackType *s){
return s->top == -1;
}
// 포화 상태 검출 함수
int is_full(StackType *s){
return (s->top == (MAX_STACK_SIZE - 1));
}
// 삽입 함수
void push(StackType *s, element item){
if(is_full(s)){
fprintf(stderr, "스택 포화 에러\n");
return;
}
s->top++;
s->stack[s->top] = item;
}
// 삭제 함수
element pop(StackType *s){
if(is_empty(s)){
fprintf(stderr, "스택이 공백 상태입니다.\n");
exit(1);
}
else return s->stack[(s->top)--];
}
// 위상 정렬 알고리즘
int in_degree[MAX_VERTICES];
int topo_sort(GraphType *g){
int i;
StackType s;
GraphNode *node;
int *in_degree = (int*)malloc(g->n * sizeof(int));
// 진입 차수 배열 초기화
for(i = 0; i < g->n; i++){
in_degree[i] = 0;
}
// 모든 정점의 진입 차수 계산
for(i = 0; i < g->n; i++){
node = g->adj_list[i];
while(node != NULL){
in_degree[node->vertex]++;
node = node->link;
}
}
// 진입 차수가 0인 정점을 스택에 삽입
init_stack(&s);
for(i = 0; i < g->n; i++){
if(in_degree[i] == 0){
push(&s, i);
}
}
// 위상 순서를 생성
while(!is_empty(&s)){
int w;
w = pop(&s);
printf("정점 %d ->", w); // 정점 출력
node = g->adj_list[w]; // 각 정점의 진입 차수를 변경
while (node != NULL){
int u = node->vertex;
in_degree[u]--; // 진입 차수 1 감소
if(in_degree[u] == 0){ // 내차수 0이 될 시 스택에 삽입.
push(&s, u);
}
node = node->link; // 다음 정점
}
}
free(in_degree);
printf("\n");
return (i == g->n); // 반환 값이 1이면 성공, 0이면 실패.
}
int main(void) {
GraphType *g = (GraphType*)malloc(sizeof(GraphType));
init_graph(g);
insert_vertex(g, 0); insert_vertex(g, 1);
insert_vertex(g, 2); insert_vertex(g, 3);
insert_vertex(g, 4); insert_vertex(g, 5);
//정점 0의 인접 리스트 생성
insert_edge(g, 0, 2); insert_edge(g, 0, 3);
//정점 1의 인접 리스트 생성
insert_edge(g, 1, 3); insert_edge(g, 1, 4);
//정점 2의 인접 리스트 생성
insert_edge(g, 2, 3); insert_edge(g, 2, 5);
//정점 3의 인접 리스트 생성
insert_edge(g, 3, 5);
//정점 4의 인접 리스트 생성
insert_edge(g, 4, 5);
//위상 정렬
topo_sort(g);
free(g);
return 0;
}
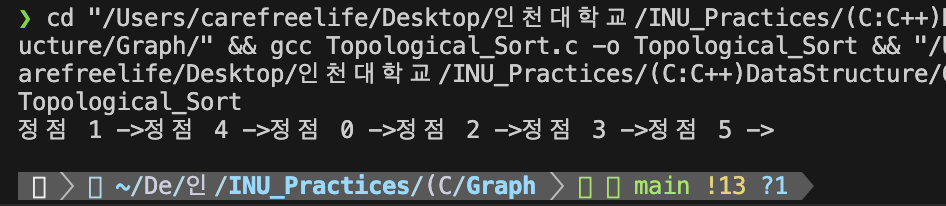
위상 정렬 알고리즘 실행 결과
최대한의 설명을 코드 블럭 내의 주석으로 달아 놓았습니다.
혹시 이해가 안가거나 추가적인 설명이 필요한 부분, 오류 등의 피드백은 언제든지 환영합니다!
긴 글 읽어주셔서 감사합니다. 포스팅을 마칩니다.
참고: C언어로 쉽게 풀어쓴 자료구조 <개정 3판> 천인국, 공용해, 하상국 지음
Task Lists
- 최단 경로 (Shortest path) 문제
- Dijkstra의 최단 경로 알고리즘
- Dijkstra 알고리즘의 구현
- Floyd 의 최단 경로 알고리즘
- Floyd의 최단 경로 프로그램 구현
- 위상 정렬 (Topological Sort) 이란?
- 위상 정렬 알고리즘의 구현



Comments