
Python : 난수 모듈 Random / 집합 자료형 set / 튜플 자료형 ()
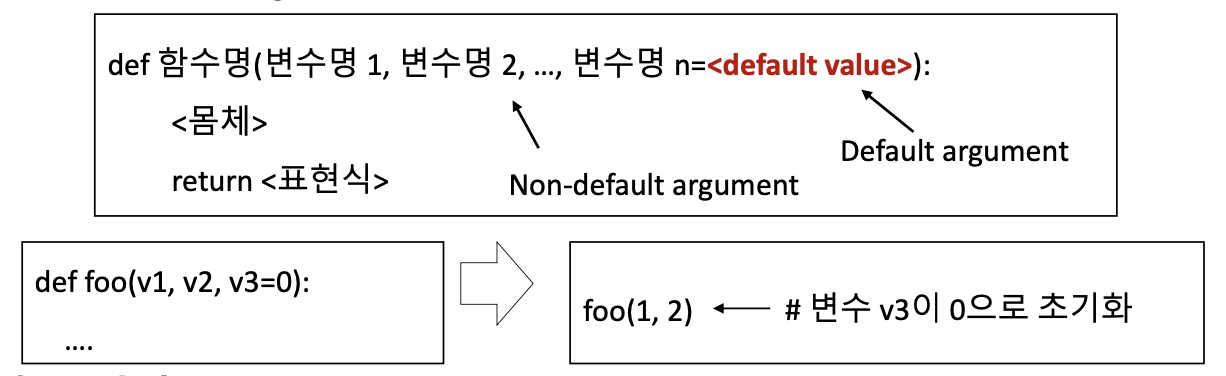
함수 파라미터 초기화 (Parameter Initialization)
함수 선언 시점에 매개 변수를 초기화 할 수 있다.
- def 함수명(변수명 1, 변수명 2, ..., 변수명 n=<default value>):
함수의 호출 (Call) 시 입력되지 않은 매개변수에 대한 자동 초기화를 설정 할 수 있다.
- Default Argument는 무조건 뒤에 위치해야 한다.
함수 선언과 동시에 매개변수 초기화
- 위와 같이 매개변수를 초기화 해두면 함수 호출시 프로그래머가 해당 매개변수를 “반드시 입력” 하지 않아도 된다.
- 함수의 가장 마지막 매개변수로서 초기화 된 변수가 입력이 되지 않으면 자동으로 초기화 값이 입력된다.
- 다양한 기능의 구현이 용이해진다.
- 사용자(프로그래머)에게 편의성 제공.
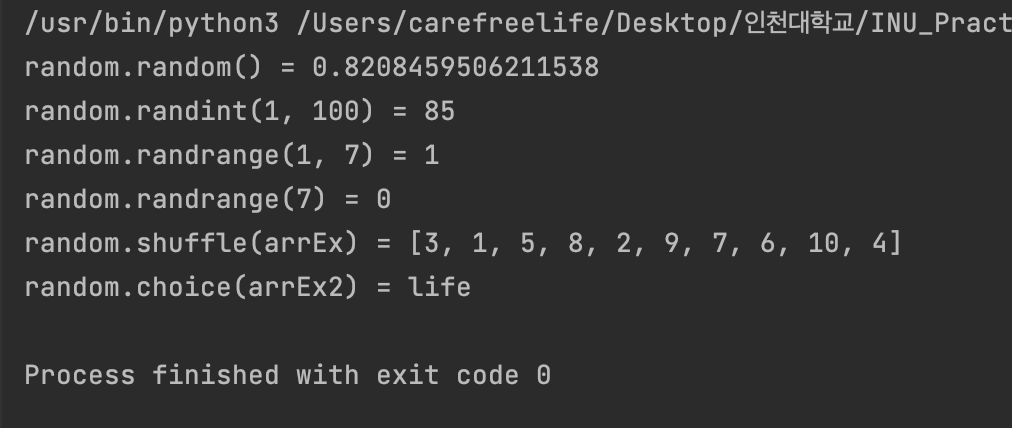
난수 발생 모듈
# random 모듈 (import random): 난수 관련 메소드들이 모여져 있는 모듈
# 난수 관련 메소드
import random
random() # 0에서 1 사이의 난수를 발생 (0.0 <= X < 1.0)
# 시작 범위(start)와 끝 범위(end) 사이(closed)에 있는 난수(정수)를 발생
# start <= X <= end
randint(start, end)
# range() 함수에서 정의하는 범위의 난수(정수)를 발생
# x <= n < y
randrange(x, y)
# range() 함수에서 정의하는 범위의 난수(정수)를 발생
# 0 <= n < y
randrange(y)
# 리스트의 원소를 섞어 놓음
# 내부 인자가 변경가능한 list 데이터 타입만 사용가능. (문자열, 튜플, range(a, b) 불가)
shuffle()
# 리스트의 원소 중 하나를 고름 (리스트, 튜플, 문자열, range)
choice(seq)
import random
print(f"random.random() = {random.random()}")
print(f"random.randint(1, 100) = {random.randint(1, 100)}")
print(f"random.randrange(1, 7) = {random.randrange(1, 7)}")
print(f"random.randrange(7) = {random.randrange(7)}")
arrEx = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.shuffle(arrEx)
print(f"random.shuffle(arrEx) = {arrEx}")
arrEx2 = ('care', 'free', 'life')
print(f"random.choice(arrEx2) = {random.choice(arrEx2)}")
random 모듈 사용 결과
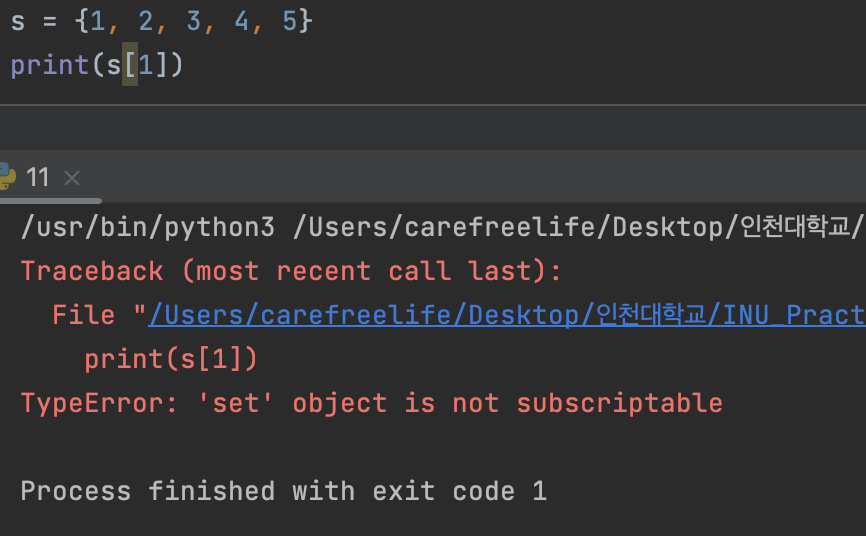
집합(set) 자료형
Collection 자료형에 속하는 자료형
- Collection: 데이터를 모아놓은 자료형
- 집합(Set)
- 사전(Dictionary)
- etc..
"순서"가 없으므로 순서열 관련 자료형 (list, tuple 등)과는 다름.
"숫자" 데이터에 한해서 오름차 순으로 자동정렬이 발생한다.
- 자료형 내에 순서가 존재하지 않으며, 중복을 허용하지 않음.
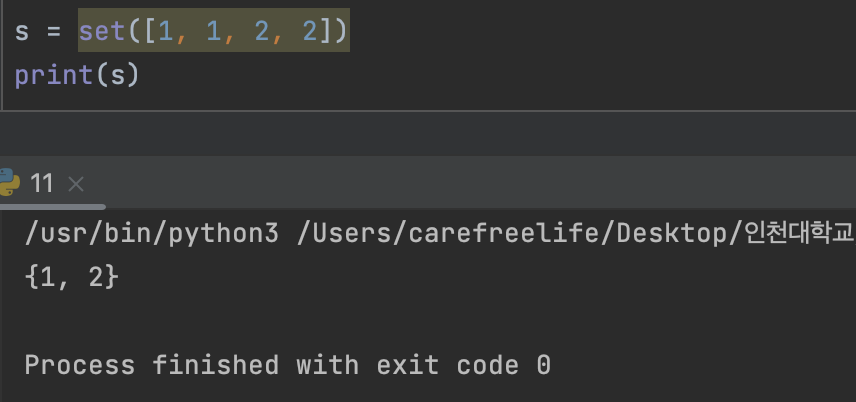
- 집합 자료형의 생성 : set() / {요소1, 요소2, …}
- index 를 사용하여 접근할 수 없음. (순서가 존재하지 않기 때문에)
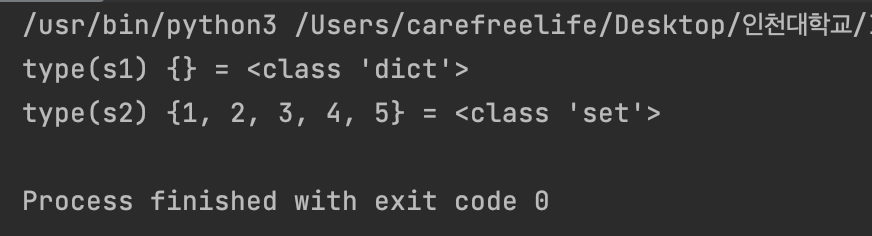
set() 자료형은 index 사용 불가- {} 안에 요소를 넣지 않고 초기화 하게 되면 set() 이 아닌 dict() 자료형으로 생성됨.
set() / dict()
집합 자료형의 생성
- List 로부터의 set 생성
- 중복 원소들이 제거된다.
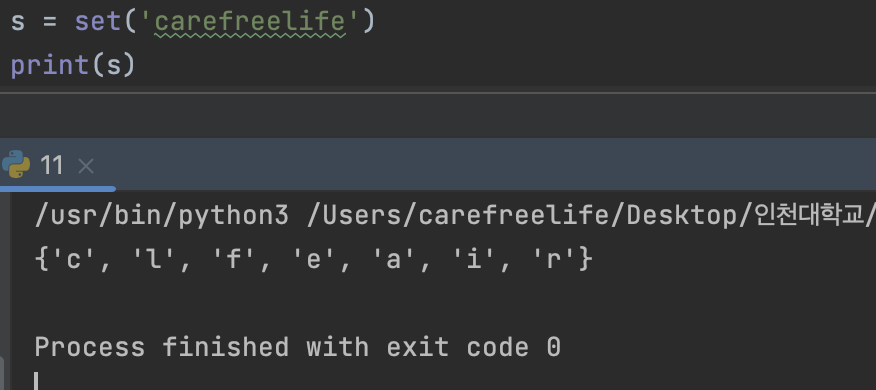
set()은 중복 요소를 허용하지 않는다.- 문자열로부터의 set 생성
문자열을 set에 삽입 할 수 있다. 각 중복 문자는 삭제된다.
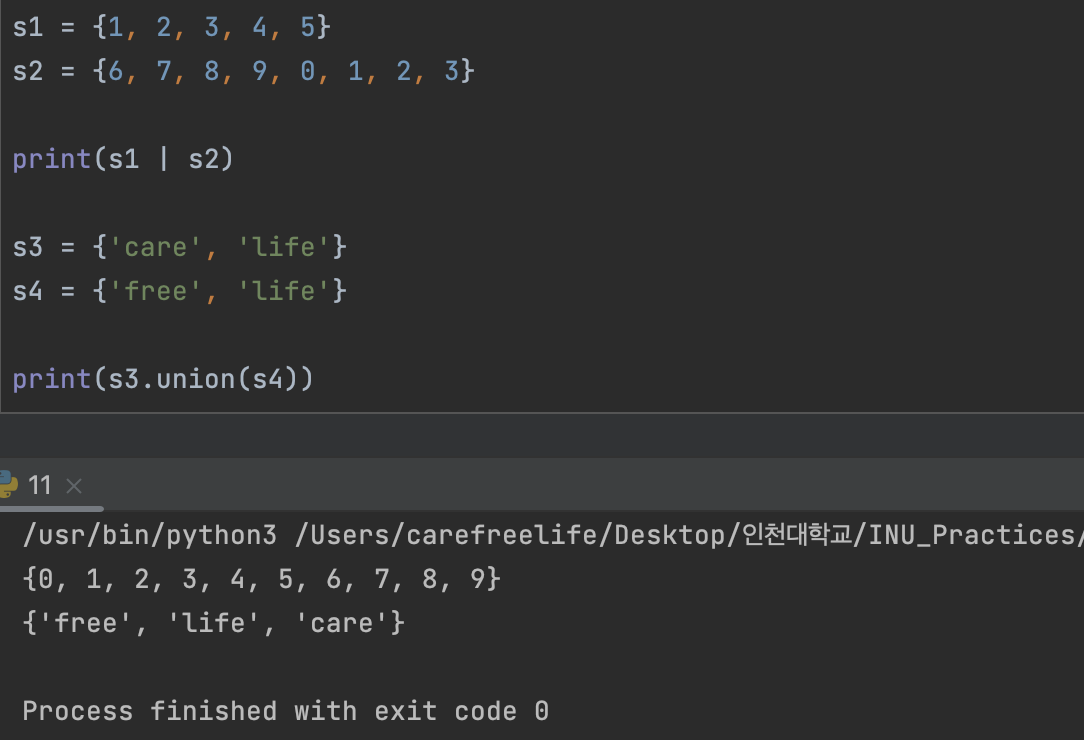
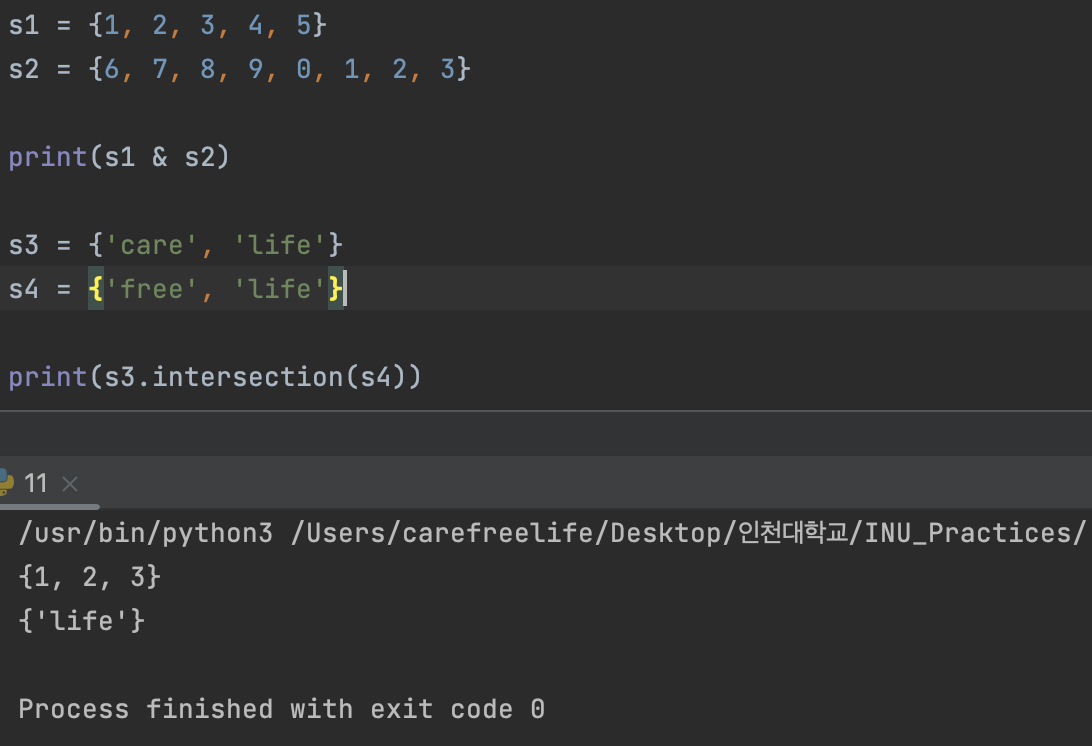
집합 자료형 간의 연산
- 집합 간의 기본 연산
1. 합집합: “|” , union() 을 사용
- ”|” != “or” : or 연산자는 합집합 연산과 관련이 없다.
"|" 와 .union() 연산자를 통해 집합간의 합연산이 가능
2. 교집합: “&”, intersection() 을 사용- “&” != “and” : and 연산자는 교집합 연산과 관련이 없다.
"&" 와 .intersection() 연산자를 통해 교집합 연산이 가능
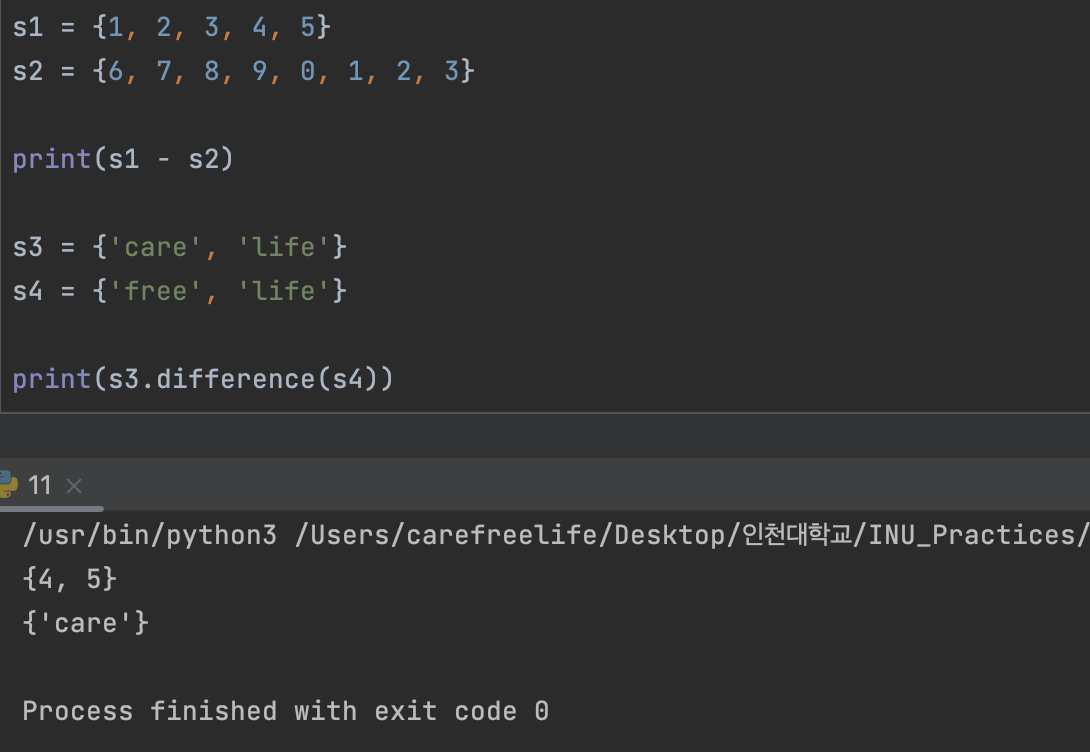
3. 차집합: “-“ , difference() 를 사용
"-" 와 .difference() 연산자를 통해 차집합 연산이 가능
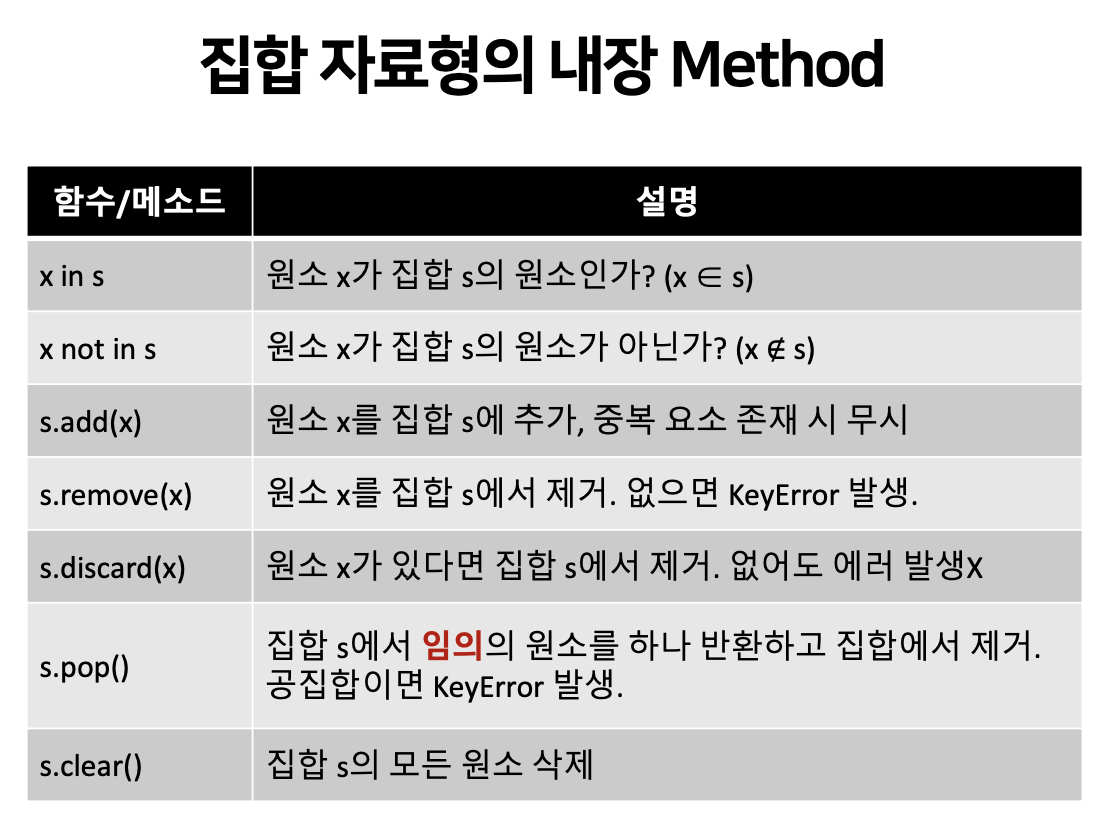
집합 자료형의 내장 Method
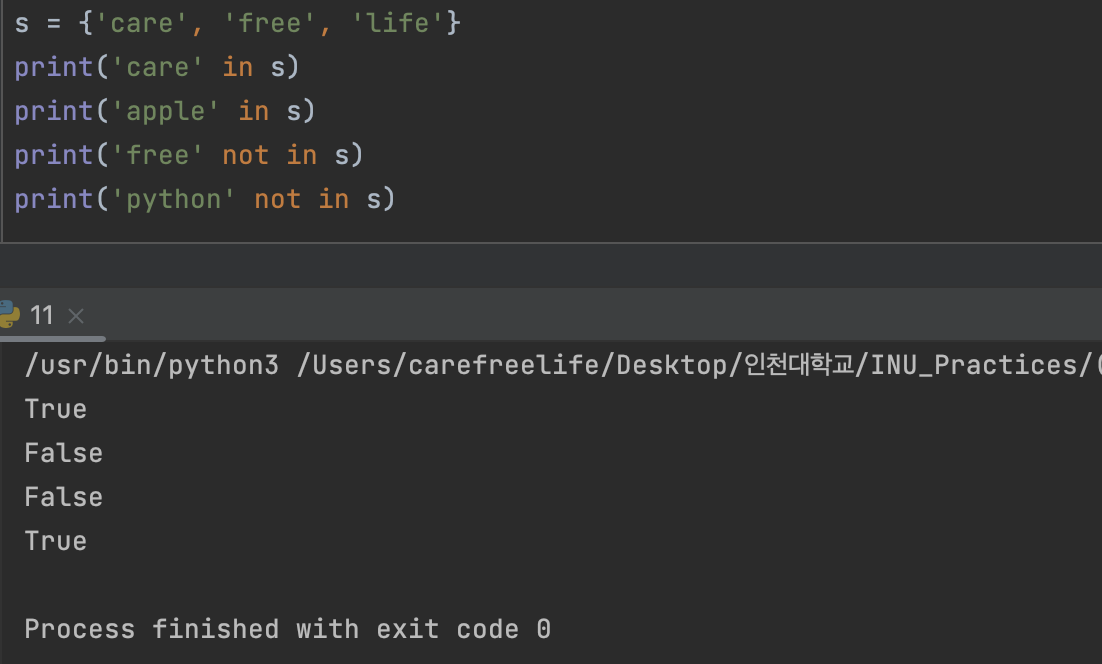
집합 자료형의 내장 Method1. in / not in
- 요소의 존재 여부를 확인할 때 사용
in / not in 사용 예제- 리스트 자료형 에서도 사용 가능.
- List : 순차 검색
- Set : 해쉬(hash)기반 검색
- set 에서의 hash 기반 검색이 훨씬 빠르다.
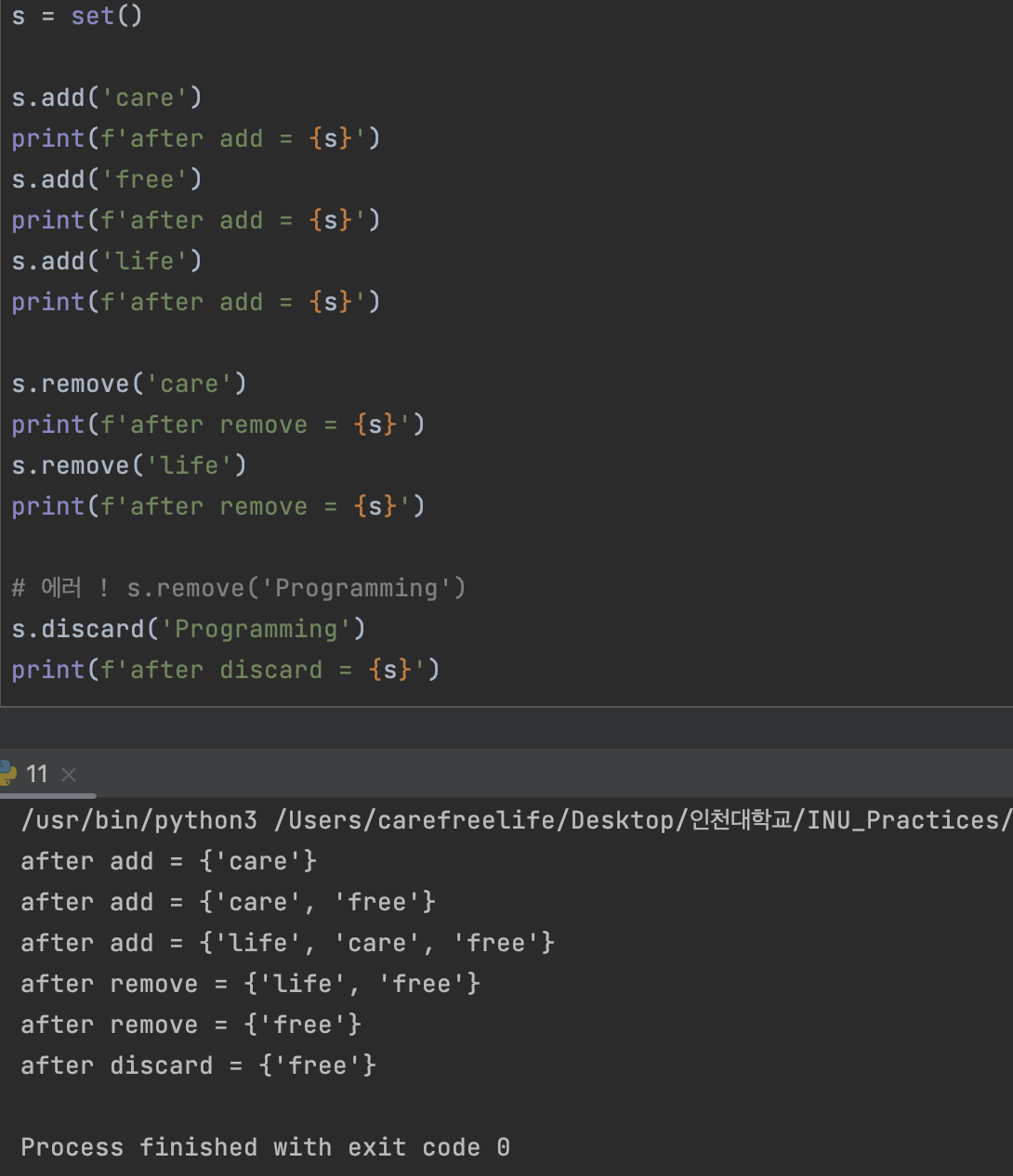
2. add / remove / discard
- 요소의 추가 및 삭제 메소드
- 요소의 추가: add
- 요소의 삭제:
- remove(e) : e를 set 에서 삭제한다. 만약 e가 set 에 존재하지 않으면 에러발생.
- discard(e) : e를 set 에서 삭제한다. e가 set에 존재하지 않아도 실행됨. 아무튼 set에 e가 없으면 된다는 식.
set 자료형의 삽입 및 삭제 메소드
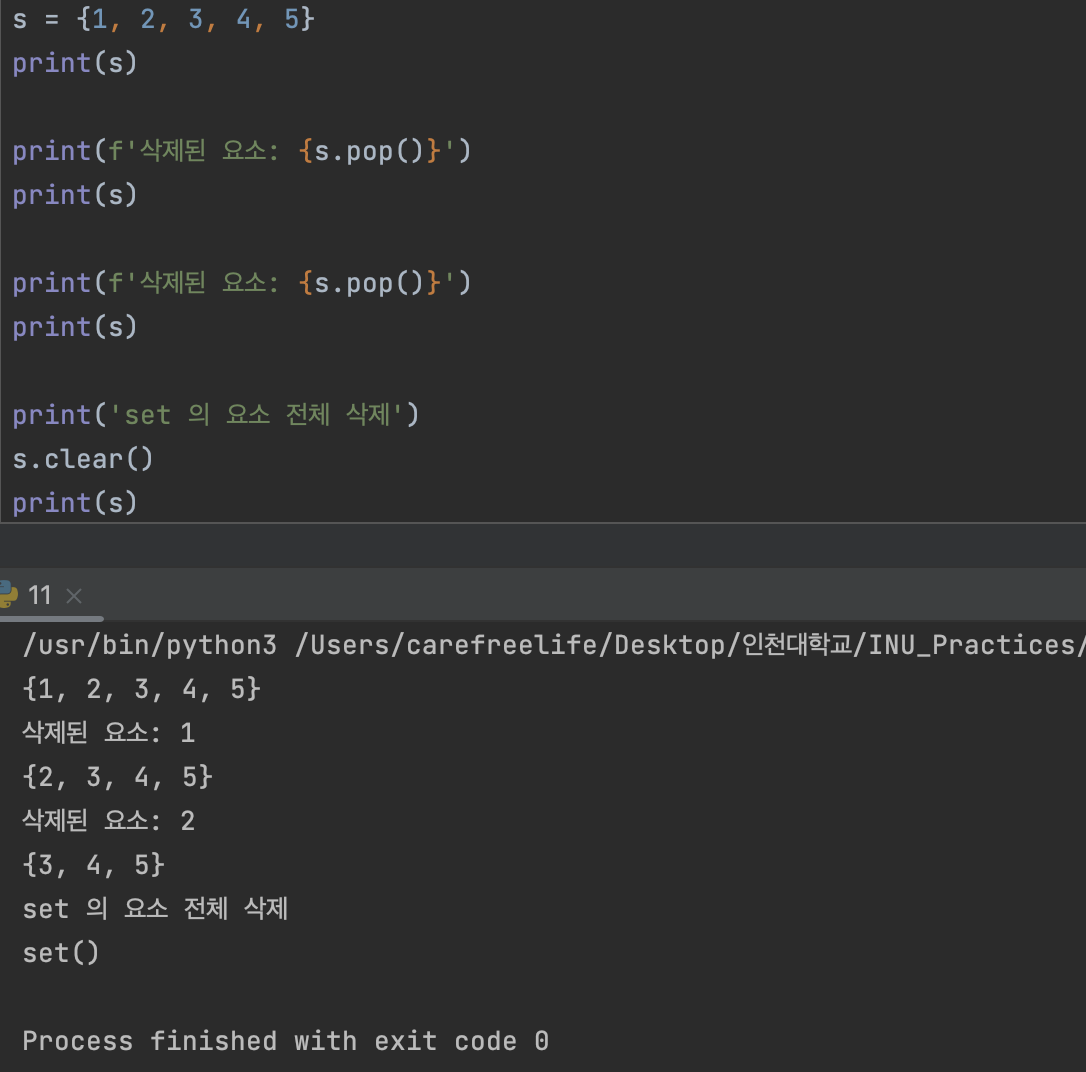
3. pop / clear
- pop : set 에서 첫번째 위치에 저장된 요소를 반환
- 비어있는 set 에서 pop()을 실행 시 에러 발생
- clear : set 에 속한 요소를 전부 삭제 (반환 x)
set 자료형의 pop() / clear() 메소드
튜플(Tuple) 자료형
- 순서가 있고 (Ordered), 변경이 없는 (Immutable) 데이터의 집합을 표현하기 위해 만들어진 자료형
- 튜플 자료형의 생성 : tuple() / ()
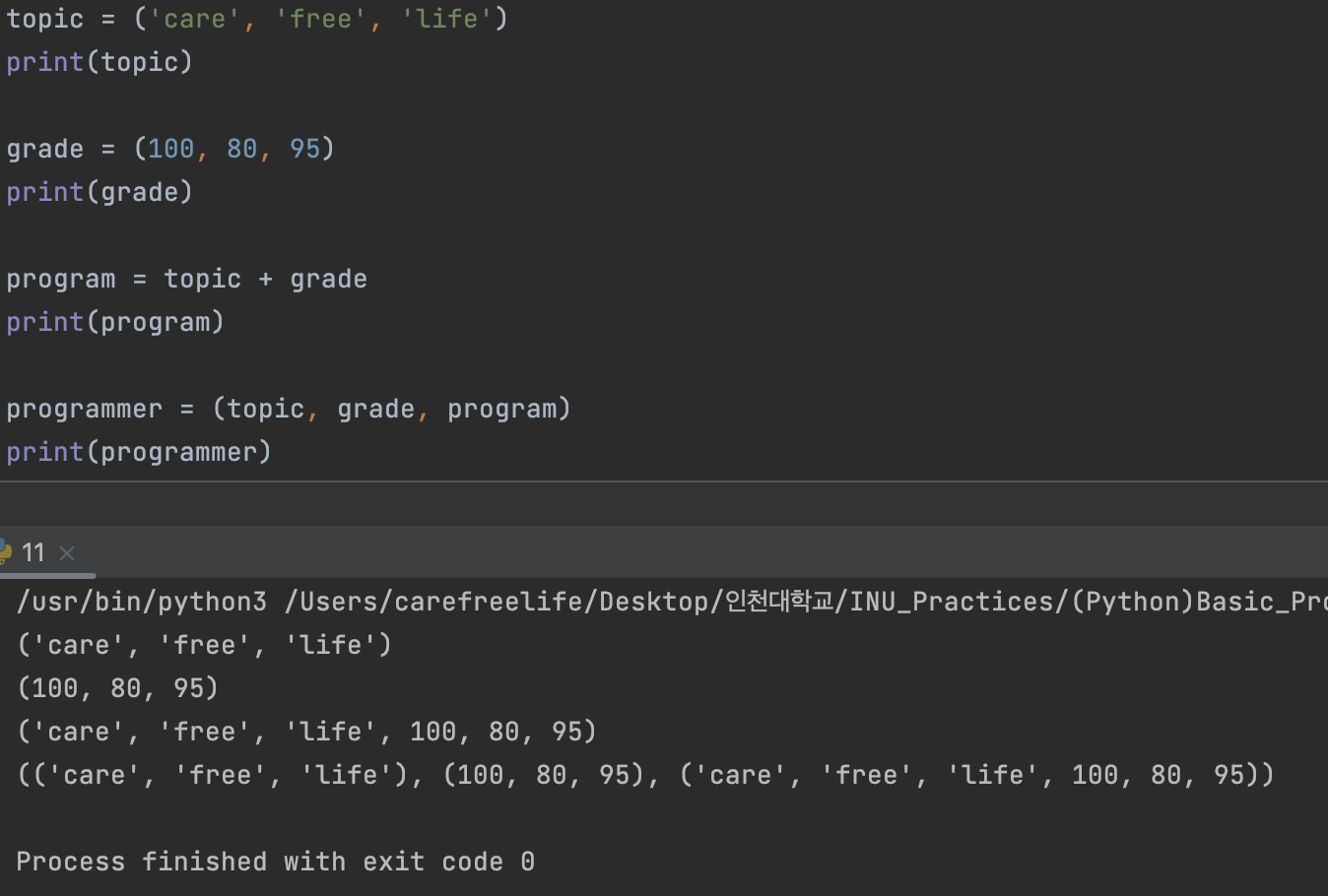
- 여러 종류의 데이터가 하나의 튜플에 존재 할 수 있다.
- 한 튜플 자료형의 요소로서 다른 튜플 자료형이 존재 할 수 있다.
tuple 자료형의 기본 연산
튜플 자료형에서의 요소 접근
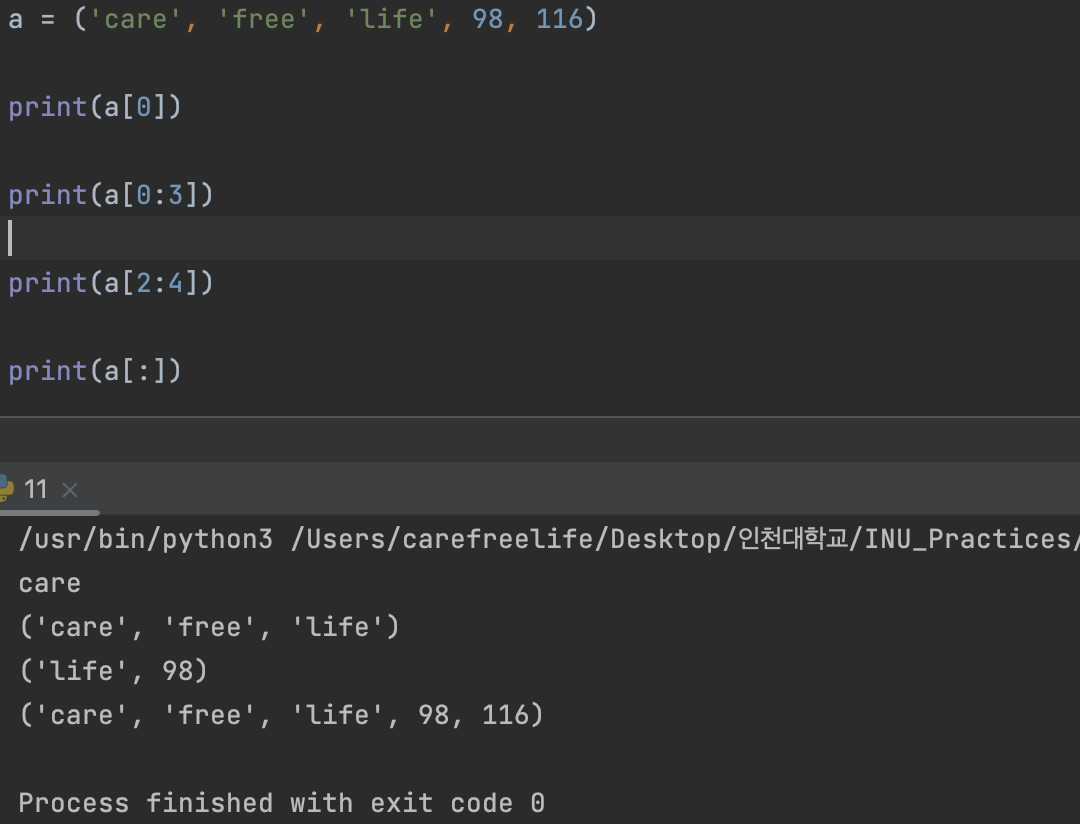
- 인덱싱(indexing), 슬라이싱(slicing) 모두 가능
- List와 동일
튜플 자료형 - 인덱싱, 슬라이싱- 함수에서 복수 개의 데이터를 반환할 때 사용하면 편리
튜플 자료형 - 사용 예시
List와 Tuple의 주요 차이점
- Immutable (데이터의 수정 불가)
- 해당 자료형의 요소들이 변경되면 안되거나 변경할 이유가 없을 때 tuple 사용
- (ex. 함수의 return 값)
- 자료형의 요소가 변경 가능해야 한다면 list 사용
Tuple 자료형은 요소의 변경이 불가능- 메모리 할당 (Memory Allocation) 의 차이
- 요소의 개수나 크기가 작은 경우, list가 메모리를 적게 사용
- 요소의 개수가 커질 경우 list가 더 큰 메모리를 사용
- 일반적인 경우 tuple이 더 적은 메모리를 사용
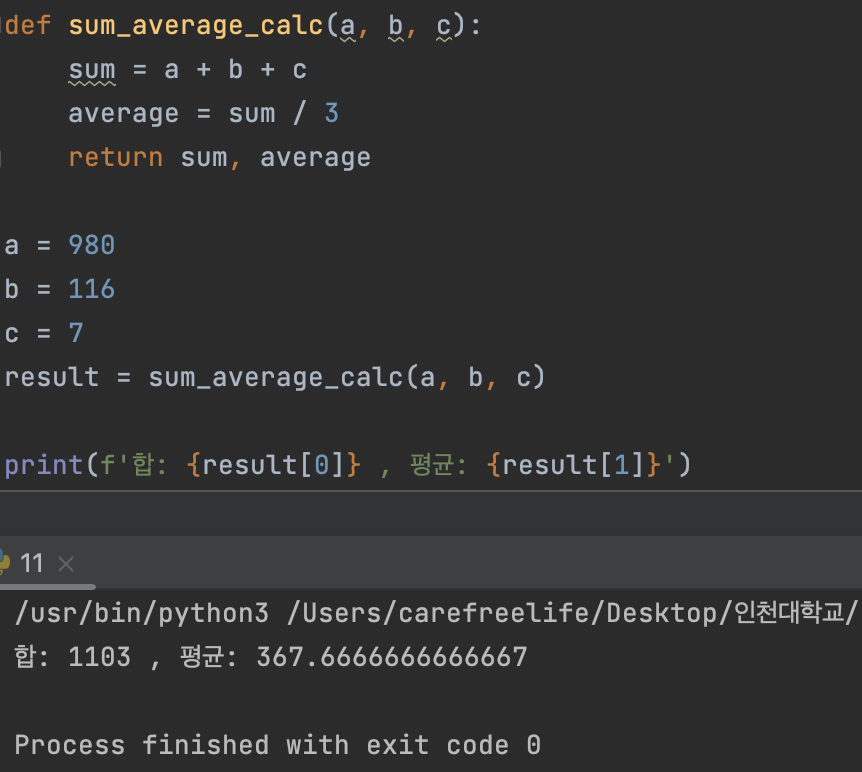
예제 1. find 함수 구현
• 문자열 함수 find() 구현
• find(tgt, pattn, start=0)
• (string) tgt: 찾고자 하는 대상 문자열
• (string) pattn : 찾으려는 패턴
• start: tgt 에서 찾기 시작할 지점
→ 찾을 시 tgt 내에서 첫번째로 pattn 이 발견된 시작위치를 반환, 패턴이 존재하지 않을 때는 -1 반환
>>> find(“abcde”, “f”)
-1
>>> find(“abcde”, “a”)
0
>>> find(“abcde”, “a”, 1)
-1
>>> find(“abcde”, “c”, 2)
2
# find 함수 구현
def find(tgt, pattn, start=0):
len_pattn = len(pattn)
for i in range(start, len(tgt)):
substr = tgt[i:i+len_pattn]
if substr == pattn:
return i
return -1
if __name__ == '__main__':
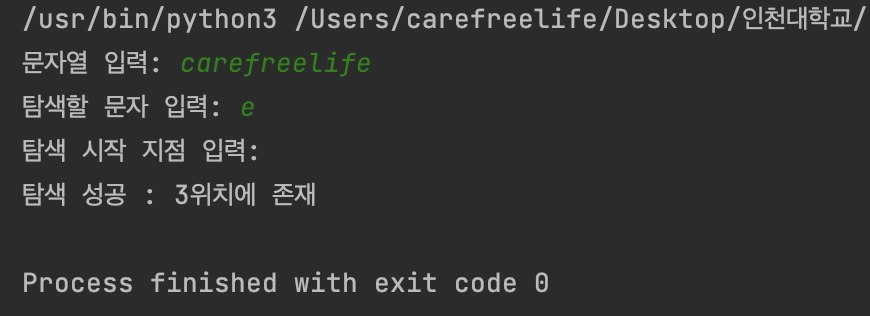
a = input('문자열 입력: ')
b = input('탐색할 문자 입력: ')
c = input('탐색 시작 지점 입력: ')
if c == '':
c = 0
else:
c = int(c)
result = find(a, b, c)
if result != -1:
print(f'탐색 성공 : {result} 위치에 존재')
else:
print('탐색 실패')
예제 - 1 실행 결과
예제 2. 두 수의 합
• 리스트 길이 N과 찾으려는 값k를 표준 입력받음
• 1~N*2 사이의 난수를 각 요소로 갖는 리스트 생성
• 예) N=10인 경우 1부터 20 사이의 난수를 발생시켜서 10개의 요소를 가진 리스트 생성 (중복 없이)
• 리스트 내 임의의 두 원소를 더한 합이 k인 경우를 찾아, 두 원소가 각각 리스트의 몇 번째 원소인지 출력
>>>
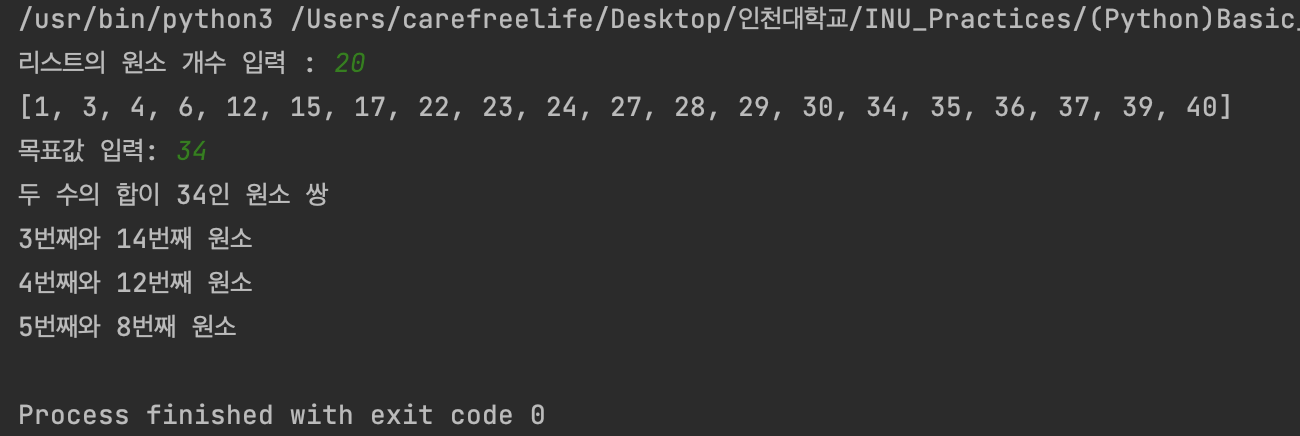
리스트의 원소 개수 입력 : 13
[1, 6, 7, 8, 11, 12, 13, 16, 17, 18, 19, 25, 26]
목표값 입력: 23
두 수의 합이 23인 원소 쌍
2번째와 9번째 원소
3번째와 8번째 원소
5번째와 6번째 원소
>>>
import random
def rand_sum_to_target(num, tgt):
l = list()
s = set()
while len(s) != num:
rand = random.randint(1, num * 2)
if rand in s:
continue
l.append(rand)
s.add(rand)
print(l)
for i in range(num):
for j in range(i, num):
if l[i] + l[j] == tgt:
print(f'{i} 번째와 {j} 번째 요소')
if __name__ == '__main__':
n = int(input('난수의 개수 입력: '))
tgt = int(input('목표 숫자 입력: '))
rand_sum_to_target(n, tgt)
예제 - 2 실행 결과
예제 3. 최장 연속 순차
1. 생성할 난수의 개수 N을 표준입력 받음
2. 1~N*2 사이의 난수를 각 요소로 갖는,길이가 N인 리스트 생성
3. 집합 자료형을 사용하여 리스트 내 “최장 연속 순차” 길이를 표준출력
- 이때, 생성된 리스트와 집합을 모두 출력
>>>
난수의 개수 입력 : 10
리스트 : [8, 3, 1, 8, 9, 3, 8, 2, 4, 1]
집합 : {1, 2, 3, 4, 8, 9}
최장 연속 순차의 길이 : 4
>>>
난수의 개수 입력 : 15
리스트 : [8, 1, 15, 13, 13, 3, 15, 6, 5, 6, 12, 5, 9, 7, 4]
집합 : {1, 3, 4, 5, 6, 7, 8, 9, 12, 13, 15}
최장 연속 순차의 길이 : 7
import random
N = input('리스트의 원소 개수 입력 : ')
try:
N = int(N)
l = []
s = set()
while len(l) < N:
number = random.randint(1, 2*N)
# 중복이 없는 난수 리스트 생성
if number not in s:
l.append(number)
s.add(number)
l.sort()
print(l)
k = int(input('목표값 입력: '))
print(f'두 수의 합이 {k}인 원소 쌍')
i = 0; j = N-1
while i < j:
total = l[i] + l[j]
if total == k:
print(f'{i+1}번째와 {j+1}번째 원소')
i += 1; j -= 1
elif total < k:
i += 1
else:
j -= 1
except Exception as e:
print(e)
print('잘못된 입력입니다')
예제 - 3 실행 결과
<!– ><br><br> `사진출처:`[]() <span style="color:green"></span>

(1) 소스 코드 보기 (클릭)
–>
최대한의 설명을 코드 블럭 내의 주석으로 달아 놓았습니다.
혹시 이해가 안가거나 추가적인 설명이 필요한 부분, 오류 등의 피드백은 언제든지 환영합니다!
긴 글 읽어주셔서 감사합니다. 포스팅을 마칩니다.
Task Lists
- 함수 파라미터 초기화 (Parameter Initialization)
- 난수 발생 모듈
- 집합(set) 자료형
- 집합 자료형의 생성
- 집합 자료형 간의 연산
- 집합 자료형의 내장 Method
- 튜플(Tuple) 자료형
- 튜플 자료형에서의 요소 접근
- List와 Tuple의 주요 차이점
- 예제 1. find 함수 구현
- 예제 2. 두 수의 합
- 예제 3. 최장 연속 순차



Comments