
Python : 리스트 관련 유용한 내장 함수 : map / filter / zip / reduce / enumerate
리스트 관련 유용한 내장 함수 : map / filter / zip / reduce / enumerate
map()
- 리스트 내 각 요소들에 동일하게 간단한 연산을 적용할 때 사용
- 형변환 (int, string, float, …)
- 동일한 값 뺄셈
- …
- 주로 이름 없는 함수인 Lambda 함수로 연산을 정의한 후 이를 각 요소에 적용하는 형태
- 이때, lambda 함수의 인자 개수는 반드시 1개.
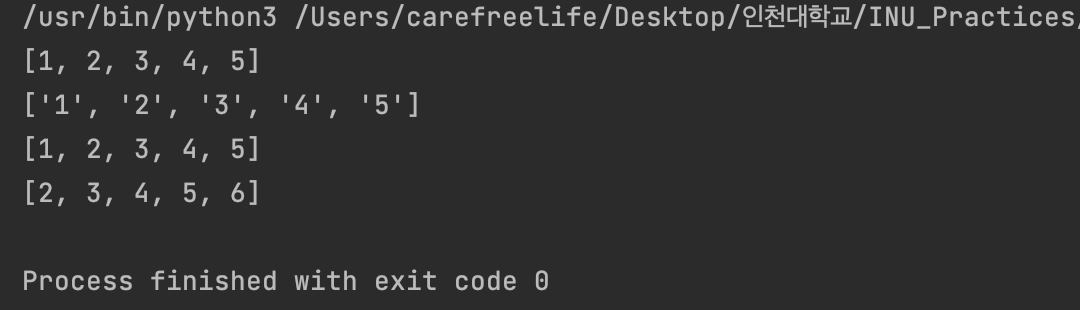
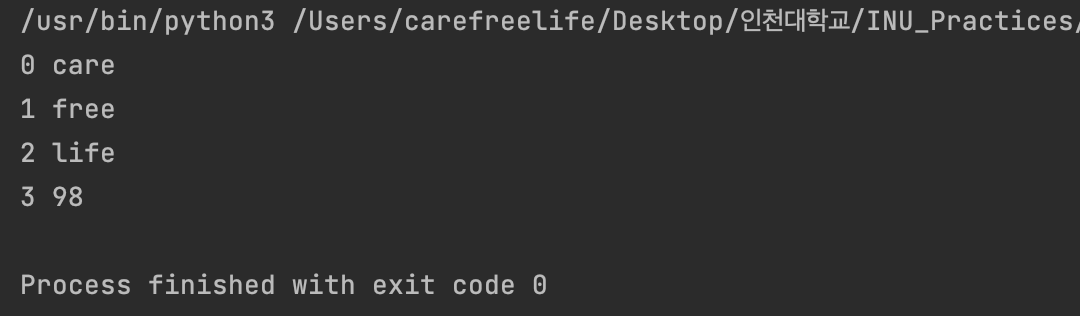
//map a = [1, 2, 3, 4, 5] print(a) a = list(map(str, a)) //list내의 요소들 type을 str로 변환 print(a) a = list(map(int, a)) //list내의 요소들 type을 int로 변환 print(a) a = list(map(lambda x: x+1, a)) //list 내의 요소 값 1씩 증가 print(a)
map() 함수 및 lambda 함수 적용
filter()
- 리스트 내 요소들을 특정 기준으로 필터링 할때 사용
- 즉, 특정 기준을 만족하는 요소만 추출 가능
- lambda 함수로 filtering 기준 판단 연산을 정의 후 각 요소에 적용하도록 하는 형태.
- lambda 함수에서 True 로 판단된 요소들만 추출.
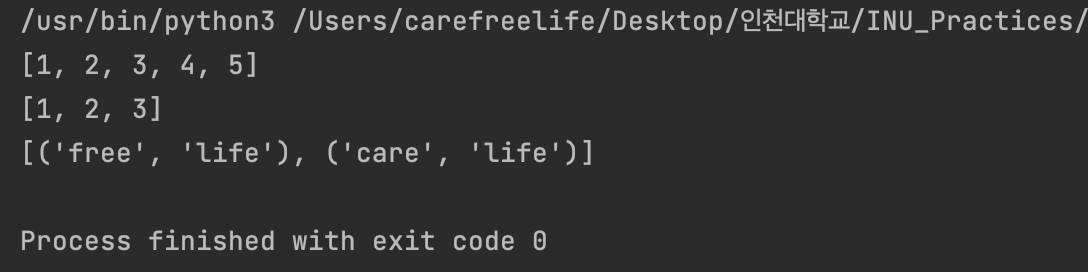
// filter() a = [1, 2, 3, 4, 5] print(a) a = list(filter(lambda x: x < 4, a)) //list a 에서 4보다 작은 요소 반환 print(a) b = [('care', 'free', 'life'), ('free', 'life'), ('care', 'life')] b = list(filter(lambda x: len(x) == 2, b)) //길이가 2인 요소 반환 print(b)
filter() 함수 및 lambda 함수 적용
zip()
- 서로 다른 두 리스트의 동일한 index의 요소들끼리 묶어서 계산할 때 사용
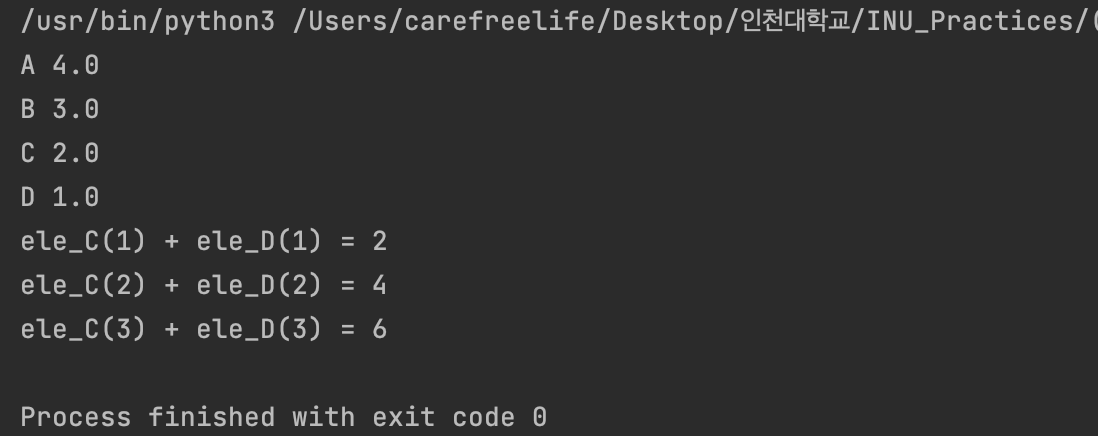
// zip() a = ['A', 'B', 'C', 'D'] b = [4.0, 3.0, 2.0, 1.0] for ele_A, ele_B in zip(a, b): print(ele_A, ele_B) // 인덱스 순서로 list a 와 b의 요소를 동시에 출력 // 두 리스트의 길이가 다른 경우에는 길이가 더 짧은 리스트의 최대 index까지 실행. c = [1, 2, 3, 4, 5] d = ['1', '2', '3'] for ele_C, ele_D in zip(c, map(int, d)): // list d -> int 형변환 print(f'ele_C({ele_C}) + ele_D({ele_D}) = {ele_C + ele_D}')
zip() 함수 및 lambda 함수의 적용
reduce()
from functools import reduce
- Python 3.~ 부터 import 를 해주어야 사용 가능
- 리스트 내 각 요소들끼리의 점진적 연산을 통해 하나의 값을 도출
- map(), filter() 와 다르게 lambda 함수의 argument가 반드시 2개.
- 현재까지 계산된 값 & 리스트 내 다음 요소
from functools import reduce a = ['care', 'free', 'life', '98'] b = [20170, 27, 97] a = reduce(lambda x, y: x + y, a) b = reduce(lambda x, y: int((x + y) / 3), b) print(a, b)
reduce() 함수 및 lambda 함수의 적용
enumerate()
- 리스트, 집합, 튜플 각각의 요소에 “인덱싱”을 해주는 함수
- 요소만 존재하는 리스트에서 인덱스를 얻고 싶을 때 사용
a = ['care', 'free', 'life', 98] for idx, element in enumerate(a): print(idx, element)
enumerate() 함수 및 lambda 함수의 적용
예제 - map(), reduce(), zip() 활용하기
• 제곱의 평균 구하기:
정수 리스트를 인자로 받아 map(), reduce() 함수를 사용하여 제곱의 평균을 반환하는 함수를 작성
• 벡터의 내적 구하기:
정수 리스트 2개를 인자로 받아 zip() 함수를 활용하여 벡터의 내적을 구해주는 함수를 작성
// 제곱의 평균 구하기
def mean_square(l):
from functools import reduce
l = list(map(lambda x: x * x, l))
print(l)
result = reduce(lambda x, y: x + y, l) / len(l)
return result
// 이렇게 한 줄로 작성할 수도 있다.
def mean_square(l):
len_l = len(l)
return reduce(lambda x, y:x+y, list(map(lambda x:x*x, l))) / len_l
if __name__ == '__main__':
a = [1, 2, 3, 4, 5]
print(f'리스트의 제곱의 평균은 {mean_square(a)} 입니다.')
map(), reduce() 활용하여 리스트의 제곱의 평균 구하기

// 벡터의 내적 구하기
def dot(l1, l2):
print(f'l1 : {l1} , l2: {l2}')
sum = 0
for ele_1, ele_2 in zip(l1, l2):
sum += ele_1 * ele_2
return sum
if __name__ == '__main__':
print(f'벡터의 내적 값은 : {dot([1, 2, 3, 4], [2, 3, 4, 5])}')
최대한의 설명을 코드 블럭 내의 주석으로 달아 놓았습니다.
이해가 안가거나 추가적인 설명이 필요한 부분, 오류 등의 피드백은 언제든지 환영합니다!
긴 글 읽어주셔서 감사합니다. 포스팅을 마칩니다.
Task Lists
- 리스트 관련 유용한 내장 함수 : map / filter / zip / reduce / enumerate
- 예제 - map(), reduce(), zip() 활용하기



Comments