
Python : 문자열 다루기 (시저 암호화, 어구전철 판별)
사전 자료형 (Dictionary)
- 컬렉션 (Collection) : 데이터를 모아 놓은 자료형
- 모아 놓은 데이터 간의 “순서” 가 존재하지 않는다.
- 데이터 간의 순서를 기억 할 필요가 없다. (Good!)
- 집합 (Set)
- 사전 (Dictionary)
- etc…
- 사전 자료형
- Python에서 가장 많이 쓰이는 Powerful 한 자료형.
- Key-Value 형태로 사용.
- 주어진 key 를 넣으면 대응되는 value 가 반환되는 형태이다.
- 사전 자료형의 정의 및 사용
- dict() 혹은 {} 로 최초 정의
- 이후 배열과 같이 [] 안에 key 값을 넣어 value 값을 반환 받을 수 있다.
- 사전 자료형의 [key] 값은 정수 뿐만 아니라 어느 자료형이든 가능하다.
- 또한 key 값 간의 자료형이 같지 않아도 된다.
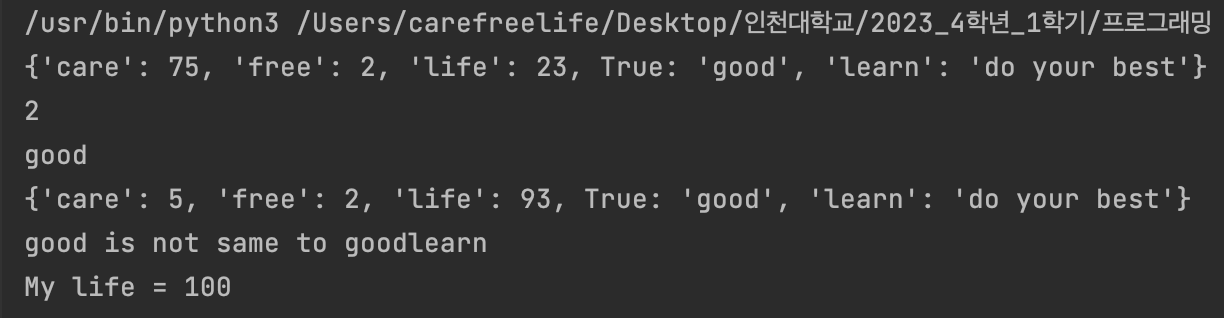
#사전 자료형의 정의 carefreelife = dict() carefreelife['care'] = 75 carefreelife['free'] = 2 carefreelife['life'] = 23 carefreelife[True] = 'good' #key값 간의 자료형이 달라도 되며 어떠한 자료형도 사용 가능. programming = dict() programming[1] = 'learn' #key 값으로 dict() 자료형도 사용 가능. 다중 dict() 자료형 사용이 가능해 보인다. carefreelife[programming[1]] = 'do your best' print(carefreelife) print(carefreelife['free']) print(carefreelife[1]) # 1 == True로 인식하여 반환. #사전 자료형의 사용 1 carefreelife['care'] = carefreelife['care'] - 70 #데이터 수정 carefreelife['life'] = carefreelife['life'] + 70 #데이터 수정 print(carefreelife) #다른 사전 자료형과의 연산 programming[0] = carefreelife[True] + programming[1] if carefreelife[True] != programming[0]: print(carefreelife[True], 'is not same to', programming[0]) #사전 자료형의 사용 2 carefreelife = carefreelife['care']+carefreelife['free']+carefreelife['life'] print(carefreelife)
실행 결과
사전 자료형의 자료 존재 여부 검사
- 해당하는 key의 존재 여부 검사
- 해당 key에 대한 value가 사전 자료형 dict() 내부에 존재한다면 True, 아니면 False 반환.
- 예: names 리스트에 있는 이름을 key, value로 저장
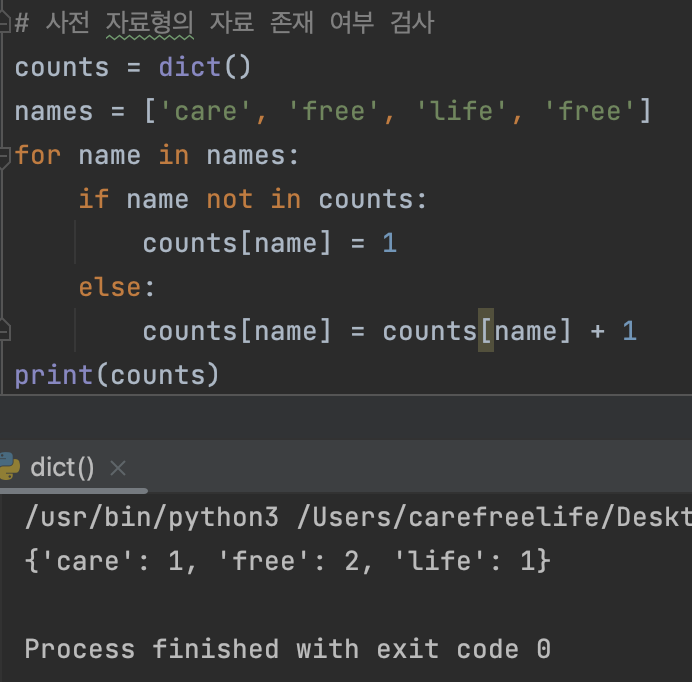
counts = dict() # 사전 자료형 선언
names = ['care', 'free', 'life', 'free'] # 사전 자료형에 삽입할 데이터 리스트
for name in names: # 삽입할 데이터 리스트의 마지막 데이터까지 Loop
if name not in counts: # 사전 자료형에 해당 데이터가 없다면(처음 삽입되는 데이터 라면)
counts[name] = 1 # 사전 자료형에 (key = 데이터, value = 해당 데이터의 삽입 수)형태로 삽입
else:
counts[name] = counts[name] + 1 # 이전에 삽입되었었던 데이터라면 value를 + 1 해준다.
print(counts) # 출력
실행 결과
사전 자료형 관련 내장 메소드
clear() # 모든 key-value 쌍을 제거.
get(key) # key 에 대응하는 value 를 반환.
items() # (key, value)를 하나의 요소로 정의, 전체 요소를 반환.
key() # 사전 자료형의 모든 key들을 반환.
value() # 사전 자료형의 모든 value들을 반환.
# 주어진 key에 대한 value를 반환하고, 해당 key값을 제거.
# Stack 의 pop() 과 비슷한 로직.
pop(key)
# 주어진 새로운 사전 자료형 d의 key, value 값을 추가.
# 기존 자료형에 동일한 key 값이 존재할 경우에는
# 해당 (key, value)값을 d의 (key, value) 값으로 수정.
update(d)
사전 자료형 관련 내장 메소드 예제
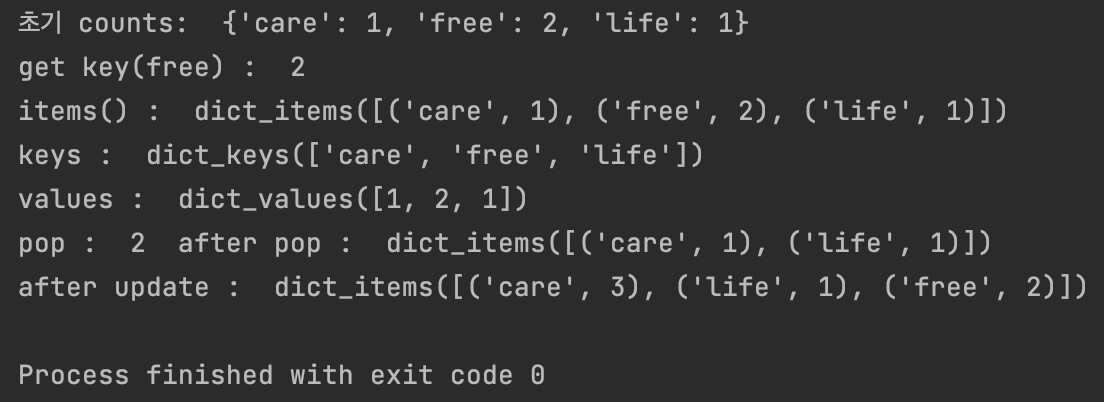
# 사전 자료형 관련 내장 메소드의 사용 # get(key) : key에 대응하는 value를 반환. free = counts.get('free') print('get key(free) : ', free) # 2 # items() : (key, value)를 하나의 요소로 정의하여 전체 요소를 반환. items = counts.items() print('items() : ', items) # dict_items([('care', 1), ('free', 2), ('life', 1)]) # keys() : 사전 자료형의 모든 key들을 반환. keys = counts.keys() print('keys : ', keys) # dict_keys(['care', 'free', 'life']) # values() : 사전 자료형의 모든 value들을 반환. values = counts.values() print('values : ', values) # dict_values([1, 2, 1]) # pop(key) : 주어진 key에 대한 value를 반환하고 해당 key 값을 제거. # Stack에서의 pop()과 같다. pop = counts.pop('free') print('pop : ', pop, ' after pop : ', items) # 2, dict_items([('care', 1), ('life', 1)]) # 주어진 새로운 사전 자료의 key, value 값을 추가. # 만약 기존 데이터와 동일한 key 값을 가진다면 수정. new = dict() # 새로운 사전 자료형 new 선언 new['free'] = 2 # new에 {key = free, value = 2}데이터 삽입 new['care'] = 3 # 기존 사전 자료형 counts에 new 사전 자료형에 있는 데이터를 추가(free, 2) 및 수정(care, 3) counts.update(new) print('after update : ', counts.items()) # update()된 counts 출력
실행 결과
Conter의 동작 원리
Counter 자료형
- 사전 자료형에 기반하여 만들어진 자료형.
- collections 모듈 내부에 존재하는 class(사용자 정의 자료형)이다.
- 문자열을 인자로 받아 문자당 개수를 세어주는 자료형.
- 내부적으로 사전 자료형을 포함하고 있다.
- 동등 비교 연산자 (==) 으로 비교 가능.
-
# Counter class 를 활용한 모습 (어구전철) def isAnagramConter(a, b): from collections import Counter # Counter 선언 # a, b 두개의 String을 파라미터로 받아 유효한 문자열로 추려낸다. a = ''.join(c for c in a if c.isalnum()).lower() # 영문자 or 숫자인 경우 소문자로 변환 b = ''.join(c for c in b if c.isalnum()).lower() # 영문자 or 숫자인 경우 소문자로 변환 # a의 key 모음과 b의 key 모음이 같고 value도 같은지 판별. (== 연산자의 역할) return Counter(a) == Counter(b)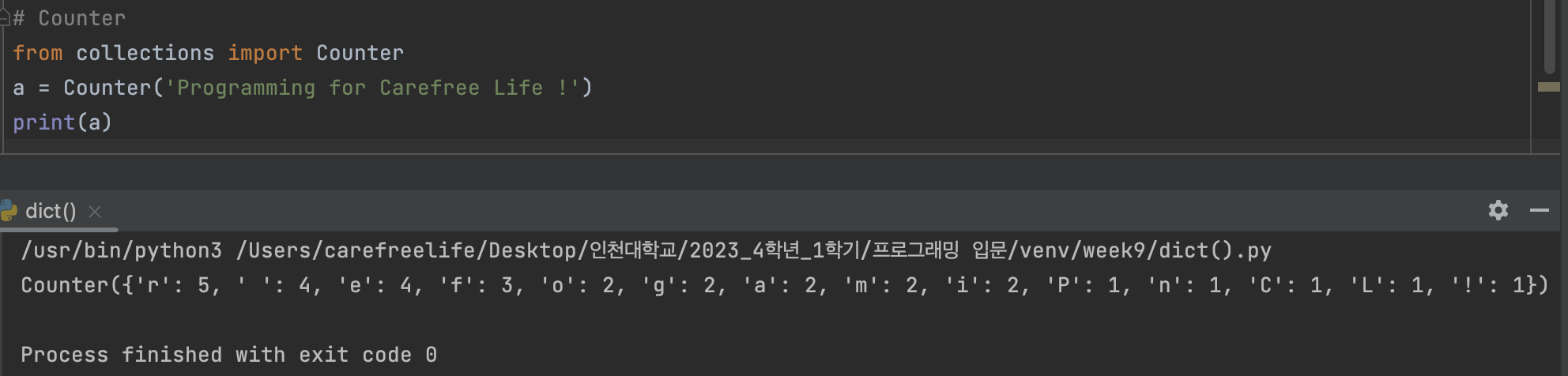
실행 결과
-
ASCII 코드 및 연산
아스키 (ASCII) 코드란 ?
ASCII
- 미국 정보 교환 표준 부호 (American Standard Code for Information Interchange)
- ASCII( /ˈæski/, 아스키)는 영문 알파벳을 사용하는 대표적인 문자 인코딩이다.
- 아스키는 컴퓨터와 통신 장비를 비롯한 문자를 사용하는 많은 장치에서 사용되며, 대부분의 문자 인코딩이 아스키에 기초를 두고 있다.
- 아스키는 7비트 인코딩 으로, 33개의 출력 불가능한 제어 문자들과 공백을 비롯한 95개의 출력 가능한 문자들, 총 128개로 이루어진다. (7비트 인코딩이므로 2^7 = 128개)
- 출력 가능한 문자들은 52개의 영문 알파벳 대소문자와, 10개의 숫자, 32개의 특수 문자, 그리고 하나의 공백 문자로 이루어진다.
제어 문자들은 역사적인 이유로 남아 있으며 대부분은 더 이상 사용되지 않는다.
- [참고] 유니코드(영어: Unicode)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이다
출처:위키백과

ASCII 문자와 숫자 간의 변환: ord() & chr()
ord() # 문자를 아스키 코드(숫자)로 변환.
chr() # 아스키 코드(숫자)를 해당하는 문자로 변환.
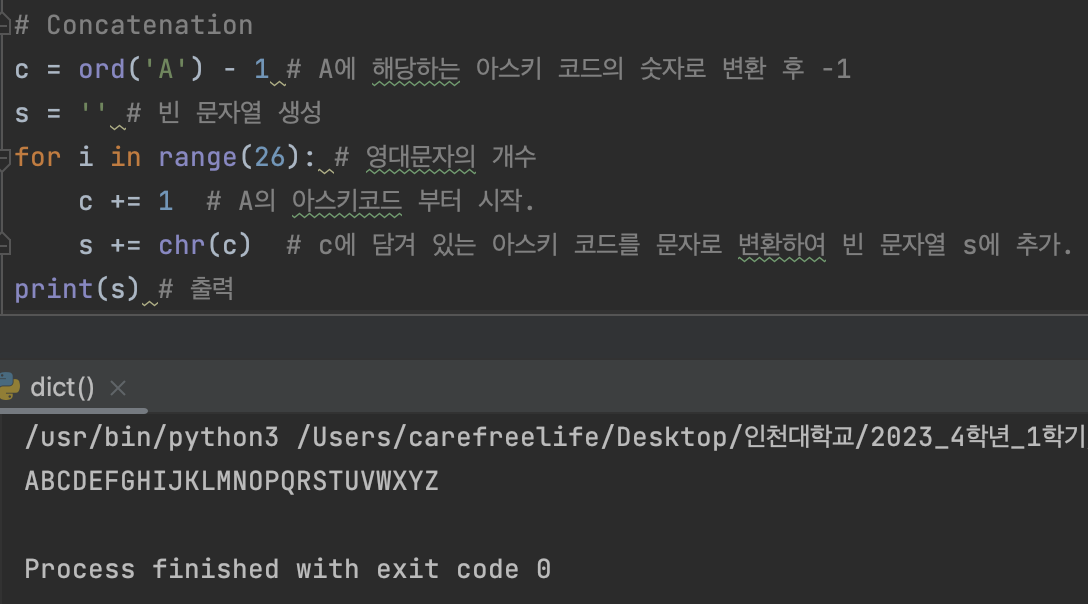
# 문자열 접합 (concatenation) 프로그램
c = ord('A') - 1 # A에 해당하는 아스키 코드의 숫자로 변환 후 -1
s = '' # 빈 문자열 생성
for i in range(26): # 영대문자의 개수
c += 1 # A의 아스키코드 부터 시작.
s += chr(c) # c에 담겨 있는 아스키 코드를 문자로 변환하여 빈 문자열 s에 추가.
print(s) # 출력
실행 결과
Python 에서의 재귀 함수 (Recursion)
- 재귀 함수 (Recursion) :
- 함수의 정의 내에 자기 자신의 함수가 포함 되어있는 함수.
- 함수의 동작 과정에서 자기 자신의 함수가 호출된다.
- 반복적인 작업을 구현할 수 있다.
- 함수가 호출 될수록 자신이 돌아가야 할 곳의 위치를 기억해야 한다.
- 재귀 함수의 호출 수에 비례하여 메모리 사용량이 커진다.
- 함수의 정의 내에 자기 자신의 함수가 포함 되어있는 함수.
- 순환문 과의 비교
-
# 순환문으로 구현된 함수 import time def countdown(n): while n > 0: print(n) time.sleep(1) n = n - 1 print("fire!") -
# 재귀 함수로 구현된 함수 import time def countdown(n): if n > 0: print(n) time.sleep(1) countdown(n-1) # 자신의 정의 내에서 자기 자신의 호출. else: print("fire!") - 모든 순환문은 재귀 함수로 구현이 가능하다.
-
재귀 함수 활용의 예 : sigma 함수
- sigma(n) : 1부터 n까지 모든 자연수의 합을 계산.
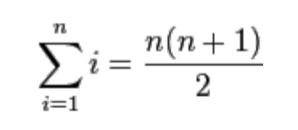
Sigma 함수의 정의- sigma(5) = 15
- sigma(0) = 0
- sigma(-3) = 0
- 재귀로 구현된 표현
- 재귀 함수를 사용하려면 필수적으로 존재해야 하는 조건이 있다.
- 반복 조건 (귀납 조건)
- 조건문 등을 사용하여 반복 조건을 만들어 준 후 재귀 호출.
- 재귀 호출 (Recursive Call)
- 자기 자신(함수)를 다른 파라미터를 삽입하여 호출.
- 종료 조건 (기초 조건)
- 적당한 조건을 통해 재귀 함수의 종료가 발생하지 않으면 무한 LOOP 발생.
- 반복 조건 (귀납 조건)

재귀 함수의 필수 조건
- 재귀 함수를 사용하려면 필수적으로 존재해야 하는 조건이 있다.
재귀 함수를 사용하여 문제 해결하기
- 주어진 문제를 “점화식”으로 변환한다 (어려울 수 있다.)
- 점화식을 표현할 때 자신을 호출하는 조건이 작성되어야 한다.
- 해당 점화식을 그대로 함수로 변환하여 작성한다.
점화식으로 표현된 재귀 함수
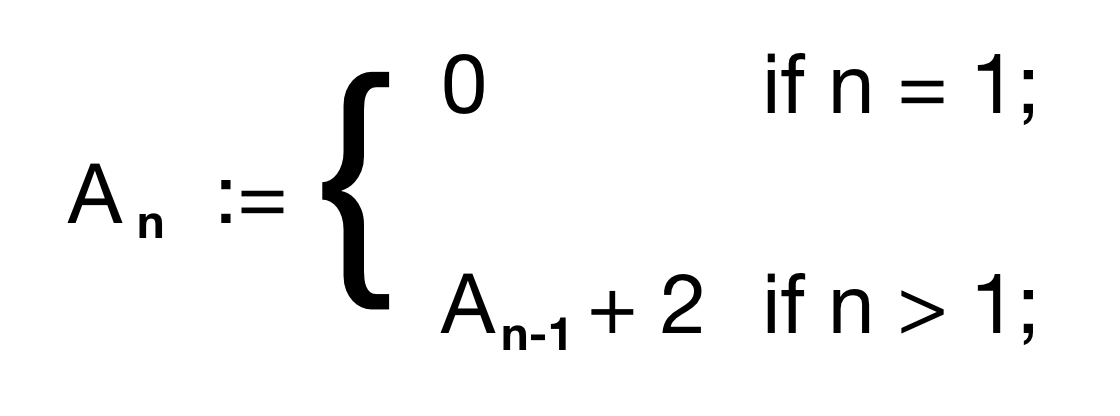
꼬리 재귀 함수 (Tail Recursion)
- 꼬리 재귀 (Tail Recursion)
- 재귀 호출 할 때 더 이상 기억해 줄 것이 없도록 한다.
- 즉, 재귀 호출의 끝에 도달하여 도출된 결과를 가지고 roll back하며 계산할 것이 남아 있지 않는다.
- 기존 재귀 함수에 비해 순환 횟수와 관련없는 작은 저장 공간만 필요로 한다.
- 꼬리 재귀 함수 만드는 방법
- 일반 재귀 함수를 구현.
- 각 순환마다의 결과 값을 누적하는 추가적인 함수를 구현하여 해당 함수를 반환.
- 추가적인 함수는 인자로 입력값과 누적 결과 값을 받음. (n, 0)
- 매 순환마다의 결과 값을 누적할 추가적인 함수 정의.
- 필요한 계산(덧셈)을 미리 한 후 해당 결과 값을 추가 인수로 들고 다니도록 한다.
- 재귀 호출 할 때 더 이상 기억해 줄 것이 없도록 한다.
# 꼬리 재귀 함수의 구현
def sigma1(n):
return loop(n, 0) # 카운터는 n 부터, 누적 결과값은 0 부터 시작.
# 중간 계산 결과를 전달하기 위한 보조함수 loop
def loop(n, sum): # loop(카운터, 누적 결과 값)
if n > 0:
# loop 호출 시 카운터 1감소, sum에 각 호출마다의 결과 값 갱신(합)
return loop(n - 1, n + sum)
else:
return sum
꼬리 재귀 함수의 분석
- 시간적 측면
- 답을 구하는데 걸리는 계산 시간: 재귀 호출 하는 횟수와 비례한다.
- 인수가 n이면 재귀 호출은 총 n+1번 이므로, 계산 시간은 인수 n에 비례
- 공간적 측면
- 필요 공간: 재귀 호출 횟수에 관계없이 일정하다.
일반 재귀 VS 꼬리 재귀
- 일반 재귀 함수:
- 할 수 있다면 점화식으로 표현
- 결과 도출까지의 순환 과정을 되짚어 가며 최종 결과를 도출
- 비효율적인 메모리 사용
- 꼬리 재귀 함수:
- 각 순환마다의 결과 값을 추가 인수에 계속 갱신하며 최종 결과 값을 도출.
- 마지막 순환 실행 후 추가 인수에 갱신되어온 최종 결과 값을 반환.
- 일반 재귀 함수와 달리 매 순환 마다의 결과 값이 저장된 위치 기억용 메모리를 사용하지 않음.
- 공간 비효율의 향상
- 일반 재귀 함수는 대부분 꼬리 재귀 함수로 변환이 가능하다.
점화식 ---변환---> 일반 재귀 함수 ---변환---> 꼬리 재귀 함수
꼬리 재귀 VS 반복문
꼬리 재귀 함수에서 반복문으로 변환하는 것도 쉽다.
# 꼬리 재귀 함수
def sigma1(n):
def loop(n, sum):
if n > 0: #(2)
return loop(n - 1, n + sum) #(3)
else:
return sum #(4)
return loop(n, 0) #(1)
# 반복문
def sigma2(n):
sum = 0 #(1)
while n > 0: #(2)
sum = n + sum #(3)
n = n - 1 #(3)
return sum #(4)
프로그래밍의 철학은 재귀로부터 시작하여 꼬리 재귀를 거쳐 반복문 순서로 만드는 것이다.
문자열 치환 프로그램
- 사전 자료형을 사용하지 않고 영문자 a부터 z까지를 1~26으로, A부터 Z까지를 27~52로 변환.
- 변환된 정수 값을 반환해주는 함수 convertCharacter1(c) 작성
문자열 치환 프로그램 소스 코드 보기 (클릭)
# 10_1_1. 문자열 치환
# 사전 자료형을 사용하지 않고 영문자 a부터 z까지를 1~26으로, A부터 Z까지를 27~52로 변환.
# 변환된 정수 값을 반환해주는 함수 convertCharacter1(c) 작성
def convertCharacter1(c):
try:
if (65 <= ord(c) <= 90) or (97 <= ord(c) <= 122):
# 대문자
if ord(c) <= 90:
# 대문자의 아스키 코드는 65(A) ~
return ord(c) - 38
# 소문자
else:
# 소문자 a의 아스키 코드는 97(a) ~
return ord(c) - 96
except:
print('잘못된 입력입니다.')
# 메인 함수
x = ''
while x != '=':
x = str(input('소문자 a 부터 대문자 Z중 하나를 입력하시오: '))
print(convertCharacter1(x))
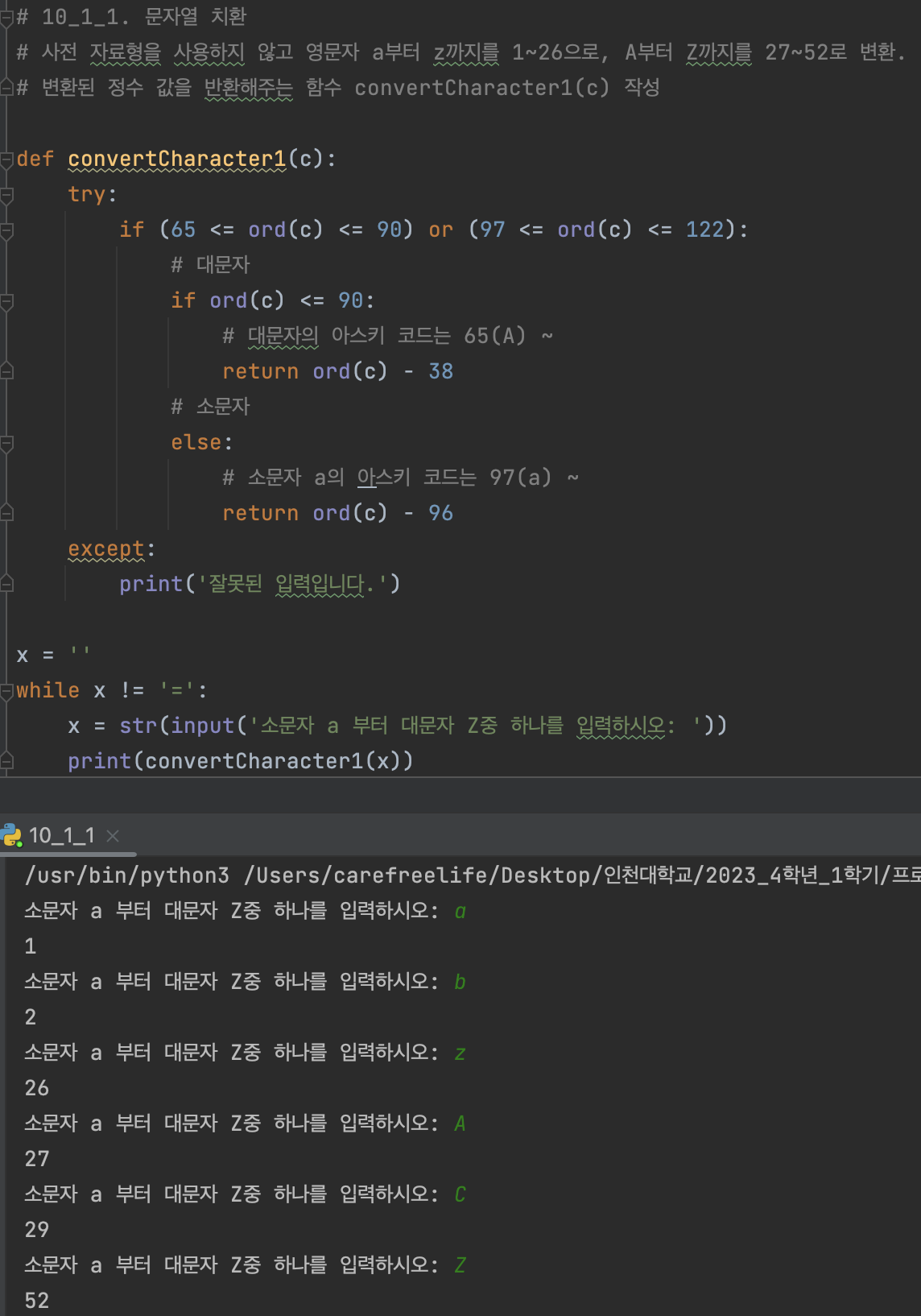
문자열 치환 프로그램 실행 결과
카이사르(Caesar) 암호화 프로그램 제작
- 영문 소문자로 이루어진 문자열 m과 26이하의 자연수 k를 입력 받는다. (영소문자의 개수 : 26개)
- 평문에 있는 문자를 차례대로 하나씩 k번째 뒤의 문자로 변환하여 암호문 작성.
- 영문 소문자로 이루어진 문자열과 k 값을 입력 받아 암호문으로 변환하는 프로그램 작성.
- 문자열의 각 문자에 대응하는 ASCII코드 + k 의 ASSCII 코드로 문자열의 전체 문자 변환
- 암호화 전 기존 문자열로 변환하는 복호화 함수 작성.
입력: 평문과 26이하의 자연수 출력: 암호문
Words
평문 (Plain Text) : 암호화 되지 않은 Original Text
암호문 (Cipher Text) : 암호화된 Text
암호화 (Cipher) : 평문을 암호문으로 만드는 것
복호화 (Decipher) : 암호문을 평문으로 만드는 것
(2) 소스 코드 보기 (클릭)
# 10_1_2. 시저 암호화 및 복호화 함수 작성
# 영문 소문자로 이루어진 문자열과 k 값을 입력 받아 암호문으로 변환하는 프로그램 작성.
# 문자열의 각 문자에 대응하는 ASCII코드 + k 의 ASSCII 코드로 문자열의 전체 문자를 변환.
# 암호화 전 기존 문자열로 변환하는 복호화 함수 작성.
# 시저 암호화 함수
def cipher(string, k):
# 암호화 된 문자열이 저장될 빈 문자열 rs 생성
rs = ''
try:
# string 이 문자열 인지, k 의 범위가 맞는지 검사
if (str(type(string)) == "<class 'str'>") and (1 <= k <= 26):
# 문자열 내 전체 문자 검사
for char in string:
# 기존 문자의 아스키 코드 + k 된 아스키 코드를 구한다.
# 해당 아스키 코드에 대응하는 문자로 변환하여 빈 문자열 rs에 저장.
rs += chr(ord(char) + k)
return rs
except:
print('잘못된 입력입니다.')
# 복호화 함수
def decipher(string, k):
# 복호화 된 문자열이 저장될 빈 문자열 rs 생성
rs = ''
try:
# string 이 문자열 인지, k 의 범위가 맞는지 검사
if (str(type(string)) == "<class 'str'>") and (1 <= k <= 26):
# 문자열 내 전체 문자 검사
for char in string:
# 암호화 된 문자의 아스키 코드 - k 된 아스키 코드를 구한다.
# 해당 아스키 코드에 대응하는 문자로 변환하여 빈 문자열 rs에 저장.
rs += chr(ord(char) - k)
return rs
except:
print('잘못된 입력입니다.')
# 메인 함수
m = ''
while m != '=':
m = str(input('문자열 입력: '))
k = int(input('1~26 사이의 정수 k 입력: '))
# 암호화
cip = cipher(m, k)
print('시저 암호화 된 문자열:', '[' + cip + ']')
print('복호화 된 문자열:', '[' + decipher(cip, k) + ']')
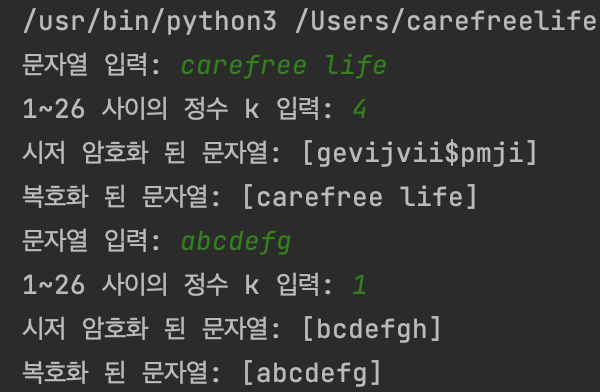
카이사르(Caesar) 암호화 프로그램 실행 결과
순열 (Permutation) 출력 함수
- 주어진 입력 문자열에 대해서 모든 가능한 순열을 출력해주는 함수
- 단, 입력 문자열에서 중복되는 문자는 없다고 가정.
순열 (Permutation) 출력 함수 소스 코드 (클릭)
# 알고리즘
# 문자열 길이 중 각 자리에 어떤 것이 출력될지 결정하여 출력
# 끝까지(n-1까지) 결정이 되었으면 마지막 자리에는 n만큼 넣은 후 출력. (종료 조건)
# a == 입력 문자열
# n == 입력 문자열의 길이
# i == 현재 자리
def perm(a, i, n):
if i == n-1:
for i in range(n):
print(a[i], end='')
print(end='\n')
else:
for j in range(i, n):
a[i], a[j] = a[j], a[i]
perm(a, i+1, n)
a[i], a[j] = a[j], a[i]
string = input('문자열 입력: ')
length = len(string)
listed = list(string)
perm(listed, 0, length)
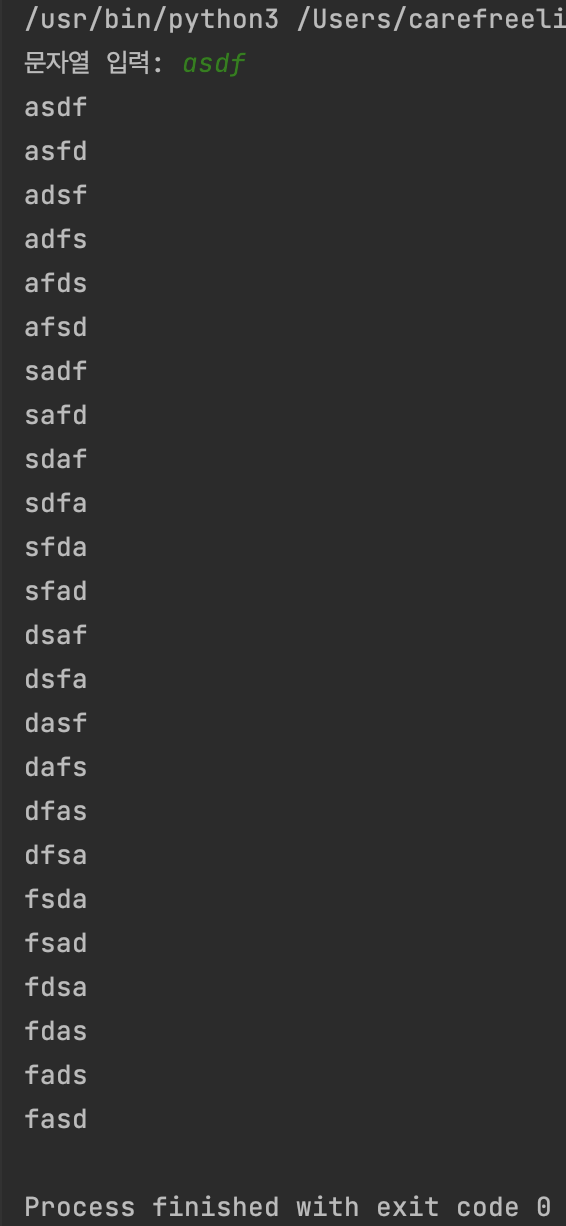
순열 출력 프로그램 실행 결과
어구전철 관계 여부 판별 프로그램
- 두 개의 문자열을 입력 받아
어구전철 관계 여부를 판별하는 프로그램.
- V1 : list의 내장 메소드인 sort() 함수 사용하여 구현.
어구전철 V1(sort) 소스 코드 (클릭)
# 10_2_1. 어구전철(Anagram) 여부 확인 함수(1)
# - 두 개의 문자열을 입력 받아 어구전철인지 여부를 출력하는 프로그램 작성
# - V1) list의 내장 메소드 "sort" 사용
def is_anagram_v1(str1, str2):
x = str1
y = str2
if len(x) == len(y):
x = ''.join(c for c in x if c.isalnum()).lower()
y = ''.join(c for c in y if c.isalnum()).lower()
x = list(x)
x.sort()
y = list(y)
y.sort()
for i in range(len(x)):
if x[i] == y[i]:
i += 1
else:
return False
break
return True
a = input('첫 번째 문자열 입력: ')
b = input('두 번째 문자열 입력: ')
if is_anagram_v1(a, b):
print('어구전철 입니다.')
else:
print('어구전철이 아닙니다.')
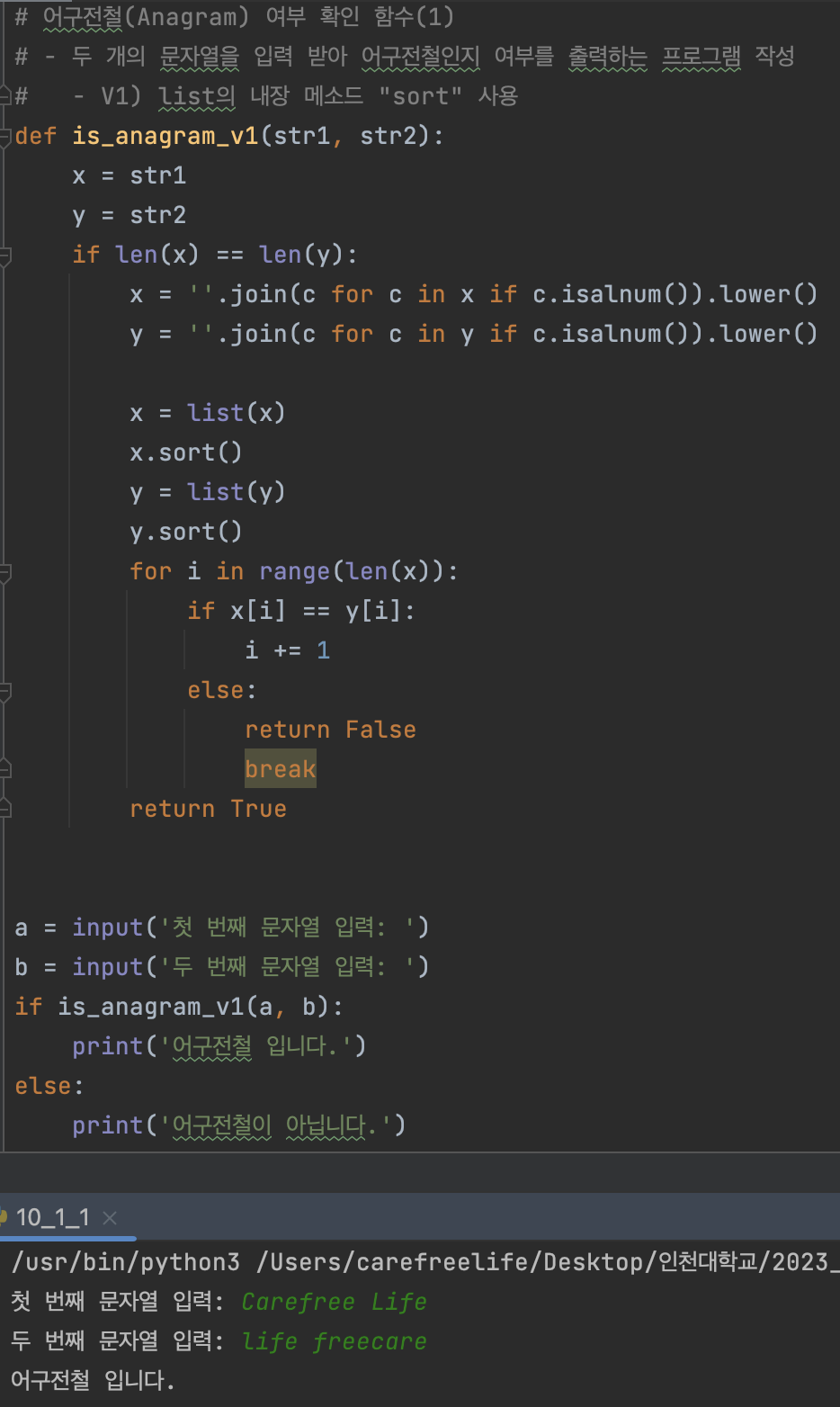
V1 실행 결과
- 두 개의 문자열을 입력 받아
어구전철 관계 여부를 판별하는 프로그램.
- V2 : Counter 모듈 사용하여 구현.
어구전철 V2(Counter) 소스 코드 (클릭)
# 10_2_1. 어구전철(Anagram) 여부 확인 함수(2)
# - 두 개의 문자열을 입력 받아 어구전철인지 여부를 출력하는 프로그램 작성
# - V2) Counter 모듈 사용
def is_anagram_v2(str1, str2):
from collections import Counter
a = Counter(str1).copy()
b = Counter(str2).copy()
print(a.items())
print(b.items())
if a.items() == b.items():
return True
else:
return False
a = str(input('문자열 A 입력: '))
b = str(input('문자열 B 입력: '))
if is_anagram_v2(a, b):
print('어구 전철 입니다.')
else:
print('어구 전철이 아닙니다.')
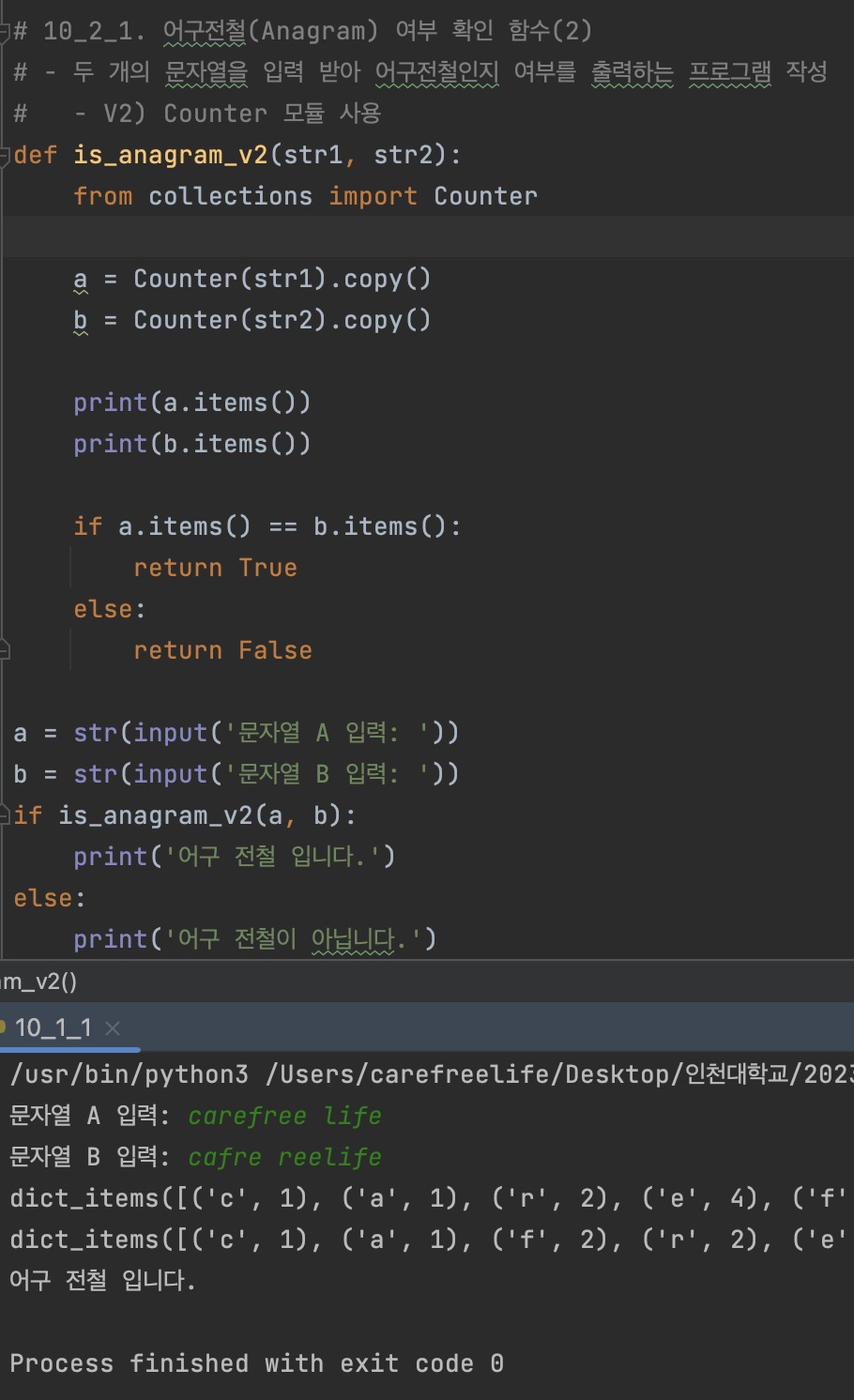
V2 실행 결과
- V3 : 재귀 함수 사용(Recursion) - 재귀 함수에 대해 더 자세히 알고 싶다면?
순환(Recursion) - 클릭! 
입출력 예시 화면
최대한의 설명을 코드 블럭 내의 주석으로 달아 놓았습니다.
혹시 이해가 안가거나 추가적인 설명이 필요한 부분, 오류 등의 피드백은 언제든지 환영합니다!
긴 글 읽어주셔서 감사합니다. 포스팅을 마칩니다.
Task Lists
- 사전 자료형 (Dictionary)
- 사전 자료형의 자료 존재 여부 검사
- 사전 자료형 관련 내장 메소드
- Conter의 동작 원리
- ASCII 코드 및 연산
- ASCII 문자와 숫자 간의 변환: ord() & chr()
- Python 에서의 재귀 함수 (Recursion)
- 재귀 함수 활용의 예 : sigma 함수
- 재귀 함수를 사용하여 문제 해결하기
- 꼬리 재귀 함수 (Tail Recursion)
- 일반 재귀 VS 꼬리 재귀
- 꼬리 재귀 VS 반복문
- 카이사르(Caesar) 암호화 프로그램 제작
- 순열 (Permutation) 출력 프로그램 제작
- 어구전철 관계 여부 판별 프로그램 V1, V2, V3 제작



Comments